用Python爬虫,爬取网页的所有内外链
- 项目介绍
- 代码大纲
- 网站详情
- 代码详情
- 队列
- 内链外链
- 请求头
- 完整代码
- 爬取结果
项目介绍
采用广度优先搜索方法获取一个网站上的所有外链。
首先,我们进入一个网页,获取网页的所有内链和外链,再分别进入内链中,获取该内链的所有内链和外链,直到访问完所有内链未知。
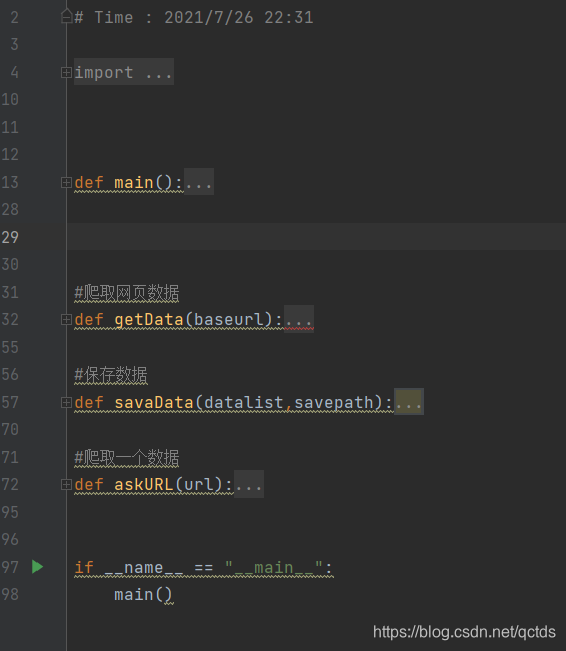
代码大纲
1、用class类定义一个队列,先进先出,队尾入队,队头出队;
2、定义四个函数,分别是爬取网页外链,爬取网页内链,进入内链的函数,以及调函数;
3、爬取百度图片(https://image.baidu.com/),先定义两个队列和两个数组,分别来存储内链和外链;程序开始时,先分别爬取当前网页的内链和外链,再分别入队,对内链外链进行判断,如果在数组中没有存在,这添加到数组中;
4、接着调用deepLinks()函数,采用循环结构,如果当前内链数量不为空时,则对存储内链的队列进行出队,并进入该内链中,再重复调用爬取网页内链和网页外链的函数,进行判断网页链接是否重复, 不重复的话,再分别将内链,外链加入到对应的队列中,不断迭代循环;
5、进入网页内所有的内链,从中搜索出所有的外链并且存储在队列中,再输出。
网站详情


代码详情
队列
队列是一种特殊的线性表,单向队列只能在一端插入数据(后),另一端删除数据(前);
它和栈一样,队列是一种操作受限制的线性表;
进行插入操作的称为队尾,进行删除操作的称为队头;
队列中的数据被称为元素;没有元素的队列称为空队列。
由于只能一端删除或者插入,所以只有最先进入队列的才能被删除,因此又被称为先进先出(FIFO—first in first out)线性表。
这里我们用class类定义一个队列,先进先出,队尾入队,队头出队,该队列要有定义以下功能:出队、入队、判断是否为空、输出队列长度、返回队头元素。
class Queue(object):#初始化队列def __init__(self):self.items = []#入队def enqueue(self, item):self.items.append(item)#出队def dequeue(self):if self.is_Empty():print("当前队列为空!!")else:return self.items.pop(0)#判断是否为空def is_Empty(self):return self.items == []#队列长度def size(self):return len(self.items)#返回队头元素,如果队列为空的话,返回Nonedef front(self):if self.is_Empty():print("当前队列为空!!")else:return self.items[len(self.items) - 1]
内链外链
内链外链的区别:
内链:是指同一网站域名下内容页面之间的互相链接。
外链:是指在别的网站导入自己网站的链接,如友情链接、外链的搭建等。
通俗的讲,内链即为带有相同域名的链接,而外链的域名则不相同。
说到内链外链,那必然离不开urllib库了,首先导入库
from urllib.parse import urlparse
用urlparse模块来解析url链接,urlparse()模块将url拆分为6部分:
scheme (协议)netloc (域名)path (路径)params (可选参数)query (连接键值对)fragment (特殊锚)
url='https://image.baidu.com/'
a, b = urlparse(url).scheme, urlparse(url).netloc
print(a)
print(b)#-----------------输出结果---------------------#
https
image.baidu.com
请求头
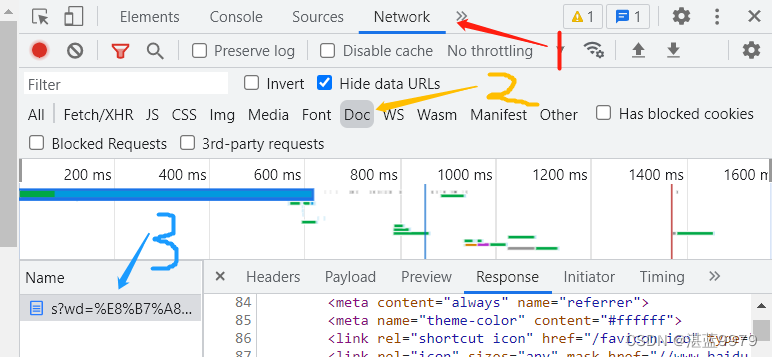
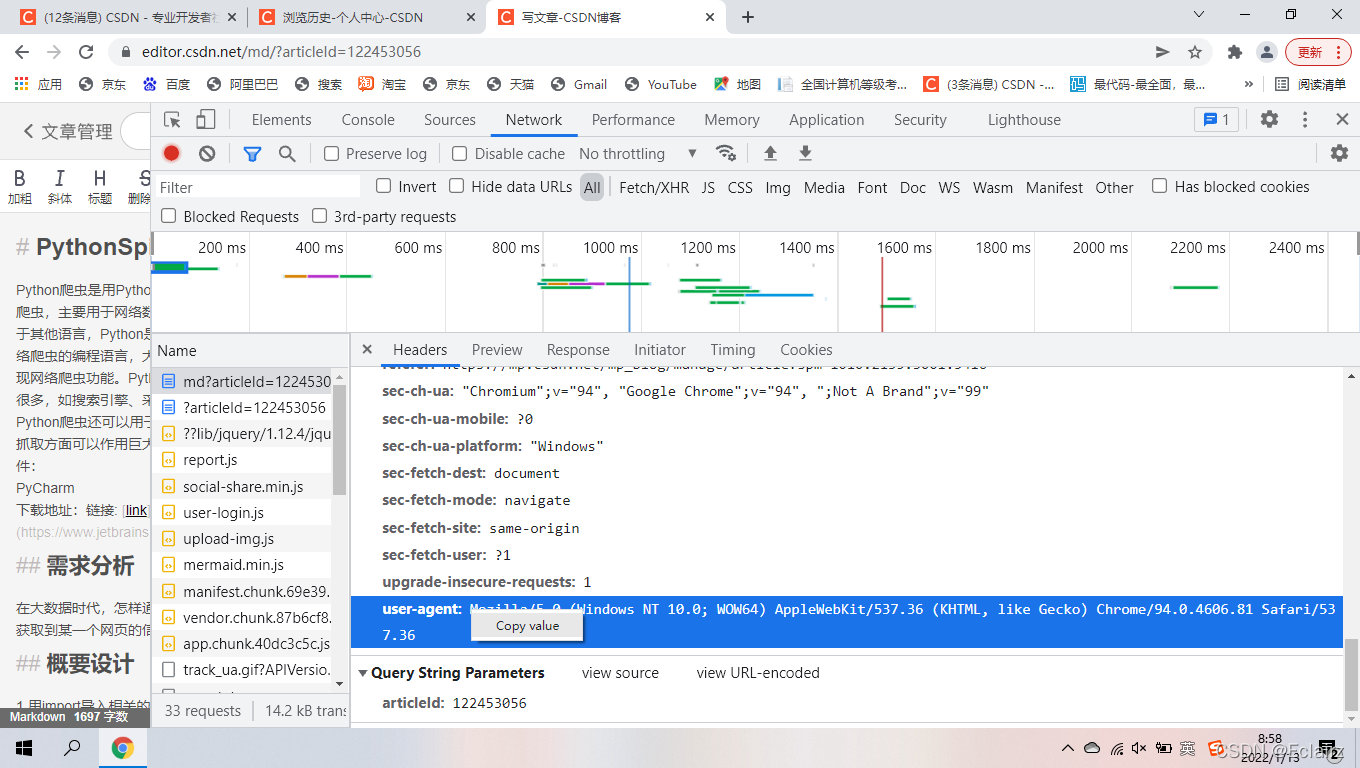
Header来源 用浏览器打开需要访问的网页,按F12,点开network,再按提示按ctr+R,点击name选择网站名,再看到有一个右边框第一个headers,找到request headers,这个就是浏览器的请求头, 复制其中的user-agent,复制内容。

这里的请求头为:
headers_={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68'}
html = requests.get(url,headers=headers_)
完整代码
class Queue(object):#初始化队列def __init__(self):self.items = []#入队def enqueue(self, item):self.items.append(item)#出队def dequeue(self):if self.is_Empty():print("当前队列为空!!")else:return self.items.pop(0)#判断是否为空def is_Empty(self):return self.items == []#队列长度def size(self):return len(self.items)#返回队头元素,如果队列为空的话,返回Nonedef front(self):if self.is_Empty():print("当前队列为空!!")else:return self.items[len(self.items) - 1]#导入库
from urllib.request import urlopen
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import requests
import re
import urllib.parse
import time
import randomqueueInt = Queue() #存储内链的队列
queueExt = Queue() #存储外链的队列externalLinks = []
internalLinks = []#获取页面中所有外链的列表
def getExterLinks(bs, exterurl):#找出所有以www或http开头且不包含当前URL的链接for link in bs.find_all('a', href = re.compile('^(http|www)((?!'+urlparse(exterurl).netloc+').)*$')):#按照标准,URL只允许一部分ASCII字符,其他字符(如汉字)是不符合标准的,#我们的链接网址可能存在汉字的情况,此时就要进行编码。link.attrs['href'] = urllib.parse.quote(link.attrs['href'],safe='?=&:/')if link.attrs['href'] is not None:if link.attrs['href'] not in externalLinks:queueExt.enqueue(link.attrs['href'])externalLinks.append(link.attrs['href'])print(link.attrs['href'])
# return externalLinks#获取页面中所以内链的列表
def getInterLinks(bs, interurl):interurl = '{}://{}'.format(urlparse(interurl).scheme,urlparse(interurl).netloc)#找出所有以“/”开头的内部链接for link in bs.find_all('a', href = re.compile('^(/|.*'+urlparse(interurl).netloc+')')):link.attrs['href'] = urllib.parse.quote(link.attrs['href'],safe='?=&:/')if link.attrs['href'] is not None:if link.attrs['href'] not in internalLinks:#startsWith()方法用来判断当前字符串是否是以另外一个给定的子字符串“开头”的if(link.attrs['href'].startswith('//')):if interurl+link.attrs['href'] not in internalLinks:queueInt.enqueue(interurl+link.attrs['href'])internalLinks.append(interurl+link.attrs['href'])elif(link.attrs['href'].startswith('/')):if interurl+link.attrs['href'] not in internalLinks:queueInt.enqueue(interurl+link.attrs['href'])internalLinks.append(interurl+link.attrs['href'])else:queueInt.enqueue(link.attrs['href'])internalLinks.append(link.attrs['href'])
# return internalLinksdef deepLinks():num = queueInt.size()while num > 1:i = queueInt.dequeue()if i is None:breakelse:print('访问的内链')print(i)print('找到的新外链')# html = urlopen(i)html=requests.get(i,headers=headers_)time.sleep(random.random()*3)domain1 = '{}://{}'.format(urlparse(i).scheme, urlparse(i).netloc)bs = BeautifulSoup(html.content, 'html.parser')getExterLinks(bs, domain1)getInterLinks(bs, domain1)def getAllLinks(url):global num
# html = urlopen(url)headers_={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68'}html = requests.get(url,headers=headers_)time.sleep(random.random()*3) #模拟人类行为,间隔随机的时间domain = '{}://{}'.format(urlparse(url).scheme, urlparse(url).netloc)bs = BeautifulSoup(html.content, 'html.parser')getInterLinks(bs, domain)getExterLinks(bs, domain)deepLinks()getAllLinks('https://image.baidu.com/')爬取结果
这里我只是截取一部分:


数组中的所有内链
internalLinks-------------输出内容------------------['http://image.baidu.com','https://image.baidu.com/img/image/imageplus/index.html?fr=image','http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1567133149621_R&pv=&ic=0&nc=1&z=0&hd=0&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%25E5%25A3%2581%25E7%25BA%25B8','http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1461834053046_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&itg=0&ie=utf-8&word=%25E5%25A4%25B4%25E5%2583%258F%23z=0&pn=&ic=0&st=-1&face=0&s=0&lm=-1','https://image.baidu.com/search/albumslist?tn=albumslist&word=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&rn=15&fr=searchindex','https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E5%259F%258E%25E5%25B8%2582%25E5%25BB%25BA%25E7%25AD%2591%25E6%2591%2584%25E5%25BD%25B1%25E4%25B8%2593%25E9%25A2%2598&fr=searchindex_album%2520&album_tab=%25E5%25BB%25BA%25E7%25AD%2591&album_id=7&rn=30','https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E6%25B8%2590%25E5%258F%2598%25E9%25A3%258E%25E6%25A0%25BC%25E6%258F%2592%25E7%2594%25BB&fr=albumslist&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_id=409&rn=30','https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E7%259A%25AE%25E5%25BD%25B1&fr=albumslist&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_id=394&rn=30','https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E5%25AE%25A0%25E7%2589%25A9%25E5%259B%25BE%25E7%2589%2587&fr=albumslist&album_tab=%25E5%258A%25A8%25E7%2589%25A9&album_id=688&rn=30','https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E8%2588%25AA%25E6%258B%258D%25E5%259C%25B0%25E7%2590%2583%25E7%25B3%25BB%25E5%2588%2597&fr=albumslist&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_id=312&rn=30','https://image.baidu.com/search/albumslist?tn=albumslist&word=%25E4%25BA%25BA%25E7%2589%25A9&album_tab=%25E4%25BA%25BA%25E7%2589%25A9&rn=15&fr=searchindex_album','http://image.baidu.com/static/html/advanced.html','https://image.baidu.com/','http://image.baidu.com/']
数组中的所有外链
externalLinks-------------输出内容------------------['http://news.baidu.com/','https://www.hao123.com/','http://map.baidu.com/','https://haokan.baidu.com/?sfrom=baidu-top/','http://tieba.baidu.com/','https://xueshu.baidu.com/','http://www.baidu.com/more/','https://pan.baidu.com','https://zhidao.baidu.com','https://baike.baidu.com','https://baobao.baidu.com','https://wenku.baidu.com','https://jingyan.baidu.com','http://music.taihe.com','https://www.baidu.com','https://www.baidu.com/','http://www.baidu.com/duty/','http://www.baidu.com/search/image_help.html','http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000001','http://help.baidu.com/question','http://www.baidu.com/search/jubao.html','http://www.baidu.com/search/faq_image.html%2305']