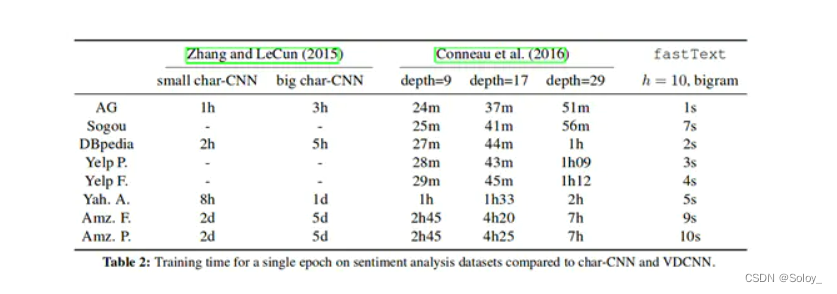
Fasttext
Paper
Fasttext特点
- 模型简单,只有一层的隐层以及输出层,因此训练速度非常快
- 不需要训练词向量,Fasttext自己会训练
- 两个优化:Hierarchical Softmax、N-gram
Fasttext模型架构
fastText模型架构和word2vec中的CBOW很相似, 不同之处是fastText预测标签而CBOW预测的是中间词,即模型架构类似但是模型的任务不同。
CBOW架构
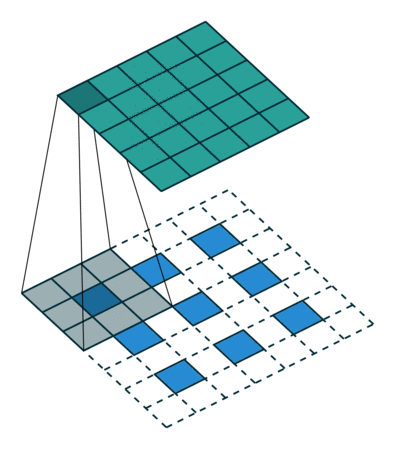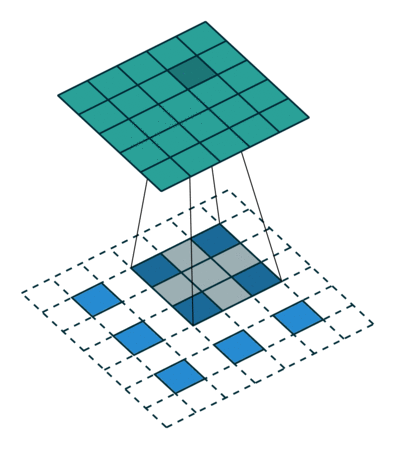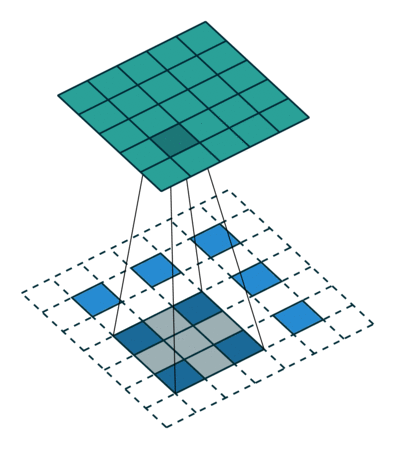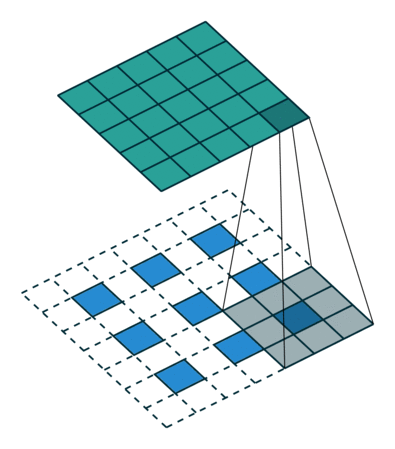
(1) word2vec将上下文关系转化为多分类任务,进而训练逻辑回归模型,这里的类别数量 V V V词库大小。
通常的文本数据中,词库少则数万,多则百万,在训练中直接训练多分类逻辑回归并不现实。
(2) word2vec中提供了两种针对大规模多分类问题的优化手段, negative sampling 和hierarchical softmax。在优化中,negative sampling 只更新少量负面类,从而减轻了计算量。hierarchical softmax 将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从|V|降低到了树的高度。整体的复杂度从。
Fasttext架构

fastText模型架构:其中 x 1 , x 2 , … , x N − 1 , x N x_1,x_2,…,x_{N−1},x_N x1,x2,…,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。
- x 1 , x 2 , … , x N − 1 , x N x_1,x_2,…,x_{N−1},x_N x1,x2,…,xN−1,xN一个句子的特征,初始值为随机生成也可以采用预训练的词向量
- hidden: X i X_i Xi 的平均值 x
- output: 样本标签
目标函数
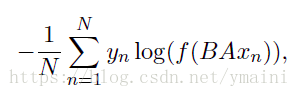
N N N:样本个数
y n y_n yn:第n个样本对应的类别
f f f:损失函数softmaxt
x n x_n xn:第n个样本的归一化特征
A A A:权重矩阵(构建词,embedding)
B B B:权重矩阵(隐层到输出层)
词向量初始化
一个句子的embedding为 [ i w 1 , i w 2 , … . i w n , o w 1 , o w 2 , … o w s ] [iw_1,iw_2,….iw_n,ow_1,ow_2,…ow_s] [iw1,iw2,….iwn,ow1,ow2,…ows]
i w i iw_i iwi:语料中出现的词,排在数组的前面
o w i ow_i owi:n-gram或n-char特征
初始化为随机数, 如果提供预训练的词向量,对应的词采用预训练的词向量
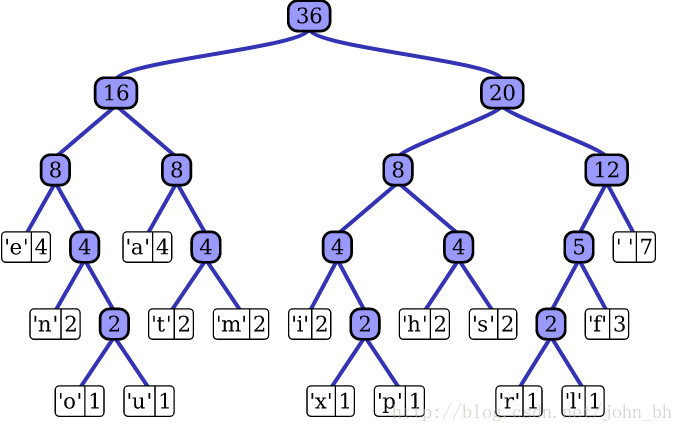
层次softmax
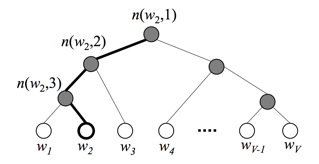
当语料类别较多时,使用hierarchical Softmax(hs)减轻计算量 hs利用Huffman 树实现,词生成词向量或label分类问题作为叶子节点 根据词或label的count构建Huffman树,则叶子到root一定存在一条路径利用逻辑回归二分类计算loss。
n-gram和n-char
Fasttext方法不同与word2vec方法,引入了两类特征并进行embedding。其中n-gram颗粒度是词与词之间,n-char是单个词之间。两类特征的存储均通过计算hash值的方法实现。
n-gram
示例: who am I? n-gram设置为2
n-gram特征有,who, who am, am, am I, I
n-char
示例: where, n=3, 设置起止符<, >
n-char特征有,<wh, whe, her, ere, er>
FastText词向量与word2vec对比
- 模型的输出层
- word2vec的输出层,对应下一个单词的概率最大值;fasttext的输出层是分类的label
- 模型的输入层:
- word2vec的输入层,是 context window 内的word;而fasttext 对应的整个sentence的内容,包括word,也包括 n-gram的内容;
代码
import fasttext
## 1 is positive, 0 is negativef = open('train.txt', 'w')
f.write('__label__1 i love you\n')
f.write('__label__1 he loves me\n')
f.write('__label__1 she likes baseball\n')
f.write('__label__0 i hate you\n')
f.write('__label__0 sorry for that\n')
f.write('__label__0 this is awful')
f.close()f = open('test.txt', 'w')
f.write('sorry hate you')
f.close()## 训练
trainDataFile = 'train.txt'classifier = fasttext.train_supervised(input=trainDataFile, ## 文件输入label_prefix='__label__', ## label前缀dim=2,# 词向量维度epoch=2, ## epoch次数lr=1, # 学习率lr_update_rate=50, # 多少步更新学习率min_count=1, # 最少的单词出现次数loss='softmax', ## loss function {ns, hs, softmax} [softmax] word_ngrams=2, # n-gram 窗口大小bucket=1000000) ## 叶子数## 保存模型
classifier.save_model("Model.bin")## 测试集测试testDataFile = 'test.txt'
classifier = fasttext.load_model('Model.bin')
result = classifier.test(testDataFile)
print ('测试集上数据量', result[0])
print ('测试集上准确率', result[1])
print ('测试集上召回率', result[2])res = classifier.predict(text=testDataFile)
print(res)
Fasttext 参数
The following arguments are mandatory:-input training file path-output output file pathThe following arguments are optional:-verbose verbosity level [2]The following arguments for the dictionary are optional:-minCount minimal number of word occurrences [1]-minCountLabel minimal number of label occurrences [0]-wordNgrams max length of word ngram [1]-bucket number of buckets [2000000]-minn min length of char ngram [0]-maxn max length of char ngram [0]-t sampling threshold [0.0001]-label labels prefix [__label__]The following arguments for training are optional:-lr learning rate [0.1]-lrUpdateRate change the rate of updates for the learning rate [100]-dim size of word vectors [100]-ws size of the context window [5]-epoch number of epochs [5]-neg number of negatives sampled [5]-loss loss function {ns, hs, softmax} [softmax]-thread number of threads [12]-pretrainedVectors pretrained word vectors for supervised learning []-saveOutput whether output params should be saved [0]The following arguments for quantization are optional:-cutoff number of words and ngrams to retain [0]-retrain finetune embeddings if a cutoff is applied [0]-qnorm quantizing the norm separately [0]-qout quantizing the classifier [0]-dsub size of each sub-vector [2]
![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)