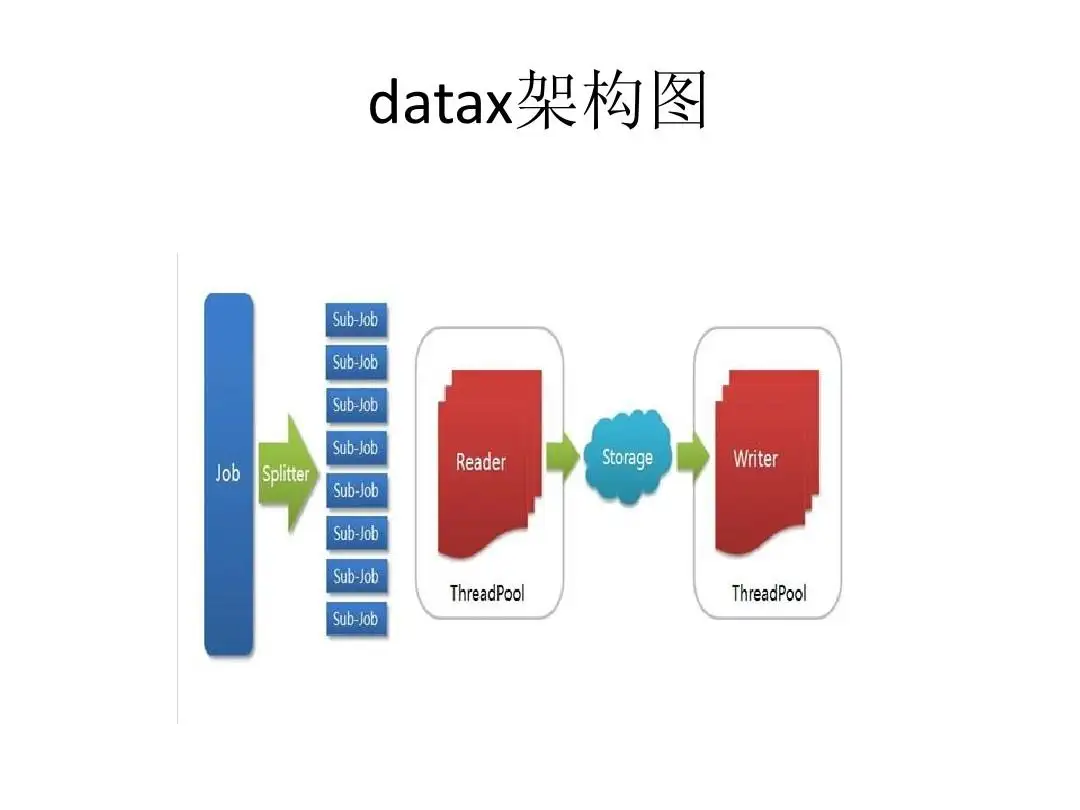
互联网系统,经常会有数据迁移的需求。系统从机房迁移到云平台,从一个云平台迁移到另一个云平台,系统重构后表结构发生了变化,分库分表,更换数据库选型等等,很多场景都需要迁移数据。
在互联网行业,很多系统的访问量很高,即便在凌晨两三点也有一定的访问量。由于系统数据迁移,导致服务暂停几分钟,是很难被业务方接受的!本文我们就来聊一下,在用户无感知的前提下,如何设计不停机数据迁移方案!
数据迁移过程我们要注意哪些关键点呢?第一,保证迁移后数据准确不丢失,即每条记录准确而且不丢失记录;第二,不影响用户体验(尤其是访问量高的C端业务需要不停机平滑迁移);第三,保证迁移后的性能和稳定性。
传统技术方案
传统方案一般由DBA来做,DBA先停止数据库的使用,然后书写迁徙脚本把数据导出到一个中间文件。然后再书写导入脚本,导入目标库。
传统方案的缺点
- 数据库会停止服务几小时甚至几天,应用程序无法使用,在一些行业应用中基本不可接受。
- 不能满足异构数据的迁徙,如果oralce或sqlservcer和mysql的数据结构不一样,有着比较复杂的映射关系,需要做数据转换,不能满足迁徙。
挂从库
在主库上建一个从库。从库数据同步完成后,将从库升级成主库(新库),再将流量切到新库。这种方式适合数据结构不变,而且空闲时间段流量很低,允许停机迁移的场景。一般发生在平台迁移的场景,如从机房迁移到云平台,从一个云平台迁移到另一个云平台。大部分中小型互联网系统,空闲时段访问量很低。在空闲时段,几分钟的停机时间,对用户影响很小,业务方是可以接受的。所以我们可以采用停机迁移的方案。步骤如下:
- 1,新建从库(新数据库),数据开始从主库向从库同步。
- 2,数据同步完成后,找一个空闲时间段。为了保证主从数据库数据一致,需要先停掉服务,然后再把从库升级为主库。如果访问数据库用的是域名,直接解析域名到新数据库(从库升级成的主库),如果访问数据库用的是IP,将IP改成新数据库IP。
- 3,最后启动服务,整个迁移过程完成。
这种迁移方案的优势是迁移成本低,迁移周期短。缺点是,切换数据库过程需要停止服务。
双写
老库和新库同时写入,然后将老数据批量迁移到新库,最后流量切换到新库并关闭老库读写。这种方式适合数据结构发生变化,不允许停机迁移的场景。一般发生在系统重构时,数据结构会发生变化,如表结构改变或者分库分表等场景。有些大型互联网系统,平常并发量很高,即便是空闲时段也有相当的访问量。几分钟的停机时间,对用户也会有明显的影响,甚至导致一定的用户流失,这对业务方来说是无法接受的。所以我们需要考虑一种用户无感知的不停机迁移方案。以笔者之前经历的用户系统重构为例,聊一下具体方案。当时的场景是这样的,用户表记录数达到3000万时,系统性能和可维护性变差,于是我们将用户中心从单体工程中拆分出来并做了重构,重新设计了表结构,而且业务方要求不停机上线!下面是我们当时的方案,步骤如下:
- 代码准备。在服务层对用户表进行增删改的地方,要同时操作新库和老库,需要修改相应的代码(同时写新库和老库)。准备迁移程序脚本,用于做老数据迁移。准备校验程序脚本,用于校验新库和老库的数据是否一致。
- 开启双写,老库和新库同时写入。注意:任何对数据库的增删改都要双写;对于更新操作,如果新库没有相关记录,需要先从老库查出记录,将更新后的记录写入新库;为了保证写入性能,老库写完后,可以采用消息队列异步写入新库。
- 利用脚本程序,将某一时间戳之前的老数据迁移到新库。注意:1,时间戳一定要选择开启双写后的时间点(比如开启双写后10分钟的时间点),避免部分老数据被漏掉;2,迁移过程遇到记录冲突直接忽略(因为第2步的更新操作,可能已经把记录拉到了新库);3,迁移过程一定要记录日志,尤其是错误日志,如果有填写失败的情况,我们可以通过日志恢复数据,以此来保证新老库的数据一致。
- 第3步完成后,我们还需要通过脚本程序检验数据,看新库数据是否准确以及有没有漏掉的数据
- 数据校验没问题后,开启双读,起初给新库放少部分流量,新库和老库同时读取。由于延时问题,新库和老库可能会有少量数据记录不一致的情况,所以新库读不到时需要再读一遍老库。逐步将读流量切到新库,相当于灰度上线的过程。遇到问题可以及时把流量切回老库
- 读流量全部切到新库后,关闭老库写入(可以在代码里加上热配置开关),只写新库
- 迁移完成,后续可以去掉双写双读相关无用代码。
利用数据同步工具
我们可以看到上面双写的方案比较麻烦,很多数据库写入的地方都需要修改代码。有没有更好的方案呢?我们还可以利用Canal,DataBus等工具做数据同步。以阿里开源的Canal为例。
上面是Canal的原理图,
- 1,Canal模拟mysql slave的交互协议,把自己伪装成mysql的从库
- 2,向mysql master发送dump协议
- 3. mysql master收到dump协议,发送binary log给slave(canal)
- 4. canal解析binary log字节流对象,根据应用场景对binary log字节流做相应的处理
所以上面的用户系统数据迁移,就不需要开启双写了,服务层也不需要编写双写的代码,直接用Canal做增量数据同步即可。相应的步骤就变成了:
- 代码准备。准备Canal代码,解析binary log字节流对象,并把解析好的用户数据写入新库。准备迁移程序脚本,用于做老数据迁移。准备校验程序脚本,用于校验新库和老库的数据是否一致。
- 运行Canal代码,开始增量数据(线上产生的新数据)从老库到新库的同步。
- 利用脚本程序,将某一时间戳之前的老数据迁移到新库。注意:1,时间戳一定要选择开始运行Canal程序后的时间点(比如运行Canal代码后10分钟的时间点),避免部分老数据被漏掉;3,迁移过程一定要记录日志,尤其是错误日志,如果有些记录写入失败,我们可以通过日志恢复数据,以此来保证新老库的数据一致。
- 第3步完成后,我们还需要通过脚本程序检验数据,看新库数据是否准确以及有没有漏掉的数据
- 数据校验没问题后,开启双读,起初给新库放少部分流量,新库和老库同时读取。由于延时问题,新库和老库可能会有少量数据记录不一致的情况,所以新库读不到时需要再读一遍老库。逐步将读流量切到新库,相当于灰度上线的过程。遇到问题可以及时把流量切回老库
- 读流量全部切到新库后,将写入流量切到新库(可以在代码里加上热配置开关。注:由于切换过程Canal程序还在运行,仍然能够获取老库的数据变化并同步到新库,所以切换过程不会导致部分老库数据无法同步新库的情况)
- 关闭Canal程序
- 迁移完成
此外,对于数据结构不改变的不停机数据迁移,也可以利用Canal处理。除了第3步DBA可以直接利用工具做老数据的迁移,其他步骤基本和上面一样。
阿里云的数据传输服务DTS
数据传输服务(Data Transmission Service,简称DTS)是阿里云提供的一种支持 RDBMS(关系型数据库)、NoSQL、OLAP 等多种数据源之间数据交互的数据流服务。DTS提供了数据迁移、实时数据订阅及数据实时同步等多种数据传输能力,可实现不停服数据迁移、数据异地灾备、异地多活(单元化)、跨境数据同步、实时数据仓库、查询报表分流、缓存更新、异步消息通知等多种业务应用场景,助您构建高安全、可扩展、高可用的数据架构。
优势:数据传输(Data Transmission)服务 DTS 支持 RDBMS、NoSQL、OLAP 等多种数据源间的数据传输。它提供了数据迁移、实时数据订阅及数据实时同步等多种数据传输方式。相对于第三方数据流工具,数据传输服务 DTS 提供更丰富多样、高性能、高安全可靠的传输链路,同时它提供了诸多便利功能,极大得方便了传输链路的创建及管理。
个人理解:就是一个消息队列,会给你推送它包装过的sql对象,可以自己做个服务去解析这些sql对象。
阿里文档快速入口:https://help.aliyun.com/product/26590.html
免去部署维护的昂贵使用成本。DTS针对阿里云RDS(在线关系型数据库)、DRDS等产品进行了适配,解决了Binlog日志回收,主备切换、VPC网络切换等场景下的订阅高可用问题。同时,针对RDS进行了针对性的性能优化。出于稳定性、性能及成本的考虑,推荐使用。