Python 爬取网页信息并保存到本地【简单易懂,代码可以直接运行】
功能:给出一个关键词,根据关键词爬取程序,这是爬虫爬取网页的第一步
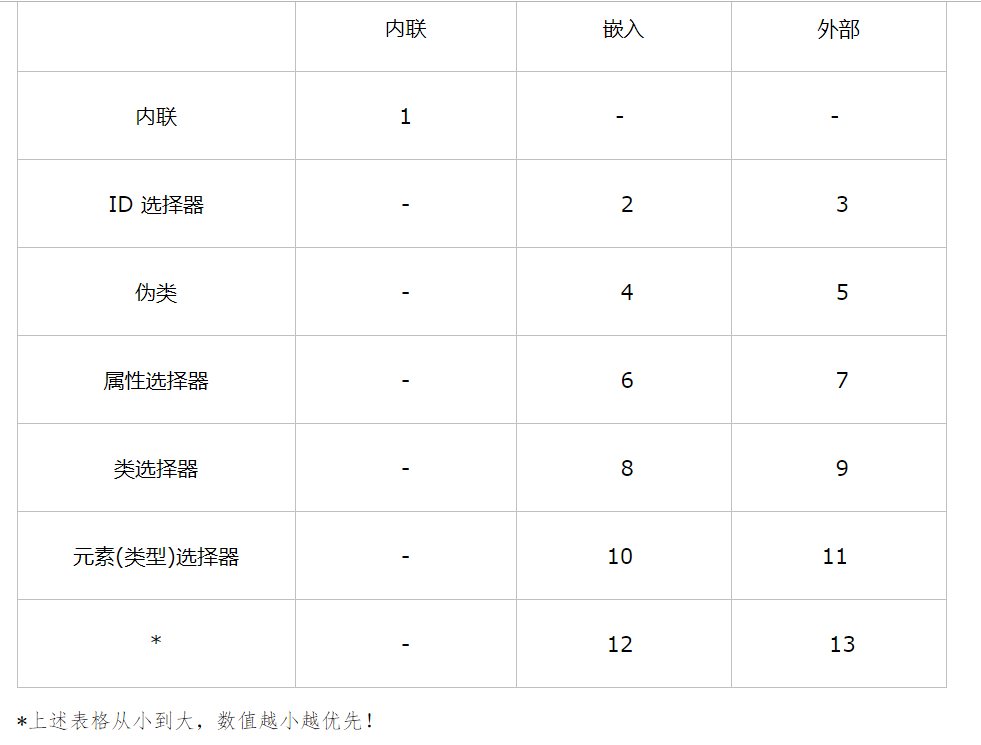
步骤:
1.确定url
2.确定请求头
3.发送请求
4.写入文件
确定请求头是其中的关键一步:
base_url = 'https://search.jd.com/Search?keyword={}&qrst=1&wq=%E8%8F%8C%E8%8F%87%E6%B0%B4&stock=1&pvid=16410c70ae6b422c9f67d397d90f0291&page={}&s=56&click=0'.format(key_words,page_name)这里面用到的是京东的网址,其中需要将keyword于page去掉并换上大括号,这里用到的是字符串的format用法,详细的可以参考我发布的字符串文章。keyword是为了找到所搜寻的商品的关键字,page是为了遍历要搜寻的页面。
3.发送请求这一步,python编译器中需要提前安装requests库,可以直接利用import requests来判断自己的python编译器中有没有request库,如果没有就在命令函中输入 pip install requests命令语句安装即可。
respone = requests.get(url=base_url,headers=headers)
需要注意的是有的网站带有反爬虫机制,他会阻止你爬取网页信息,此时这里需要你去拿到该网站的cookie去伪装浏览器去爬取信息,这里的网站暂时还用不到。后面会更新cookie的内容
最后将爬取的到的信息写入到本地文件,用的是with as语句,课本中的知识点。
with open('./day06{}北面.html'.format(page_name),'w',encoding='utf-8') as fp:fp.write(respone.text)
代码如下:
import requests
'''
创建一个输入关键字就可以爬取的程序
'''
key_words = input('请输入要爬取商品的关键字:')
def get_page(page_name):#S1 确定urlbase_url = 'https://search.jd.com/Search?keyword={}&qrst=1&wq=%E8%8F%8C%E8%8F%87%E6%B0%B4&stock=1&pvid=16410c70ae6b422c9f67d397d90f0291&page={}&s=56&click=0'.format(key_words,page_name)#S2确定请求头headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',}#S3发送请求respone = requests.get(url=base_url,headers=headers)#S4写入文件with open('./day06{}北面.html'.format(page_name),'w',encoding='utf-8') as fp:fp.write(respone.text)if __name__ == '__main__':for i in range(1,10):get_page(i)
运行结果如下:

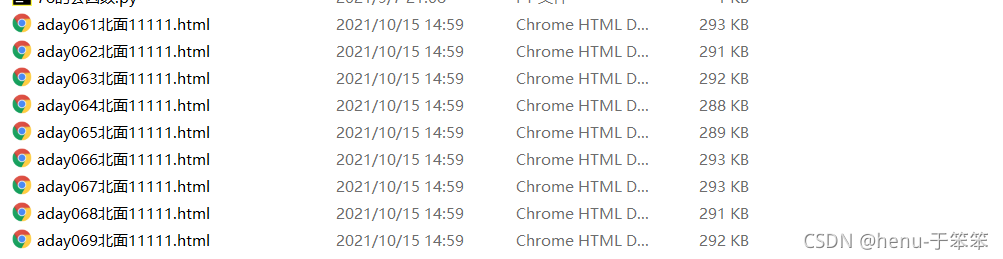
这样即是爬取网页信息成功。
点个👍吧,秋梨膏!!!