数据迁移方案
数据迁移框架有几个比较有名应用比较广泛的开源项目:阿里datax,apache sqoop以及Pentaho kettle。这三个框架整体上工作原理类似,下面介绍阿里datax数据迁移框架。
对旧系统进行了重构,就需要把原来的数据迁移到新数据库中。有同类数据库迁移,比如把mysql的数据迁移到mysql的数据,也有异类数据库迁移,比如把oracle数据迁移到mysql数据,也有把关系数据库迁移到非关系数据库,比如mysql数据迁移到HDFS等等。关系数据库之间进行数据迁移,通常会有表结构的变化,比如原来有1000张表,迁移完成之后,新的数据库只有600张表,新的数据库一张表数据可能来自老数据库的多张表的数据,也可能老数据库一张表数据需要分拆到新数据库的多张表。
数据迁移通常包括了三个步骤:读取源数据,对数据进行转换,写数据到新数据库,这个过程英文简称为ETL,即:E(抽取),T(转换),L(加载)。所以上面的三个开源项目也可以称为ETL工具。
为了适配不同的源和目的数据库,以及不同的转换方法,需要把这三个部分进行分离,在核心框架里面只设计接口,各个插件负责具体实现,这是一种接口和实现分离的程序设计方法。下图是datax的工作流程,包含了读写插件,读和写通过 channel进行了连接。读插件读取源数据之后,进行数据转换,再发送到channel,写插件读取到channel里面的数据,写到目的数据库。

- 程序整体设计
框架会先启动读(reader)、写(writer)线程,reader、writer分别运行在不同的独立线程里面,reader线程启动之后立即读取源数据,组装数据,每一条记录封装为Record类,之后会对Record进行转换,完成之后发送到channel。writer所在的线程启动之后就处于等待状态,当channel里面有了准备好的数据,就会读取出来,并批量写入到目的数据库中。
为reader和writer分别定义了两个线程类:ReaderRunner,WriterRunner,这两个类分别实现了接口Runnable,在这两个类的run方法里面分别调用了reader和writer接口的startRead以及startWrite。
1.加载reader/writer
读和写封装在不同的线程中运行:ReaderRunner,WriteRunner。在构造读写线程的时候,利用Java的反射机制,动态加载正确的读写类,或者称之为插件。所有读插件需要实现接口Reader,写插件实现接口Writer。Reader里面有两个方法,一个是startRead,在这里实现实际的读操作。另外一个是split,对读任务进行切分,实现多线程并发。写插件类似,实现两个方法,一个是startWrite,进行实际的写操作。Split方法同样,对写操作进行切分,实现多线程并发,读和写的并发操作在后面详细描述。
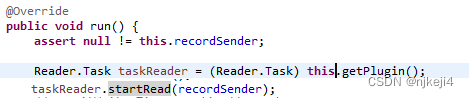
读写插件的配置比较简单,以json格式,比如读取mysql数据库数据,加载mysql插件,只需要如下配置:reader:{“name” : ”mysql”}。插件最后会打包为JAR包,所以类加载是从插件jar包中进行,利用代码URLClassLoader.loadClass()来完成。加载完成之后立刻进行读操作,如下是代码片段:
2.组装数据
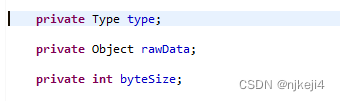
对读取的数据,会组装成一个数据集合,集合里面的基本单元称之为一条记录,每一个记录包含多列。无论数据是否来自关系数据库,Reader负责组装一个最小数据单元为一个记录Record。在关系数据库中,一行就是一条记录。Record按照多列来组织,每一列称之为Column。Column存储的数据定义了三个变量:数据类型,原始数据,数据大小:
对于非关系数据库或者说非结构化数据,需要在配置文件里面定义分隔符,Reader之后根据分隔符对每一条数据,进行列切分,同样,不像关系数据库,每一列数据的类型也不清楚,需要在配置文件里面进行配置。如下是一个列配置例子,配置了每一列的数据类型和默认的值。

3.数据转换
在数据被发送到通道,Writer读取以前,可以对数据进行转换。数据转换类也可以作为一个插件,根据配置文件动态加载。数据转换类需要扩展抽象类Transformer,实现方法:abstract public Record evaluate(Record record, Object... paras);该方法输入参数是一个Record,输出参数也是一个Record。该方法中可以对record中的列进行计算、增加新列,删除列等转换操作。对于一条记录可以定义多个数据转换类,每个数据转换类依次执行。
转换器可以在配置文件定义,如下是一个例子:
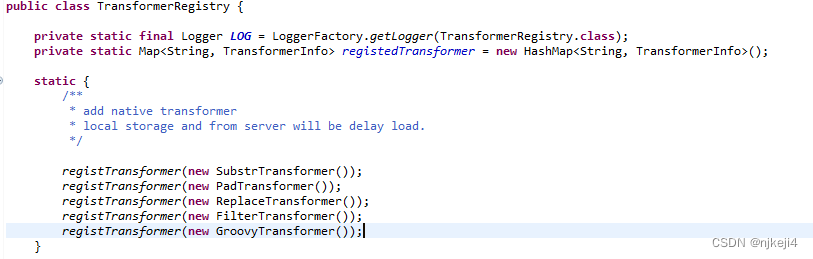
Transformer在配置文件中是一个数组,可以定义多个转换器。转换器的加载有两种方式:第一种方式,转换器定义在框架中,和框架集成打包在一起,需要修改框架代码。开发完成一个转换器以后,在TransformerRegistry里面进行注册。在加载配置文件,生成Reader的过程中,根据配置的转换器名字加载对应的转换类。

转换器也可以作为插件开发,开发方式一样,同样需要扩展类Transformer,实现evaluate方法,和加载读写插件一样,从jar包中加载对应的转换类。
4.数据传递
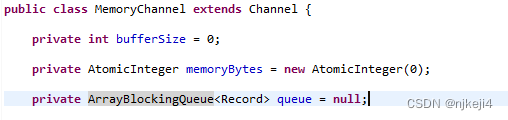
数据转换完成以后,读线程会首先把数据放在一个缓存里面,等到缓存到了设定值,比如记录条数达到一定数值,就会把数据推送到通道里面。在datax里面通道是通过读写线程共享同一个类实例来实现的。在类里面定义了一个队列:
以及两个主要方法:push和pull。读队列通过push方法,把转换完成之后的数据放到channel的队列里面。
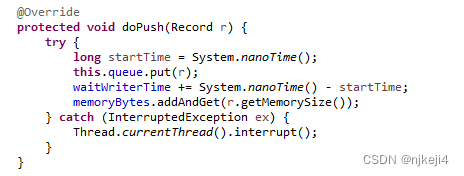
写线程通过pull方法,从队列里面读取记录。通过这种方式完成了读取数据,转换,推送到写队列。
这里用到了一个数据结构:ArrayBlockQueue,这是一个有界的阻塞队列,内部就是一个数组,采用先进先出的原则。
5.数据写入
写线程从channel中读取到Record之后,需要把Record转换为适当的格式,写入到关系数据库或者文件中。对于关系数据库,准备SQL语句,把记录中的每一列对应到SQL语句中去,进行批量提交,就完成了数据写操作。写操作就是读取数据以及组装数据的逆操作,过程和前面的描述类似。
6.日志上报
在对数据进行移植过程中需要记录每一步操作,监控数据处理过程。
- 并发设计
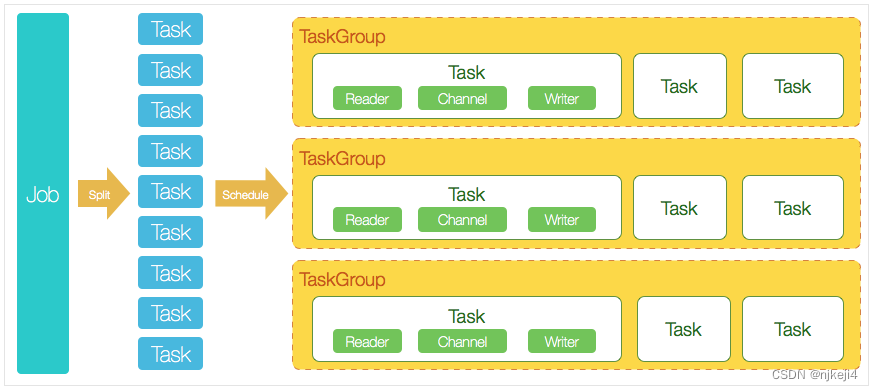
Datax是一个单进程多线程程序,这里的并发是根据配置启动多个读写线程来完成数据读写和转换任务。线程数量是根据流量设置来控制的:设置总的读写流量字节,默认的配置文件中总流量为10485760字节(10M),每个通道设置的流量为1048576(1M),也就是需要10个并行通道,每一个通道连接一个读和写线程,所以会启动10个读和10个写线程。一个读写线程再加上一个通道,构成了一个任务。为了遍历观察每个任务的执行情况,可以在一个观察线程里面循环遍历这10个任务。但是datax对任务进行了分组,每个组里面有多少个线程可以在配置文件里面设置,然后对每个组启动一个观察线程,查看每个组里面每个任务执行情况,然后分别上报。
- 分布式部署
Datax本身不支持分布式部署,但是单机程序存在几个缺点:内存和连接数量的限制,在一个机器上可以并行运行的线程数量有限制;异常会导致整个移植进程终止等。为了支持分布式部署,可以结合其他任务调度框架,这个方案是结合xxl-job框架,实现分布式部署。xxl-job本身是一个简单的任务调度框架,一个中心服务器作为调度器,其他机器充当执行服务器。
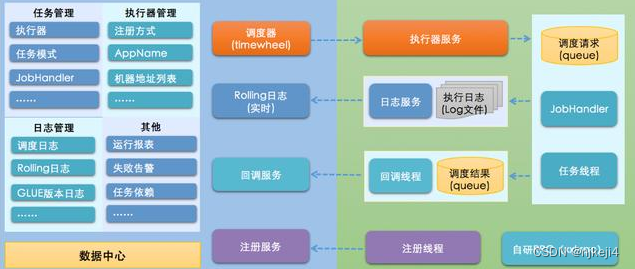
在调度器上配置任务,命令下发给执行器,执行器执行命令,反馈执行状态给调度器。