JVM通常会额外分配内存。这些额外的分配,会导致java程序占用的内存,超出-Xmx的限制。让我们使用NMT查看内存的使用情况
NMT 是什么
NMT 是一种 Java Hotspot VM 功能,用于跟踪 HotSpot VM 的内部内存使用情况。您可以使用该jcmd实用程序访问 NMT 数据。NMT 不跟踪第三方本机代码和 Oracle Java Development Kit (JDK) 类库的内存分配。NMT 不包括MBeanHotSpot for Java Mission Control (JMC) 中的 NMT。
主要特征
Native Memory Tracking 与 jcmd一起使用时,可以在不同级别跟踪 Java 虚拟机 (JVM) 或 HotSpot VM 内存使用情况。NMT 仅跟踪 JVM 或 HotSpot VM 使用的内存,而不是用户的本机内存。NMT 没有提供类数据共享 (CDS) 存档使用的内存的完整信息。
NMT 支持以下功能:
生成摘要和详细报告。
为以后的比较建立早期基线。(基线是在特定时期的一个“快照”。)
使用 JVM 命令行选项在 JVM 退出时请求内存使用报告。
使用
HotSpot VM 的 NMT 默认关闭。
启用 NMT
语法:
-XX:NativeMemoryTracking=[off | summary | detail]
参数说明:
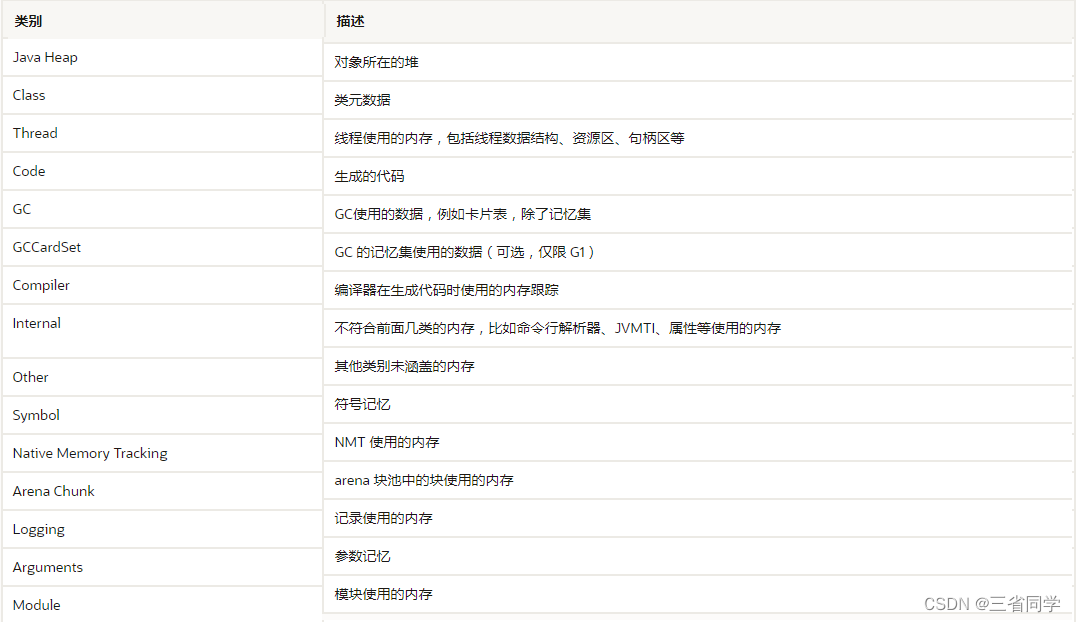
| NMT 选项 | 描述 |
|---|---|
off | NMT默认关闭。 |
summary | 仅收集子系统聚合的内存使用情况。 |
detail | 收集各个调用站点的内存使用情况。 |
java -XX:NativeMemoryTracking=detail -jar test.jar
注:启用 NMT 会导致 5% -10% 的性能开销。
未开启NMT,提示:
Native memory tracking is not enabled
[root@sanxingtongxue ~]# jcmd 513791 VM.native_memory
513791:
Native memory tracking is not enabled
使用 jcmd 访问 NMT 数据
jcmd收集转储数据,并可选择将数据与上一个基线进行比较。
语法:
jcmd <pid> VM.native_memory [summary | detail | baseline | summary.diff | detail.diff | shutdown] [scale= KB | MB | GB]
参数说明:
| jcmd NMT 选项 | 描述 |
|---|---|
summary | 打印按类别汇总的摘要。 |
detail |
|
baseline | 创建一个新的内存使用快照进行比较。 |
summary.diff | 根据最后一个基线打印一份新的总结报告。 |
detail.diff | 根据最后一个基线打印一份新的详细报告。 |
shutdown | 停止 NMT。 |
示例如下:
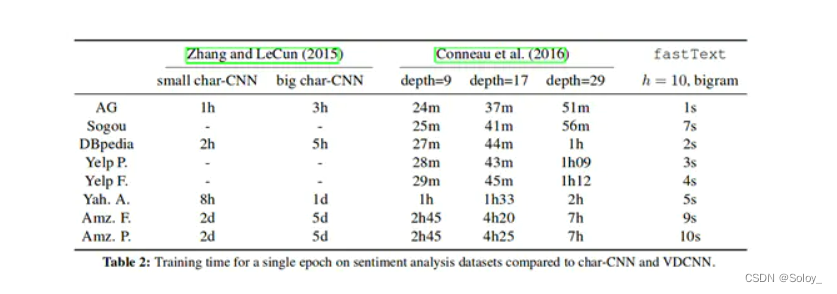
[root@sanxingtongxue ~]# jcmd 523265 VM.native_memory summary
523265:Native Memory Tracking:Total: reserved=1830732KB, committed=145464KB
- Java Heap (reserved=442368KB, committed=44060KB)(mmap: reserved=442368KB, committed=44060KB) - Class (reserved=1082480KB, committed=36464KB)(classes #6162)(malloc=1136KB #6847) (mmap: reserved=1081344KB, committed=35328KB) - Thread (reserved=29927KB, committed=29927KB)(thread #30)(stack: reserved=29792KB, committed=29792KB)(malloc=102KB #174) (arena=32KB #56)- Code (reserved=251447KB, committed=11795KB)(malloc=1847KB #3272) (mmap: reserved=249600KB, committed=9948KB) - GC (reserved=1473KB, committed=181KB)(malloc=25KB #126) (mmap: reserved=1448KB, committed=156KB) - Compiler (reserved=151KB, committed=151KB)(malloc=18KB #308) (arena=133KB #5)- Internal (reserved=11357KB, committed=11357KB)(malloc=11325KB #7724) (mmap: reserved=32KB, committed=32KB) - Symbol (reserved=9890KB, committed=9890KB)(malloc=6813KB #60966) (arena=3077KB #1)- Native Memory Tracking (reserved=1463KB, committed=1463KB)(malloc=180KB #2549) (tracking overhead=1283KB)- Arena Chunk (reserved=177KB, committed=177KB)(malloc=177KB)
结果参数说明:
Total Allocations
NMT显示总的预留内存、已提交内存:
Total: reserved=1830732KB, committed=145464KB
预留内存表示我们的应用程序可能使用的内存总量。已提交内存表示应用程序当前使用的内存。
Java Heap
heap内存占用情况显示如下:
Java Heap (reserved=442368KB, committed=44060KB)(mmap: reserved=442368KB, committed=44060KB)
Thread
线程内存分配情况如下:
Thread (reserved=29927KB, committed=29927KB)(thread #30)(stack: reserved=29792KB, committed=29792KB)(malloc=102KB #174) (arena=32KB #56)
30个线程,stack内存共计29M,差不多每个线程的stack占用1M。JVM在创建线程时,同时分配stack内存,所以预留内存和提交内存是一样的。
Code Cache
JIT生成并缓存的汇编指令的内存占用情况:
Code (reserved=251447KB, committed=11795KB)(malloc=1847KB #3272) (mmap: reserved=249600KB, committed=9948KB)
GC
GC内存占用情况如下:
GC (reserved=1473KB, committed=181KB)(malloc=25KB #126) (mmap: reserved=1448KB, committed=156KB)
Serial GC是一个简单的多的方法,当使用此方法时,配置方法如下:
java -XX:NativeMemoryTracking=summary -Xms300m -Xmx300m -XX:+UseSerialGC -jar test.jar
当然,我们不能仅根据内存消耗来决定选择什么GC算法,因为Serial GC的“stop-the-world”特性,可能会导致性能下降。
Symbol
symbol内存占用情况如下,如string table和constant pool:
Symbol (reserved=9890KB, committed=9890KB)(malloc=6813KB #60966) (arena=3077KB #1)
大概占用9M。
在 VM 退出时获取 NMT 数据
要在 VM 退出时获取上次内存使用情况的数据,请在启用本机内存跟踪时使用以下 VM 诊断命令行选项。详细程度基于跟踪级别。
-XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics
使用 NMT 检测内存泄漏
使用本机内存跟踪检测内存泄漏的过程。
请按照以下步骤检测内存泄漏:
- 使用命令行选项启动 JVM 并进行摘要或详细信息
-XX:NativeMemoryTracking=summary跟踪:-XX:NativeMemoryTracking=detail. - 建立早期基线。使用 NMT 基线功能通过运行以下命令在开发和维护期间获取要比较的基线:
jcmd <pid> VM.native_memory baseline. - 使用以下方法监视内存更改:
jcmd <pid> VM.native_memory detail.diff。 - 如果应用程序泄漏少量内存,则可能需要一段时间才能显示出来。
示例如下:
$ jcmd <pid> VM.native_memory baseline
Baseline succeeded
然后,过一段时间,可以将当前内存占用与基线做比较:
$ jcmd <pid> VM.native_memory summary.diff
NMT通过+ -符号,表示这段时间内,内存占用的变化情况:
[root@sanxingtongxue ~]# jcmd 523265 VM.native_memory summary.diff
523265:Native Memory Tracking:Total: reserved=1831059KB +359KB, committed=146815KB +1383KB- Java Heap (reserved=442368KB, committed=44060KB)(mmap: reserved=442368KB, committed=44060KB)- Class (reserved=1082518KB +38KB, committed=37526KB +1062KB)(classes #6372 +210)(malloc=1174KB +38KB #7083 +236)(mmap: reserved=1081344KB, committed=36352KB +1024KB)- Thread (reserved=29927KB, committed=29927KB)(thread #30)(stack: reserved=29792KB, committed=29792KB)(malloc=102KB #174)(arena=32KB #56)- Code (reserved=251480KB +34KB, committed=11828KB +34KB)(malloc=1880KB +34KB #3409 +137)(mmap: reserved=249600KB, committed=9948KB)- GC (reserved=1473KB, committed=181KB)(malloc=25KB #126)(mmap: reserved=1448KB, committed=156KB)- Compiler (reserved=161KB +10KB, committed=161KB +10KB)(malloc=28KB +10KB #334 +26)(arena=133KB #5)- Internal (reserved=11398KB +41KB, committed=11398KB +41KB)(malloc=11366KB +41KB #7936 +212)(mmap: reserved=32KB, committed=32KB)- Symbol (reserved=10046KB +156KB, committed=10046KB +156KB)(malloc=6969KB +156KB #62913 +1947)(arena=3077KB #1)- Native Memory Tracking (reserved=1511KB +81KB, committed=1511KB +81KB)(malloc=187KB +33KB #2645 +469)(tracking overhead=1325KB +47KB)- Arena Chunk (reserved=177KB, committed=177KB)(malloc=177KB)

三四更雪风不减吹袭一夜





![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)