经常遇到的是爬取网页写入表格中,保存为csv格式、txt格式。最近接到一个任务,复制网页中文字和表格保存到word中,不仅有文字,还有表格。一看有100多页,要是一页一页的复制,要干到什么年月啊。 经过一番搜索,发现还真有一个库可以处理word文档,一颗悬着的心稍稍有了安慰。
本次爬取数据导入到word中,需要用到Python-docx库。
先来说说爬虫思路:
-
请求网页
-
解析网页,提取数据
提取网页中的标题、表头、表格
-
写入word
-
保存数据
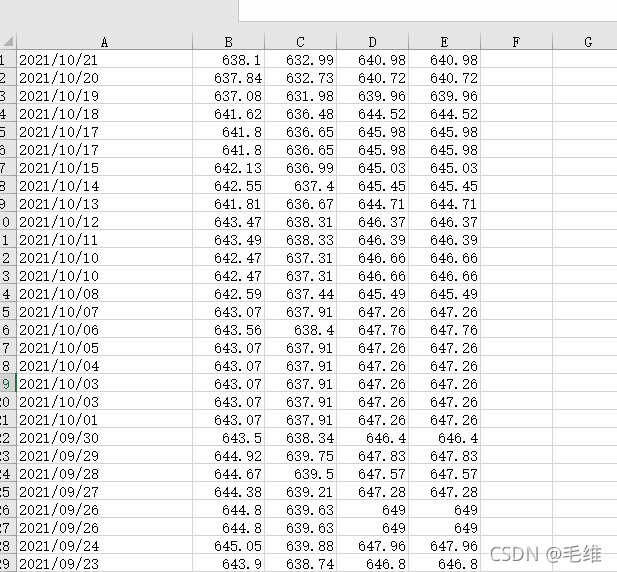
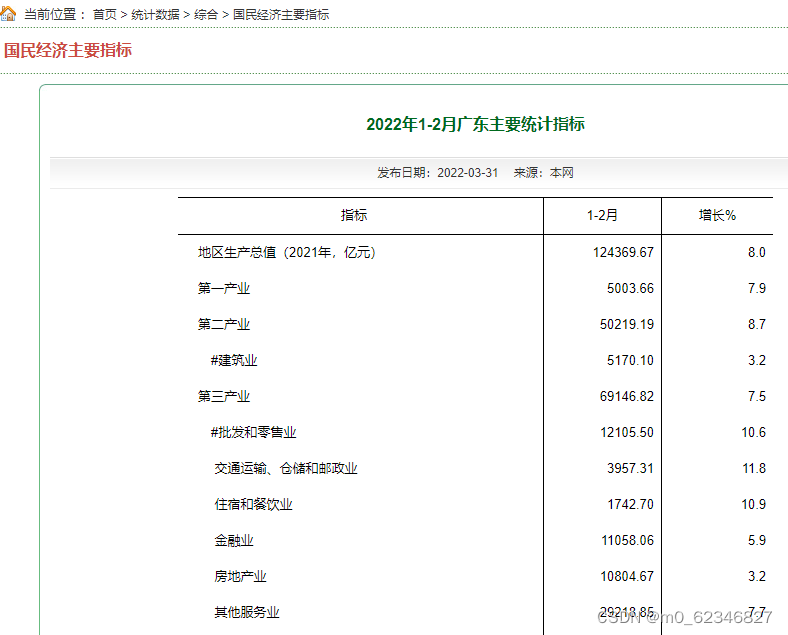
本次爬取的网页是“某统计信息网”,爬取“ 2022年1-2月主要统计指标”,目标网址是广东省统计局-2022年1-2月广东主要统计指标。
网页长这样,有标题、表头、表格。
1、安装库
安装Python-docx库, 使用pip下载。
把Python -docx官方文档的链接也放上来: python-docx — python-docx 0.8.11 documentation
win键+R打开运行窗口,在运行窗口中进行命令的输入以及打开软件或工具,输入CMD,用来打开命令提示符窗口。进入命令行界面,输入以下代码,等待安装完成即可使用。
pip install python-docx2.导入库文件
本次需要用requests、parsel、pandas、docx等库。
#-*- coding:utf-8 -*-
import requests
from parsel import Selector
import pandas as pd
from docx import Document3.请求网页
使用requests库的get()方法获取网页。
# 1.获取网页数据
url = "http://stats.gd.gov.cn/gmjjzyzb/content/post_3900512.html"
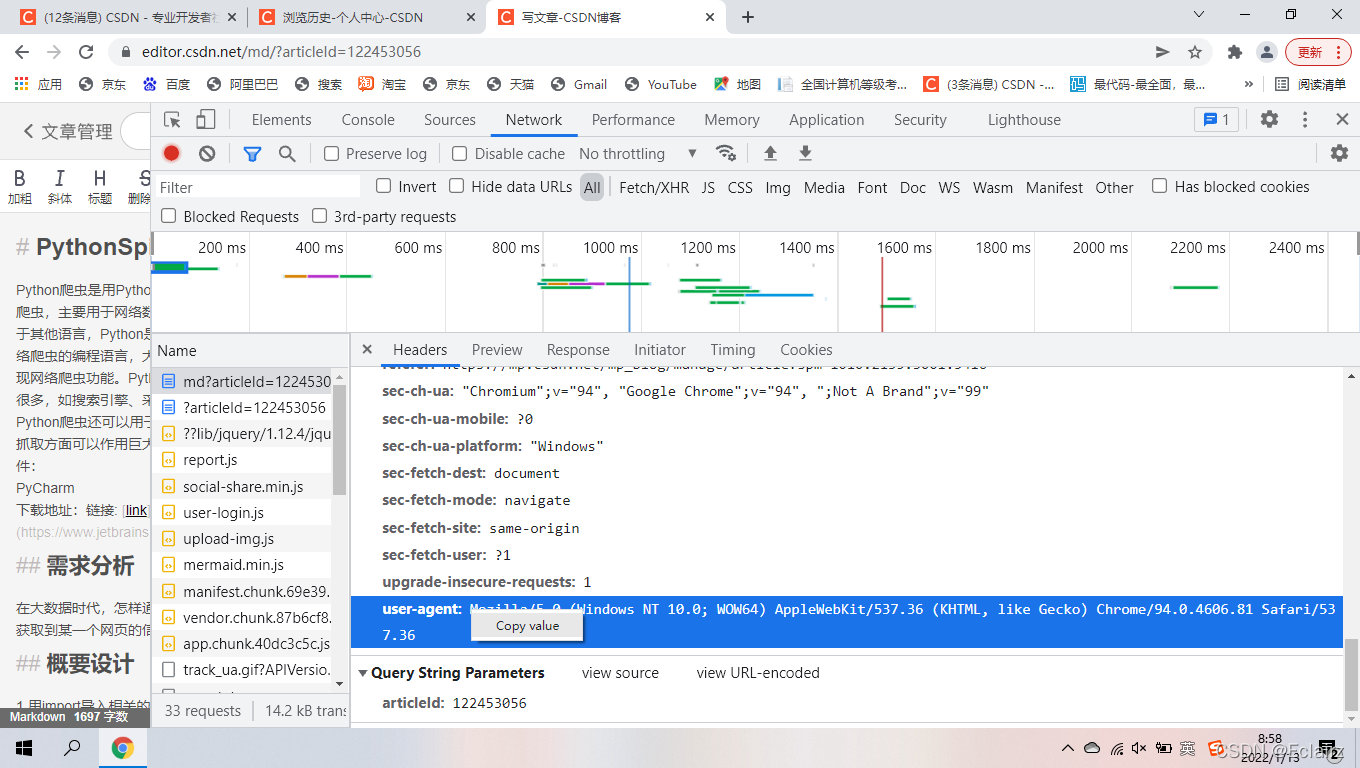
# 请求头信息
header = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Mobile Safari/537.36'
}
# 请求数据
response = requests.get(url, headers=header)
# 查看请求数据的结果的状态码
print(response.status_code)response库的status_code状态码200,代表获取网页成功。
4.解析网页,提取数据。
这里我们采用parsel库的xpath方法解析网页,使用selector将网页转换为可解析对象。
# 解析网页,爬取标题、表头和表格
selector = Selector(response.text)使用xpath方法定位网页元素,提取标题、表格、表头等数据。
获取表格采用pandas的read_html方法来爬取,非常高效、容易编写。
提取表格的表头并转换为列表,便于后面的写入word中提供遍历。
在浏览器中选中“2022年1-2月广东主要统计指标"右击鼠标,单击”检查“,定位元素位置,编写xpath提取语句"//*[@class='main']/h4/text()"。
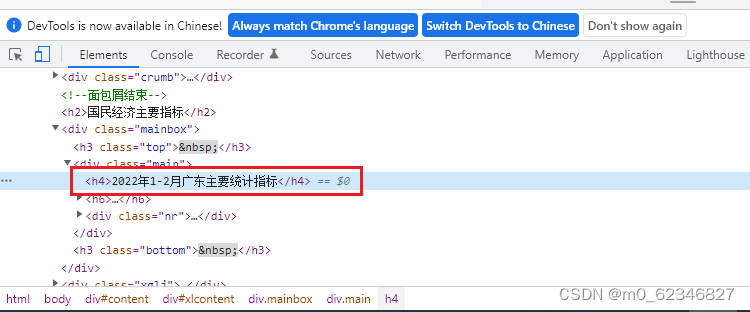
# 获取标题
page_header = selector.xpath("//*[@class='main']/h4/text()").extract()
# 获取表格
df = pd.read_html(url, encoding='utf-8',header=0)[1]
# 重新设置行索引,行索引从1开始
df.index = df.index +1
# 获取表头
tabel_header = list(df.columns)
已经获取到网页的标题、表格等数据,接下来写入到word中。
5.将数据写入word中并保存
使用python-docx库的Document()方法打开一个文档。我们的目标是写入标题、表头、表格。
使用document库add_heading方法,写入标题。
#打开文档
document = Document()
#写入文档标题
text = page_header[0]
document.add_heading(text=text,level=1)定义写入文档函数df_toword,向文档中写入表头、单元格值,并保存为word格式。
这里需要强调的是,需要分开写入表头和单元格值,先写入表头,再写入单元格中的值。
该部分代码如下:
# 3 写入文档
def df_toword():#增加表格t = document.add_table(df.shape[0]+1, df.shape[1],style='Table Grid')#写入列名hdr_cells = t.rows[0].cellsfor i in range(len(tabel_header)):hdr_cells[i].text = tabel_header[i]# 写入单元中的值for i in range(df.shape[0]):for j in range(df.shape[1]):t.cell(i+1,j).text = str(df.values[i,j]) # 保存到指定文件 document.save(u'data.docx') 6.执行程序
我们已经完成了请求网页、解析网页、提取数据、写入文档等功能,终于到了执行环节,怀着一颗激动的心,测试下程序是否可行。
# 执行程序
df_toword()
print("网页已下载到word中")打开下载好的文档看看效果怎么样,标题、表头、表格都有,达到了预期目标。文档中的数据是表格格式,在文档中加上网格线就和网页中的一样。
好了,本次的分享就到这里了。
转载注明原作者