python学习笔记(三)—python爬取网页指定内容
1、利用正则匹配爬取指定内容,例如标题
正则表达式:
<title>(.*?)</title>
req = urllib.request.Request(url=url,headers=headers)
content = urllib.request.urlopen(req).read()
content = content.decode('utf-8')
title = re.findall(r'<title>(.*?)</title>', content)
print(title)
2、利用beautifulsoup获取网页各标签内容
需要用到distutils.filelist、bs4模块
from bs4 import BeautifulSoup
from distutils.filelist import findall
请求并获取网页
url = 'https://app.xx.com'
response = requests.get(url)
req = urllib.request.Request(url=url)
content = urllib.request.urlopen(req).read()
content=content.decode('utf-8')
获取网页内指定内容
if response.status_code == 200:#判断网页状态soup = BeautifulSoup(content,"html.parser")tag = soup.find_all('h5') #获取网页内所有h5标签#print(tag)for tag1 in tag: #print(tag1) if tag1.find('a'): taga = tag1.find('a') #tag内获取a标签 href = tag1.find('a').get('href')#获取href内容#print(href)tagtext = tag1.find('a').get_text()#获取标签内文本信息else:break
获取指定标签内容,附带参数
htlgball = soup.find_all('span',class_='htlgb')
3.利用xpath爬取网页指定内容
from lxml import etreeurl = "http://www.xxxx.com/mb/1149"
req = urllib.request.Request(url=url)
response = requests.get(url)
page = response.text
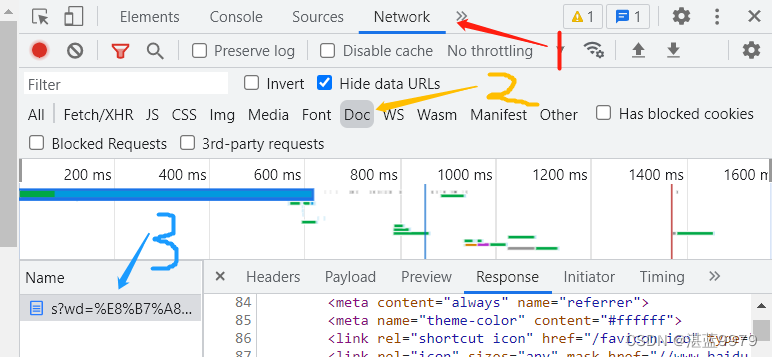
浏览器F12定位并获取需要爬取内容的xpath
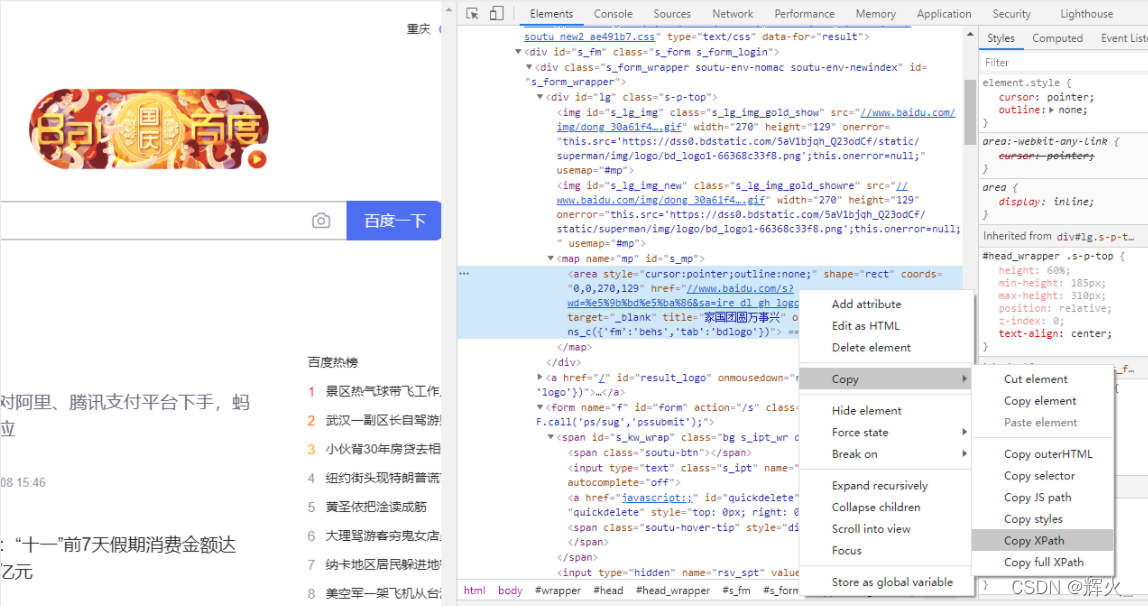
/html/body/div[1]/div[1]/div[1]/div[2]/div[1]/div
获取指定内容
html = etree.HTML(page)#将html转换成_Element对象
aa = html.xpath('/html/body/div[1]/div[1]/div[1]/div[2]/div[1]/div')[0].text
print(aa)