导读
我们在做一次系统业务模型重构的时候,往往会遇到把旧模型表中的数据迁移到新模型表中,如果这时候,我们旧表中的数据规模已达到千万级以上,那么,这个从旧表迁移到新表的过程会非常漫长,而业务仍需快速推进,业务方接受不了这么高的迁移成本,此时,开发同学就会想:既然业务不允许停滞,但是,又不得不将大规模的数据迁移新模型表中。那么,为了保证对业务影响最小,更快完成数据迁移,一批插入多少条记录到新表的效率最高呢?
今天,我就以用户中心这个系统中的用户表为例,详细讲解一下一条Insert语句的插入过程,从而找出影响一条记录插入性能的因素,最后,回答一批插入多少条记录到新表效率最高?
插入过程
假设我们使用的用户表结构如下:
CREATE TABLE `user` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`user_id` int(8) DEFAULT NULL COMMENT '用户id',`user_name` varchar(29) DEFAULT NULL COMMENT '用户名',`user_introduction` varchar(498) DEFAULT NULL COMMENT '用户介绍',`sex` tinyint(1) DEFAULT NULL COMMENT '性别',`age` int(3) DEFAULT NULL COMMENT '年龄',`birthday` date DEFAULT NULL COMMENT '生日',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
现在,假设这张表是我们的新用户模型表,然后,我们要将旧模型表中的的3000w条用户记录插入新模型表,采用分批插入的方式,即一次8000条,那么,这个插入的过程如下:

图中,为了重点描述插入记录的过程,所以,我只插入了4条记录:
< 1, 10001, Jack, …>
< 2, 10002, Nancy, …>
< 3, 10003, Jack, …>
< 4, 10004, John, …>
这4条记录的插入过程大致如下:
- 将4条记录的插入操作和相应的删除操作写入Undo Log。
- 将4条记录的插入操作写入Redo Log。
- 将4条记录写入Bin Log(行模式)。
- 读取redo log,将4条记录写入索引和数据文件Data File。
其中,由于写入上面undo log、redo log、bin log和data file这4个文件,除了data file是异步写,其他3个都是同步写,且都为磁盘写,势必影响插入记录的性能,所以,MySQL针对这3个文件的同步写做了一系列优化,保证插入记录的性能。
现在我就从性能优化的角度,讲解一下MySQL是如何优化这3个文件的写入的?讲解完后,我将回答本章标题的问题:一批插入多少条记录到新表的效率最高呢?
-
Undo Log
对MySQL事务有一定了解的同学,应该知道MySQL的事务回滚就依赖这个log文件,所以,关于undo log的内容,我会在《我的事务执行好慢,怎么办?》中详细讲解。 -
Redo Log
关于redo log,你可能会问:MySQL为什么要记录这个log?
从数据可靠性来看,以上面的插入记录为例,如果没有第2步,MySQL执行到第4步,此时,刚好完成第1和2条记录插入,插入第3条记录时,MySQL宕机了,那么,将导致第3和4条记录丢失,所以,MySQL为了保证在重启机器时,能够再将3和4两条记录重新插入表中,将4条记录的插入操作全部写入redo log,那么,在重启机器后,MySQL就能从redo log中找到3和4两条记录,将这两条记录重新插入表中。
结构
现在,我们再来看一下redo log的结构:

redo log由多组文件组成,每组对应一个文件,每个文件大小一致。其中,文件以ib_logfile[number]命名。如上图,有4组文件,ib_logfile1到ib_logfile4。同时,ib_logfile有如下特点:
- 每个ib_logfile文件存的是记录的操作信息。
- ib_logfile之间是循环依赖,如上图,在所有文件写满后,新的操作信息重新写入第一个ib_logfile。
一共有多少个组,以及每个文件大小多大,可以通过参数配置。主要参数如下:
innodb_log_files_in_group:分几个组。
innodb_log_file_size:每组对应的文件的大小。
所以,redo log的总大小 = innodb_log_files_in_group * innodb_log_file_size
写入
我以上面插入4条记录为例,讲解一下redo log的写入过程:

我以船运货来模拟这个写入的过程,主要包含4个步骤:
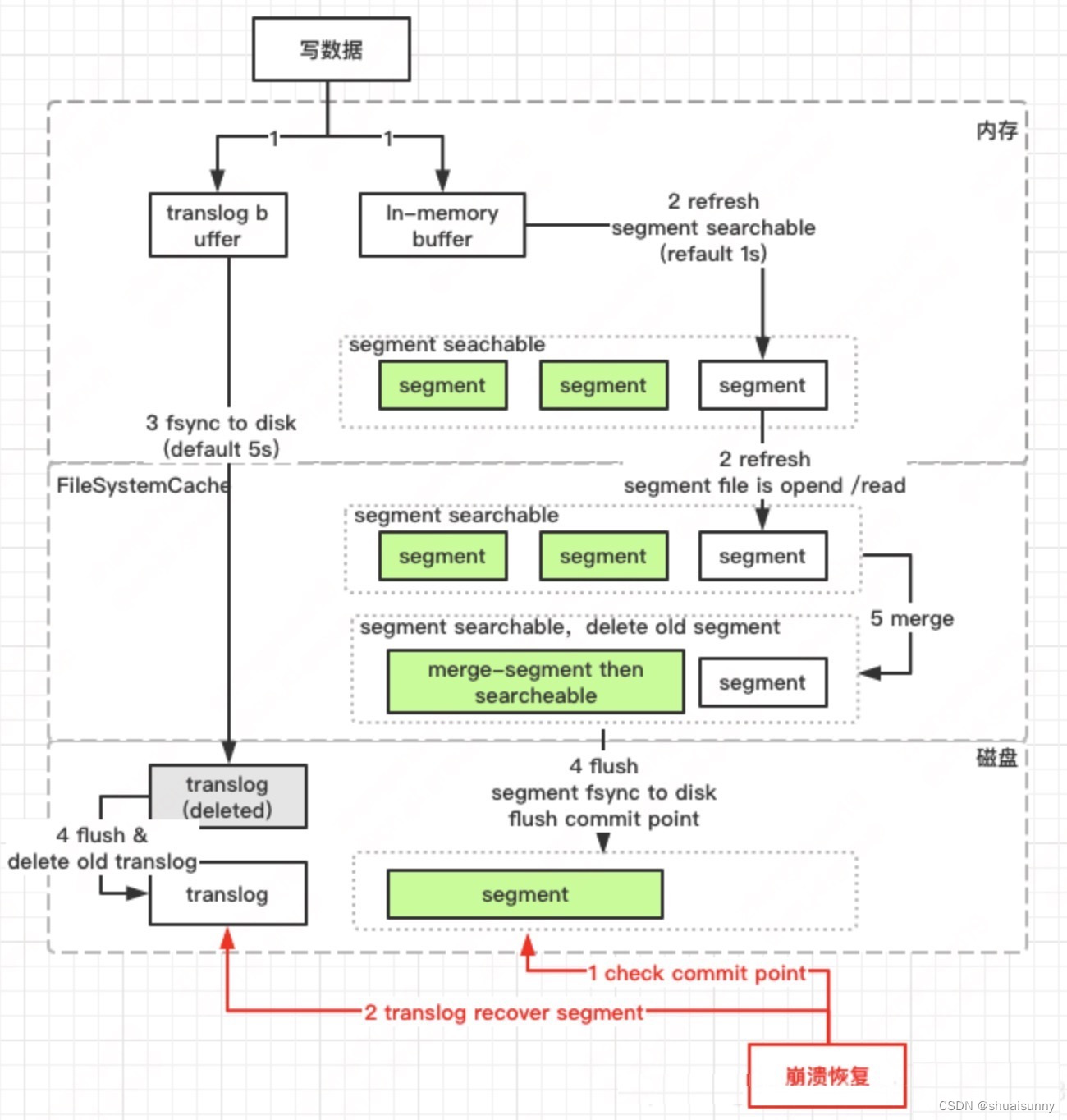
- 将4条记录的插入操作写入缓冲区buffer,如上图(1)中的黄色小方块为这4条记录的插入操作组成的一组。图中最左边的码头代表buffer。
- 如果buffer满了,从buffer中读取已有的操作,开始IO总线传输这些操作,准备把它们写入redo log文件。如上图(1),绿色小方块代表buffer中已有的操作,表示buffer满了,见图(2),小船运输绿色小方块代表IO总线传输。再执行步骤1,将4条记录的插入操作写入buffer。如图(2)中黄色小方块放到最左边的码头。
- 将buffer中已有的操作写入redo log文件。如上图(3),中间的码头代表redo log文件,绿色小方块准备放到该码头上。
- 如果redo log文件满了,MySQL会执行我在《导读》中的那张图中写redo log之后的动作,将文件中的操作的记录刷到数据文件中。如上图(3),粉色小方块代表redo log中的操作,表示redo log满了,见图(4),小船运输粉色小方块到最右边的码头,最右边的码头代表数据文件。再执行步骤3,结合上面讲到的redo log的结构,从第一个文件ib_logfile1开始写4条记录的插入操作。如图(4)中绿色小方块放到中间的码头。
这里,其实是有问题的:如果缓冲区buffer写入成功,但是,之后写入redo log失败,那么,4条记录的操作将全部丢失。
所以,MySQL为了保证buffer和redo log文件的一致性,引入mtr的概念,全称Mini-Transaction,将buffer和redo log操作封装在一个mtr中,这样,就能保证buffer和redo log的写入要么都成功,要么都失败,如果失败的话,记录仍旧保留,可继续写buffer。
关于mtr的详细内容,我将在《MySQL是如何平衡日志写入的性能和数据可靠性的?》讲解。
从上面写入redo log的过程中,我们发现由于MySQL在写redo log文件前,先写buffer,而写buffer是一个内存操作,所以,同步写的性能就有了保障。
这里还有一个问题:插入操作时,如果MySQL每次都是等redo log写满,再将log中的所有内容刷到数据文件,那么,redolog很大的话,这样,刷数据文件的性能会很差。那怎么解决呢?
我们看下面这张图:

MySQL引入了checkpoint的概念,由一个线程定时推进redo log的某个位置,这个位置就叫checkpoint,该位置之前的内容,即图中write position到checkpoint之间的内容,会由另一个线程刷到数据文件。这样,就避免大量的数据刷到数据文件,从而影响插入的性能。ps:MySQL会在write position到checkpoint之间的大小超过redo log总大小的76%就会提前触发刷数据文件的行为。
Bin Log
初步了解MySQL的同学一定知道binlog,它记录了每一条SQL的操作,MySQL主从实例之间的同步就是依靠它来实现的。那么,这里对比redo log,你可能会有一个疑问:redo log用来记录记录操作行为的,bin log也是记录记录操作的,那么,为什么有redo log,还需要bin log?
主要基于两点原因:
- redo log是InnoDB特有的日志,其他存储引擎没有这样的日志。而bin log是所有存储引擎都支持的日志。
- redo log是固定大小不变的。而bin log是可以不断追加的。如果用redo log来同步记录到从库上,如果出现从库还未拉取redo log上的一些操作,redo log里的这些操作因为日志写满,导致相应操作的记录被刷到数据文件,那么,redo log上针对这些操作的记录将丢失,记录无法同步到从库。
参数配置
现在回到本章标题的那个问题:一批插入多少条记录到新表的效率最高呢?
从本章《插入过程》这一部分中,我们知道,在真正插入记录到数据文件前,会经过3个日志文件的写入:undo log、redo log和bin log,可见,3个日志文件的写入性能是影响整个记录插入性能的关键。
由于undo log和bin log都是可以不断追加的,同时,两者都是顺序写文件,所以,在批量插入记录的时候写这两个文件在性能上不会有太大的影响。
而redo log是有固定大小的,采用的是循环写,所以,批量插入记录的操作,在所有redo log写满后,把redo log中的操作对应的记录刷到数据文件后,会重新从第一个ib_logfile中写记录的批量插入操作,这是一个随机IO,会影响批量插入的性能。
所以,为了不影响批量插入记录的性能,我们可以调整redo log的总大小,即我在讲解redolog结构的时候提到的两个参数:innodb_log_files_in_group和innodb_log_file_size,保证一次批量插入的记录大小小于等于innodb_log_files_in_group * innodb_log_file_size,这样,我们就能减少redo log的随机IO,保证批量插入的性能。
比如:我现在一次批量插入的记录大小为800M,那么,我就要调整innodb_log_files_in_group=10,innodb_log_file_size=80M
具体调整方法如下:
- 打开my.cnf配置文件
- 设置innodb_log_files_in_group=10
- 设置innodb_log_file_size=80M
- 重启MySQL
通过上面的参数调整,我们就能保证一次批量插入大量的记录的效率是最高的。
小结
在本章节中,我以一次批量插入大量记录的例子为引线,讲解了Insert批量插入记录的过程,最后,由这个过程分别引出3个日志:undo log、redo log和bin log。重点讲解了redo log。
最后通过redo log的分析,回答了一批插入多少条记录到新表的效率最高呢?这个问题。
希望你在这篇文章中有所收获!