前言
SMT是在神经网络之前最主流的翻译模式,统计机器翻译;NMT则是基于神经网络的翻译模式,也是当前效果最好的翻译模式。现在基于几篇paper来梳理下神经网络下的翻译模型。
NMT based RNN
1) First End-to-End RNN Trial
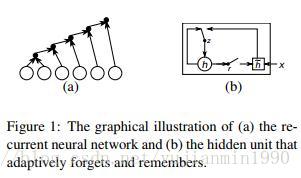
2014年,Cho首次将End-to-End的RNN结构应用到翻译领域,是以统计机器翻译模型为主,但是用NMT训练得到的短语对,来给SMT作新增特征。另外也是GRU第一次被提出的paper,就是图结构有点糙,GRU的结构比LSTM要简单。看不动就看下面的图。

2) Complete End-to-End RNN NMT
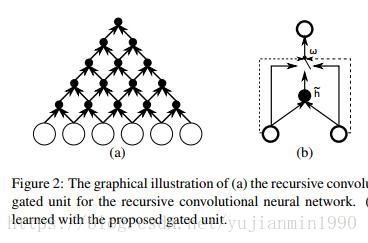
Properties of NMT是Learning Phrase的兄弟篇,也是Cho的同年佳作,首次以GRU和grConv【GRU的升级版本】实现End-to-End的NMT结构,并分析了NMT时的特性。
a) NMT在句子长度增加是,效果下降得厉害。
b) 词表长度对NMT有很大的影响。
c) grConv的NMT可以在无监督的情况下,学习到目标语言的语法结构。
其中对GRU和grConv【gated Recurrent Convolutional Network】的结构拆分非常有意思,如下图:
2014年, Sutskever 首次实现完整意义上的end-to-end的LSTM版本的NMT模型,两个Deep LSTM分别做encoder 和 decoder,其中,反转输入(target不动)训练会提高翻译效果。
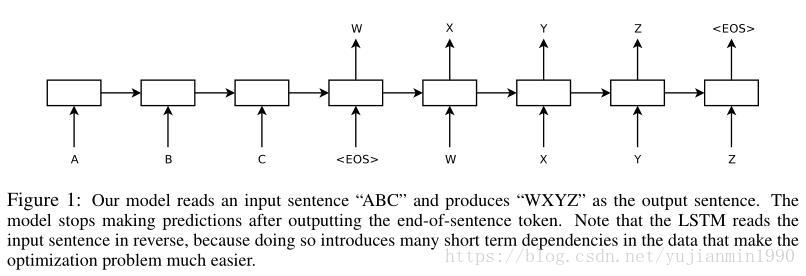
具体操作部分,out-of-vocabulary 作UNKNOWN词,评估是用beam-search 。并行在8张GPU上,每层在一个卡上。使用了 4层Deep LSTM,堆叠的LSTM结构,整体数据集迭代次数在8次以内。并且根据句子长短对minibatch作了 优化,长度基本一致的在一个batch内,防止空转计算。用了个 类似clicp-gradient的约束梯度爆炸的技巧。
notice 1:这个方法很好,就是训练太耗时,需要 10天的时间。
notice 2:不是补充训练,而是就用反转直接训练。【反转训练效果好的非正式解释:引入了许多短期依赖】
3) attention in NMT
这篇文章《NMT by Jointly Learning to Align and Translate》从14年就开始提交,7易其稿,一直到16年才完成最终版,看下作者Bahdanau和Cho,都是Bengio实验室的,已经产学研一条龙了。
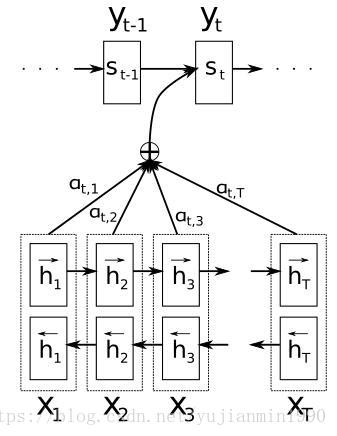

每个输入序列的词,都有个解释向量 hj h j ,其对当前预测词的贡献权重 α α 采用softmax方式计算,某个词对当前预测词的匹配度由 a a 来确定,所有输入序列中的词都通过对注意力向量 c c 作贡献。
好在有其他的研究文章可以来辅助确认模型细节,强烈推荐这篇,给出了Attention的基本结构类型说明,其开放源码。一个很好地介绍Attention的博客,后面会作为翻译博客。另外专门写篇博客,讨论NMT by Jointly Learning 与Effective Approaches to Attention-based NMT 和Show and Tell, Neural Image Generation with Visual Attention。
notice 1: Attenttion是一种思想,并不是一种模型,有很多变种attention方法Effective Approaches to Attention-based NMT,并且在翻译之外很多地方都有应用,比如图像描述:《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》,文本分类:《Hierarchical Attention Networks for Document Classification》,关系分类:《Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification》。
notice 2: 非常需要吐槽下NMT by Jointly Learning这篇文章,看似写得很清晰,但是你根据论文内容是没法回答下面两个问题的:
a) 为什么不能直接model化 yi y i 和 hj h j 的关系,而是绕道 si−1 s i − 1 和 hj h j 匹配度 ?
b) 无法确定 h h 和是否用同一个BiRNN来描述,即便有图也没法确认,更没有文字明确给出,只能看 源码。
关于第一点,有模糊地解释:“The probability αij α i j , or its associated energy eij e i j , reflects the importance of the annotation hj h j with respect to the previous hidden state si−1 s i − 1 in deciding the next state si s i and generating yi y i . Intuitively, this implements a mechanism of attention in the decoder.”,这种解释都是似是而非的, si−1 s i − 1 决定当前状态,那么为什么不包含 yi−1 y i − 1 呢?为什么不直接对 yi y i 和 hj h j 直接建模呢?
NMT in google
Google翻译这么拽,集合了attention机制,Deep机制,并且做了各种工程优化,非常值得一看。
NMT的三个主要缺陷:1)训练和推断速度慢。2)处理稀少词时会失效。3)有时翻译不能cover全部输入。
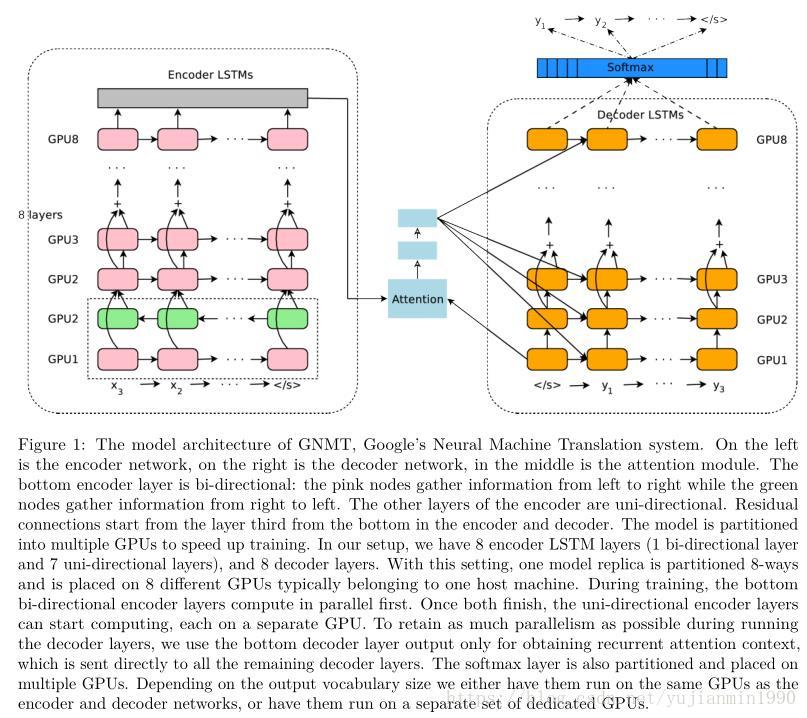
google的NMT作了很大的工程改进,具体如下,更具体见论文。
1) 8层LSTM分别作 Encoder和 Decoder,同时加以Residual Block以降低学习难度;
2) 使用Attention,仅连接Encoder的bottom层和Decoder的top层;
3) 用低精度的推断来加快翻译速度;
4) 为改善稀少词的处理,使用wordpiece,将单词拆成有限子集单元,极大地平衡了单字母的复杂性和完整单词的有效性,并且避开了对未知单词的处理;
5) 利用强化学习来改善翻译效果。
NMT based CNN
思考 与 总结
1) NMT大部分以Encoder-Decoder结构为基础结构。
2) 翻译模型特别喜欢bidirectional,注意其无法适应在线的缺陷。
3) Attention并不局限于翻译模型上,而是在各个地方都有应用。
4) NMT的训练耗时是个长久存在的问题,需要在工程中密切关注。
补充知识
1) 关于翻译结果的查找方法:Beam Search
如果直接搜索模型的最优路径,需要比较所有的可能路径,耗时耗力。Beam Search则每次选择Top-N个选项,相当于每次只对比当次所有输出,然后选择Top-N。

2) 关于翻译效果的评估方法: BLEU 和 Meteor
BLEU-2005是改进unigram-precision的改进版,是[1,n]-gram precision的几何平均值,通常 N=4 N = 4 足矣。 B B 是penalty,是候选翻译的平均长度, r r 是参考翻译的平均长度。
是修正的n-gram precision,候选翻译的n-gram 出现在任意参考翻译中的数量,除以总候选翻译的n-gram数量。
Meteor克服了BLEU的缺陷(在大量数据集评估上符合人类评估,但是单条间无法准确评估和比较),基于候选翻译和参考翻译之间的词与词的匹配。 P P 是precision,是recall。“M ∝ c/m where c is the smallest number of chunks of consecutive words such that the words are adjacent in both the candidate and the reference, and m is the total number of matched unigrams yielding the score”
Reference
2014 - 《Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation》
2014 - 《On the Properties of Neural Machine Translation, Encoder-Decoder Approaches》
2014 - 《Sequence to Sequence Learning with Neural Networks》
2016 - 《Neural Machine Translation by Jointly Learning to Align and Translate》
2015 - 《Effective Approaches to Attention-based Neural Machine Translate》建议重点阅读
2016 - 《 Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation》建议重点阅读







![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)