PythonSpider项目
Python爬虫是用Python编程语言实现的网络爬虫,主要用于网络数据的抓取和处理,相比于其他语言,Python是一门非常适合开发网络爬虫的编程语言,大量内置包,可以轻松实现网络爬虫功能。Python爬虫可以做的事情很多,如搜索引擎、采集数据、广告过滤等,Python爬虫还可以用于数据分析,在数据的抓取方面可以作用巨大!此次项目我们所需软件:
PyCharm
下载地址:链接: link.
需求分析
在大数据时代,怎样通过爬虫快速并且有效的获取到某一个网页的信息。
概要设计
1.用import导入相关的包
2.设置公共变量url和headers
3.获取页面并返回参数
4.解析页面并返回参数
5.保存页面并返回参数
代码实现
一、导入相应模块
import requests
import re
import csv
import time
import random
二、获取网页信息,并解析
class DongManSpider:#公共变量def __init__(self):self.url = " " #需要给出相应路径的网页self.headers = {"User-Agent":" "}#需要获取目标地址中的User-Agent,有时候还需要加上Cookie。#获取页面def get_html(self,url):#每生成一个网页,获取该网页的代码html = requests.get(url, headers=self.headers).text#返回参数return html#解析页面def parse_html(self,html):#编写正则表达式regex = ''' ''' #正则表达式里放你需要爬取的信息#构建正则对象p = re.compile(regex, re.S)#匹配info = p.findall(html)#返回参数return info
三、保存输出
#保存页面def save_html(self,info):# 循环遍历出里面的元组for i in info:#构建一个空列表L = []#将数据清洗过后放入列表,再用strip()去掉多余的空格和换行name= i[0].strip()address= i[1].strip()time= i[2].strip()L.append(name)L.append(address)L.append(time)#每遍历一个元组,就保存追加至domgman.csv文件中f = open("dongman.csv", "a", encoding="utf-8-sig", newline="")#将open对象构建成csv对象w = csv.writer(f)#将遍历的元组放进文件中w.writerow(L)
四、运行测试
用我Excel打开之前获取到的CSV文件,我们就得到了我们想要的信息。

如何正确的书写正则表达式
1、ctrl + A 复制页面源码,到txt文本,在网页中找到关键字段,并在txt文本中查找其位置
2、在网页中找到关键字段的位置,观察其同一模块的信息,与txt文本相对应,然后定位。然后观察要爬取的第一个信息的开头,和要爬取最后一个信息的开头,是否是每个信息段的唯一标志
3、确定信息段后,单独保存。确定要爬取的信息,然后再判断定位该信息的开头是否是信息段内的唯一字符。保留确定每一个关键信息的开头,以及最近的结尾字段
4、用.代替每一段结尾至下一段开头的内容。把要爬取的内容,用(.)代替
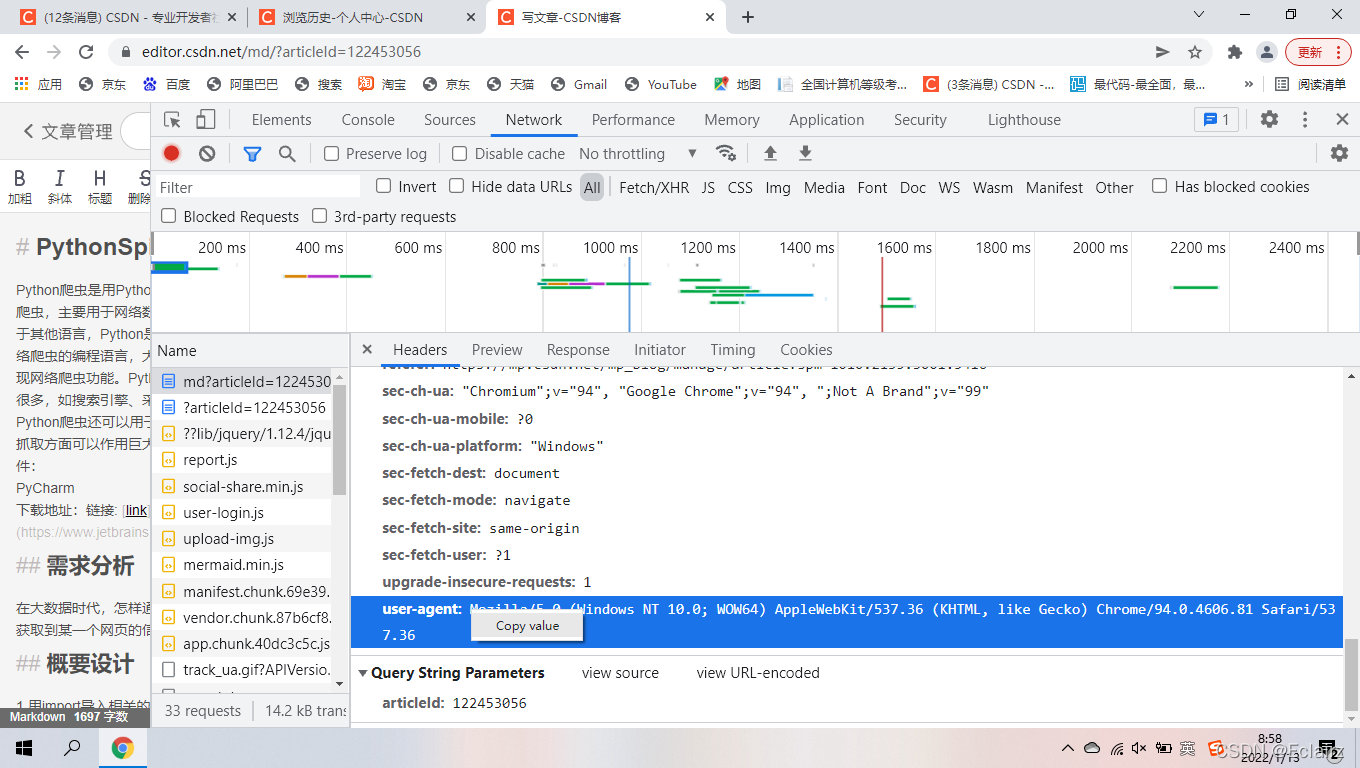
如何正确找到网页的User-Agent
1、找到并Copy它的值进去就可以了
此技术大多用于静态网页的爬取,对于拥有较高反爬机制的网站会出现数据获取不了的状况。只用做学习交流。
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦