在神经网络语言模型处理NLP领域,我做的研究一直都和文本分类相关,其实还有很多其他的应用领域,比方说:语言翻译、词性标注、命名实体识别等。感觉还是有必要了解一下如何用神经网络语言模型对这些应用进行建模的。因此,这几天看了几篇有关Neural Machine Translation(NMT)的论文,对这个领域基本有了比较全面、正确的认识。在这个过程中,正好学习了业界最流行的attention思想,下面我就来总结一下学习到的东西。

上图就是NMT的宏观流程,其中序列ABCD对应着一种语言,序列XYZ对应着意义和前面相同的另一种语言。符号代表着序列的结束标志。如果用S(source)代表原序列,用T(target)代表目标序列,那么我们最终的目标是max p(y | x),即给定义一个原序列s,求出使其概率最大的目标序列t。其实我们可以把原序列和对应的目标序列看成是一个pair对,那么对于一个大集合D中存在着很多这样的pair对,对于全局来说我们的目标损失函数就是: ∑ S , T ∈ D − log p ( t ∣ s ) \sum_{S,T\in D } -\log p(t|s) ∑S,T∈D−logp(t∣s)
一般来说,标准的NMT由2个component组成:encoder和decoder。其中encoder负责编码和提取原序列的信息,而decoder负责根据encoder的编码信息,翻译出对应的目标序列。假设长度为m的目标序列 y 1 y 2 y 3 . . . . . y m y_1 y_2 y_3 .....y_m y1y2y3.....ym,那么一对pair对应的概率函数为 ∑ j = 1 m log p ( y i ∣ y < j , S ) \sum_{j=1}^m {\log p(y_i|y<j,S)} ∑j=1mlogp(yi∣y<j,S),其中S为encoder对应生成的原句子生成的编码信息。
其实从上图中就可以看出来了,最终的目标序列的生成方式是依次生成的,因此,在decoder阶段一般使用RNN系列的变种模型。而各种模型的不同也就是在这部分的建模方式不同罢了。
首先讲的是一种比较基础的处理方式,参考论文《Sequence to Sequence Learning with Neural Networks》NIPS。现在来看他的思路就是非常简单明了了,他用的RNN变种是LSTM。在encoder部分就是因此输入序列元素,然后把最后一个输出C作为整个句子的表示。在decoder部分也是一样使用的LSTM,但是为了结合encoder所提取出的C向量,这里在decoder初始化其LSTM的hidden state的时候使用的是encoder最后的输出向量C。也就是说这个encoder编码出的向量C只在decoder过程中使用了一次,然后就是每次输入一个序列目标元素X,然后输出一个序列目标元素Y,知道输出最后的结束符号为止。google的大佬在实验的过程中,使用了3个小的trick:1 反转原序列的输入顺序(目标序列不变;2 使用了多层的LSTM;3 为了加快实验的训练速度,减少训练的时间,在min-batch训练阶段中,尽量使长度相仿的句子一起训练。我个人对反转原序列能提出翻译效果的普适性感到怀疑,因为他的实验数据有限,很可能只和他们用的那份实验数据有关,毕竟他们在论文里也没有给出很好的解释。
接下来的模型参考论文《Effective Approaches to Attention-based Neural Machine Translation》EMNLP。如题目所示,他使用了attention机制,下面我来大概讲一下attention机制的工作原理:上面的那个最简单的没有使用attention机制模型,在目标序列的生成阶段所参考的原序列的内容是不变的,也就是所有的目标词汇在生成的所考虑的原序列上下文是相同的,这显然是不合理的,因为不同的目标词汇所依赖的原序列不同位置词语的权值显然是在不断变化的。把这种变化考虑进来就是attention的基本思想。而这篇论文提出了两种attention方式,一种是local的,一种是global的,下面就来详细的讲一下这两种方式。
首先我们要明确的是,这篇论文提出的模型在encoder阶段这里同样使用的是LSTM模型,只不过它把所有的中间hidden state收集起来,然后做了一个加权求和,而这里权值向量 α \alpha α就是体现了attention思想的地方,因为在decoder生成不同目标词汇的时候,这个权值向量的值是在变化的,而由这些权值向量和encoder生成的hidden state序列加权求和后的结果 C t C_t Ct就可以作为decoder 在t时刻所对应的原序列向量编码。如果decoder在t时刻所对应的hidden state为 h t h_t ht 那么我们就定义 h t 1 = t a n h ( W c [ C t ; h t ] ) h_t^{1}=tanh(W_c[C_t;h_t]) ht1=tanh(Wc[Ct;ht])其中符号 [ C t ; h t ] [C_t;h_t] [Ct;ht]代表了向量的concatenation操作。那么就有了, p ( y t ∣ y < t , c t ) = s o f t m a x ( W s . h t 1 ) p(y_t|y<t,c_t)=softmax(W_s.h_t^{1}) p(yt∣y<t,ct)=softmax(Ws.ht1)。很容易看出来, C t C_t Ct向量生成是非常重要的。
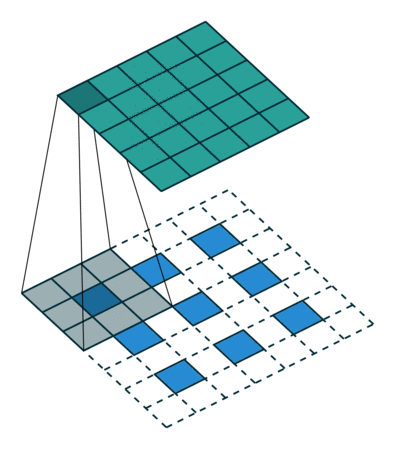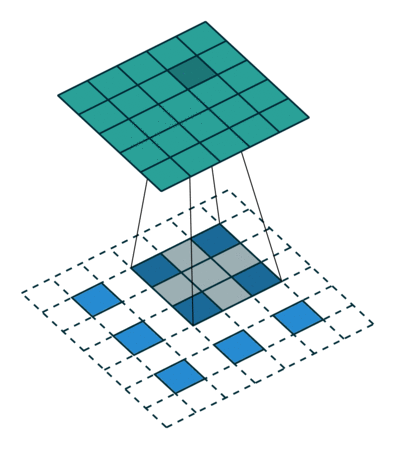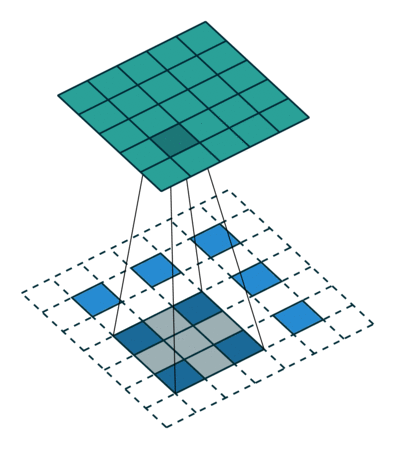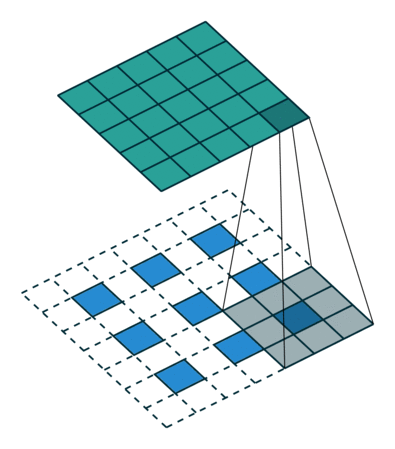
我们首先来讲一下global的方式。所谓global的方式,即在生成decoder所需要的原序列内容的时候,考虑了所有原序列的元素,其结构如下所示:
那么我们只需要计算decoder目前的hidden state h t h_t ht 和原序列各个位置的hidden state h s i h_s^i hsi 的相似度关系即可得出。 α t ( s ) = a l i g n ( h t , h s i ) = e x p ( s c o r e ( h t , h s i ) ) ∑ i e x p ( s c o r e ( h t , h s i ) ) \alpha_t(s)=align(h_t,h_s^i)=\frac{exp(score(h_t,h_s^i))}{\sum_iexp({score}(h_t,h_s^i))} αt(s)=align(ht,hsi)=∑iexp(score(ht,hsi))exp(score(ht,hsi))。那么对于score函数有下面几种选择,
接下来我们介绍一下local的方式,所谓local方式,即在生成decoder所需要的原序列内容的时候,只考虑了原序列的部分元素。
在细节上,模型在生成target中的第t序列的时候,生成一个变量 p t p_t pt,它代表了要考虑的source序列中的中间位置,然后前后各取 D D D个元素。这个 D D D是一个超参数,需要提前设置好。具体关于 p t p_t pt的生成算法,论文里也给了两参考的方式:1 就是直接认为 p t = t p_t=t pt=t,即认为source和target大致相当,剩下的权值计算方式和全局一致;2 就是根据公式 p t = S . s i g m o i d ( v p . t a n h ( W p . h t ) ) p_t=S.sigmoid(v_p.tanh(W_p.h_t)) pt=S.sigmoid(vp.tanh(Wp.ht)),其中 S S S代表了source序列长度, W p 和 V p W_p和V_p Wp和Vp是需要训练的参数,那么为了使这些参数可以通过反向传播算法以梯度下降的方式来训练,必须重新构造权值生成公式使其能包含这些参数, α t ( s ) = a l i g n ( h t , h s i ) . e x p ( − ( i − p t ) 2 2 δ 2 ) \alpha_t(s)=align(h_t,h_s^i).exp(-\frac{(i-p_t)^2}{2\delta^2}) αt(s)=align(ht,hsi).exp(−2δ2(i−pt)2),i代表了其在source中的位置,而 δ 则 一 般 取 D 2 \delta则一般取\frac{D}{2} δ则一般取2D。


在论文提出的结构中的decoder部分,采用的是RNN的变种LSTM,为了在每次生成target序列元素的时候能够充分考虑之前步骤的alignment的信息,采用了如下的结构:
即把前一步生成的 h t 1 h_t^{1} ht1和生成的元素X进行向量的向量的concatenation操作操作。

下面的模型参考了论文《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》ICLR会议。如题所示他使用了attention机制。只不过他使用的方式和上面那个不是太一样,其实大概原理都差不多,就是细节稍有不同,这里列举出来供大家参考。
可以看出在下面的encoder部分,该模型使用了bi-RNN来提取信息,这里面他使用的RNN变种是一种自己提出来的,可以看成是LSTM的简化版,具体公式在后面讲解。在decoder部分使用的是一样的RNN变种结构,而且他只有global一种方式,用y代表目标序列,用x代表原序列,那么有 p ( y i ∣ y 1 , y 2 , . . . . . y i − 1 , X ) = g ( y i − 1 , S i , C i ) p(y_i|y_1,y_2,.....y_{i-1},X)=g(y_{i-1},S_i,C_i) p(yi∣y1,y2,.....yi−1,X)=g(yi−1,Si,Ci),用函数f(x)来代表这个RNN变种结构,那么则有 S i = f ( S i − 1 , y i − 1 , C i ) S_i=f(S_{i-1},y_{i-1},C_i) Si=f(Si−1,yi−1,Ci),其具体公式如下
这里面的 z i z_i zi 被称之为update门, r i r_i ri 被称之为reset门。比之前的LSTM要简化一些。在计算 C i C_i Ci 即原序列的表示的时候的时候,所用的方式和《Effective Approaches to Attention-based Neural Machine Translation》中使用的相似,不过是由于该模型的 S i S_i Si 生成依赖了 C i C_i Ci,故使用的是 S i − 1 S_{i-1} Si−1 和原序列的h_i进行相似度的计算,具体这里不再赘述了。












![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)