前言

OceanBase 已连续 9 年稳定支撑双 11,创新推出“三地五中心”城市级容灾新标准,在被誉为“数据库世界杯”的 TPC-C 和 TPC-H 测试上都刷新了世界纪录。自研一体化架构,兼顾分布式架构的扩展性与集中式架构的性能优势,用一套引擎同时支持 OLTP 和 OLAP 的混合负载,具备数据强一致、高扩展、高可用、高性价比、高度兼容 Oracle/MySQL、稳定可靠等特征,不断用技术降低企业使用数据库的门槛。现已助力金融、政府、运营商、零售、互联网等多个行业的客户实现核心系统升级。
一、数据迁移
数据迁移是日常运维操作的一种常见操作,是调整集群负载和机房搬迁的必备操作。虽然集群内部、表与表之间数据归档、磁盘水位均衡、资源单元搬迁等操作在 OceanBase 数据库中可以通过简单命令快速发起,但是涉及异构数据源和集群间的数据同步等功能时就需要借助外部工具。
1.使用 SQL 脚本迁移
(2)介绍说明
使用SQL脚本主要还是针对表与表之前的数据迁移,这里重点就是表对表
表与表之间可以通过
INSERT INTO......SELECT
语句实现数据同步。
(2)举例说明:
如果我们想要把A表数据插入B表中的话,代码如下:
INSERT INTO table_B
SELECT col1,col2 from table_A
WHERE [expr];(3)资源单元迁移
#启动资源单元的迁移
ALTER SYSTEM MIGRATE
UNIT = [unit_id] DESTINATION = [ip_port]
#取消资源单元的迁移
obclient> ALTER SYSTEM CANCEL MIGRATE UNIT unit_id;2.使用 mysqldump 迁移

(1)介绍说明
mysqldump 是 MySQL 提供的用于导出 MySQL 数据库对象和数据的工具,非常方便。OceanBase 数据库兼容 MySQL 协议,您可以使用 mysqldump 对 OceanBase 数据库中的数据进行备份。mysqldump 是 MySQL 自带的逻辑备份工具。它的备份原理是通过协议连接到数据库后,将需要备份的数据查询出来,并将查询出的数据转换成对应的 INSERT 语句。
(2)参数说明
| 参数 | 说明 |
|---|---|
| –host(-h) | 服务器 IP 地址。 |
| –port(-P) | 服务器端口号。 |
| –user(-u) | MySQL 用户名。 |
| –pasword(-p) | MySQL 密码。 |
| -d | 仅导出表结构不导出数据。 |
| –databases | 指定要备份的数据库。 |
| –all-databases | 备份所有数据库,不建议使用,建议单独指定。 |
| –compact | 压缩模式,产生更少的输出。 |
| –comments | 添加注释信息。 |
| –complete-insert | 输出完成的插入语句。 |
| –force | 忽略错误。 |
| –skip-triggers | OceanBase 数据库目前不支持 trigger 语法,所以如果不指定 --force 参数时必须要加上该参数,否则无法导出。 |
| –skip-extended-insert | 导出语句为多条 INSERT 格式,否则为 INSERT INTO table VALUES(…),(…), 格式。 |
(3)使用 mysqldump 迁移 MySQL 表到 OceanBase
mysqldump -h 127.1 -u**** -P3306 -p**1*** -d TPCH --compact > tpch_ddl.sql
/*!40101 SET character_set_client = @saved_cs_client */;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `NATION` (`N_NATIONKEY` int(11) NOT NULL,`N_NAME` char(25) COLLATE utf8_unicode_ci NOT NULL,`N_REGIONKEY` int(11) NOT NULL,`N_COMMENT` varchar(152) COLLATE utf8_unicode_ci DEFAULT NULL,PRIMARY KEY (`N_NATIONKEY`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci MAX_ROWS=4294967295;MySQL [oceanbase]> set global foreign_key_checks=off;
Query OK, 0 rows affectedMySQL [oceanbase]> show global variables like '%foreign%';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| foreign_key_checks | OFF |
+--------------------+-------+
1 row in set(4)导出指定数据库的表数据
mysqldump -h 127.1 -u**** -P3306 -p**1*** -t TPCH > tpch_data.sql
mysqldump 导出的数据初始化 SQL 里会首先将表锁住,禁止其他会话写。然后使用 insert 写入数据。每个 insert 后面的 value 里会有很多值。这是批量 insert。
LOCK TABLES `t1` WRITE;
/*!40000 ALTER TABLE `t1` DISABLE KEYS */;
INSERT INTO `t1` VALUES ('a'),('中');
/*!40000 ALTER TABLE `t1` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
3.使用 DataX 迁移
(1)介绍说明
DataX 是阿里巴巴集团内部广泛使用的离线数据同步工具/平台,它支持 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。基于 DataX 的同步机制,可以通过 OceanBase 数据库的 Reader 和 Writer 插件实现 OceanBase 数据库跨数据库、集群和异构数据库的数据迁移。
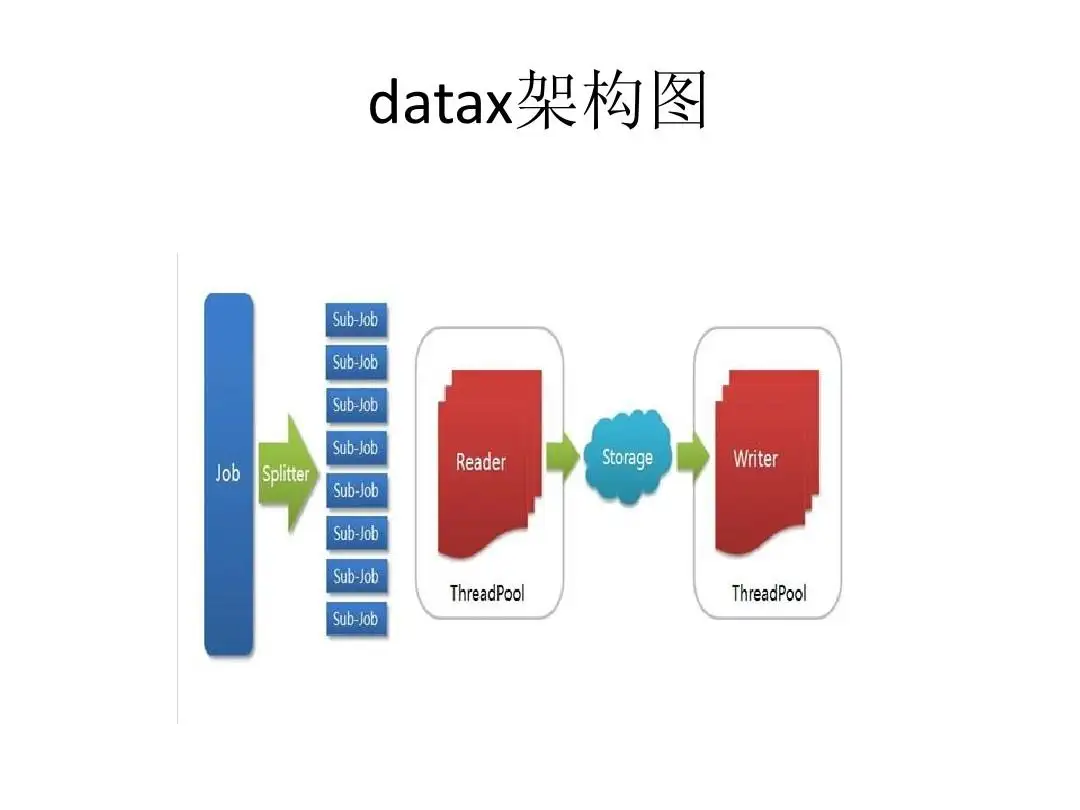
(2)举例说明
将 MySQL 数据迁移到 OceanBase ,如果源端和目标端不能同时跟 DataX 服务器网络联通,那么可以通过 CSV 文件中转。如果源端数据库和目标端数据库能同时跟 DataX 所在服务器联通,则可以使用 DataX 直接将数据从源端迁移到目标端。
{"job": {"setting": {"speed": {"channel": 4 },"errorLimit": {"record": 0,"percentage": 0.1}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "tpcc","passwd": "********","column": ["*"],"connection": [{"table": ["bmsql_oorder"],"jdbcUrl": ["jdbc:mysql://127.0.0.1:3306/tpccdb?useUnicode=true&characterEncoding=utf8"]}]}},"writer": {"name": "oceanbasev10writer","parameter": {"obWriteMode": "insert","column": ["*"],"preSql": ["truncate table bmsql_oorder"],"connection": [{"jdbcUrl": "||_dsc_ob10_dsc_||obdemo:oboracle||_dsc_ob10_dsc_||jdbc:oceanbase://127.0.0.1:2883/tpcc?useLocalSessionState=true&allowBatch=true&allowMultiQueries=true&rewriteBatchedStatements=true","table": ["bmsql_oorder"]}],"username": "tpcc","passwd":"********","writerThreadCount":10,"batchSize": 1000,"memstoreThreshold": "0.9"}}}]}
}
(3)迁移数据
OceanBase 数据同步到 Oracle
配置文件如下:```unknow
{"job": {"setting": {"speed": {
"channel": 16 },"errorLimit": {
"record": 0,
"percentage": 0.1}},"content": [{
"reader": {"name": "oceanbasev10reader","parameter": {"where": "","readBatchSize": 10000,"column": ["*"],"connection": [{"jdbcUrl": ["||_dsc_ob10_dsc_||obdemo:oboracle||_dsc_ob10_dsc_||jdbc:oceanbase://127.0.0.1:2883/tpcc"],"table": ["bmsql_oorder"]}],"username": "tpcc","passwd":"********"}
},
"writer": {"name": "oraclewriter","parameter": {"username": "tpcc","passwd": "********","column": ["*"],"preSql": ["truncate table bmsql_oorder"],"batchSize": 512,"connection": [{"jdbcUrl": "jdbc:oracle:thin:@127.0.0.1:1521:helowin","table": ["bmsql_oorder"]}]}
}4.使用 OUTFILE 语句迁移
(1)介绍说明
SELECT INTO OUTFILE 语句是 DBA 常用的一种数据导出方式。
与 mysqldump 对比, SELECT INTO OUTFILE 语句能够对需要导出的字段做出限制,这很好的满足了某些不需要导出主键字段的场景。再配合LOAD DATA INFILE 语句这将是一种很便利的数据导入导出方式。
(2)语法说明
SELECT [column_list] INTO '/PATH/FILE' [TERMINATED BY OPTIONALLY] [ENCLOSED BY OPTIONALLY][ESCAPED BY OPTIONALLY][LINES TERMINATED BY OPTIONALLY][FROM TABLENAME][WHERE condition][GROUP BY group_expression_list ][HAVING condition]][ORDER BY order_expression_list]
(3)使用举例
obclient> SELECT * INTO OUTFILE '/tmp/demo01.txt' FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' FROM student;
二、小结
数据库的国产化是很强的趋势,这对我们所有的技术人来说都是密不可分的,数据库的更换是对我们的数据迁移的过程是很强势的考验,但是数据掌握在自己手中,安全性便会大步提高,数据安全就是网络安全。