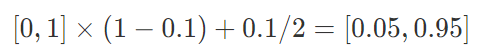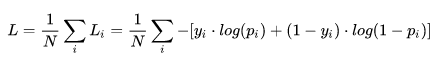目的:
label smoothing常用于分类任务,防止模型在训练中过拟合,提高模型的泛化能力。
意义:
对于分类问题,我们通常使用one-hot编码,“非黑即白”,标签向量的目标类别概率为1,非目标类别概率为0:
神经网络在分类任务中会输出当前输入对应每个类别的置信度分数,通过softmax对这些分数进行归一化处理,最终可以得到当前输入数据对应每一个类别的概率。
然后计算交叉熵损失函数:
这就会导致真实标签与其他标签之间的关系被忽略,模型无法学到更多的东西;这样训练得到的模型泛化能力会很差;处理样本相似度较高、数据噪声较大的数据集等分类问题时,模型容易受到影响。
针对这些问题,研究学者提出了label smoothing方法。
label smoothig(标签平滑):
label smoothing的提出很好的解决了上述问题,主要是通过减少实际样本标签的类别在计算损失函数时的权重,来抑制过拟合问题。
增加标签平滑后的概率分布就变为:
交叉熵损失函数就变为:
优缺点:
label smoothing优点:
一定程度上缓解了模型过于绝对的问题(‘非黑即白’);
增强了模型的泛化能力;
体现了训练数据中类别之间的亲疏关系。
label smoothing缺点:
随机噪声的添加并不能完全反映label之间的关系,甚至会导致模型欠拟合。
参考文献:
C. -B. Zhang et al. , Delving Deep Into Label Smoothing.
代码实现:
import torch.nn.functional as Fdef linear_combination(x, y, epsilon):return epsilon * x + (1 - epsilon) * ydef reduce_loss(loss, reduction='mean'):return loss.mean() if reduction == 'mean' else loss.sum() if reduction == 'sum' else lossclass LabelSmoothingCrossEntropy(nn.Module):def __init__(self, epsilon: float = 0.1, reduction='mean'):super().__init__()self.epsilon = epsilonself.reduction = reductiondef forward(self, preds, target):n = preds.size()[-1]log_preds = F.log_softmax(preds, dim=-1)loss = reduce_loss(-log_preds.sum(dim=-1), self.reduction)nll = F.nll_loss(log_preds, target, reduction=self.reduction)return linear_combination(loss / n, nll, self.epsilon)