诸神缄默不语-个人CSDN博文目录
fastText Python官方GitHub文件夹网址:fastText/python at main · facebookresearch/fastText
本文介绍fastText Python包的基本教程,包括安装方式和简单的使用方式。
我看gensim也有对fasttext算法的支持(https://radimrehurek.com/gensim/models/fasttext.html),那个我以后可能会在写gensim相关博文的时候写吧。
本文所使用的示例中文文本分类数据来自https://raw.githubusercontent.com/SophonPlus/ChineseNlpCorpus/master/datasets/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv。除文中所做的工作外,还可以做停用词处理等其他工作。
其他fasttext Python示例代码可参考:fastText/python/doc/examples at master · facebookresearch/fastText
文章目录
- 1. 安装fastText
- 2. 训练和调用词向量模型
- 2.1 代码实现
- 2.2 原理介绍
- 3. 文本分类
- 3.1 代码实现
- 3.2 原理介绍
- 4. 量化实现模型压缩
- 5. 模型的属性和方法
- 6. 忽略警告
- 7. 其他在正文及脚注中未提及的参考资料
1. 安装fastText
首先需要安装numpy、scipy和pybind11。
numpy我是在安装PyTorch的时候,顺带着安装的。我使用的命令行是conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch。单独安装numpy可以参考使用conda install numpy。
安装SciPy:conda install scipy 或 pip install scipy
安装pybind11,参考官方文档:Installing the library — pybind11 documentation:conda install -c conda-forge pybind11 或 pip install pybind11
安装完前置包之后,安装fastText:pip install fasttext
我安装过两次fasttext,第一次就非常正常地走完上述所有环节就安装成功了;第二次我用阿里云服务器安装(因为觉得是个很简单的分类任务,不需要大动干戈上GPU,凑合用CPU就完了),结果先是报RuntimeError: Unsupported compiler -- at least C++11 support is needed!,我根据1用root运行了yum install gcc-c++,然后我一pip install fasttext就直接给我卡死了,IO直接满了,我设置命令行的IO权限最低也没用。
解决方案是改为下载wheel:pip install fasttext-wheel(这个包的pypi主页:https://pypi.org/project/fasttext-wheel/)
2. 训练和调用词向量模型
以前我用gensim做过。以后可以比较一下两个包的不同之处。
此外fasttext词向量论文中用的baseline是谷歌官方的word2vec包:Google Code Archive - Long-term storage for Google Code Project Hosting.
2.1 代码实现
官方详细教程:Word representations · fastText(使用的是英文维基百科的语料,本文的实验用的是中文语料)
由于fasttext本身没有中文分词功能,因此需要手动对文本预先分词。处理数据的代码可参考:
import csv,jieba
with open('data/cls/ChnSentiCorp_htl_all.csv') as f:reader=csv.reader(f)header = next(reader) #表头data = [[int(row[0]),row[1]] for row in reader] #每个元素是一个由字符串组成的列表,第一个元素是标签(01),第二个元素是评论文本。tofiledir='data/cls'
with open(tofiledir+'/corpus.txt','w') as f:f.writelines([' '.join(jieba.cut(row[1]))+'\n' for row in data])
文件效果:

学习词向量并展示的代码:
import fasttext
model=fasttext.train_unsupervised('data/cls/corpus.txt',model='skipgram') #model入参可以更换为`cbow`
print(model.words[:10]) #打印前10个单词
print(model[model.words[9]]) #打印第10个单词的词向量
(展示词向量也可以使用get_word_vector(word),而且可以查找数据中未出现的data(事实上词向量是用子字符串总和来表示的))
输出:
Read 0M words
Number of words: 6736
Number of labels: 0
Progress: 100.0% words/sec/thread: 71833 lr: 0.000000 avg.loss: 2.396854 ETA: 0h 0m 0s
[',', '的', '。', ',', '了', '酒店', '是', '</s>', '很', '房间']
[ 1.44523270e-02 -1.14391923e-01 -1.31457284e-01 -1.59686044e-01-4.57017310e-02 2.04045177e-01 2.00106978e-01 1.63031772e-011.71287894e-01 -2.93396801e-01 -1.01871997e-01 2.42363811e-012.78942972e-01 -4.99058776e-02 -1.27043173e-01 2.87460908e-023.73771787e-01 -1.69842303e-01 2.42533281e-01 -1.82482198e-017.33817369e-02 2.21920848e-01 2.17794716e-01 1.68730497e-012.16873884e-02 -3.15452456e-01 8.21631625e-02 -6.56387508e-029.51113254e-02 1.69942483e-01 1.13980576e-01 1.15132451e-013.28856230e-01 -4.43856061e-01 -5.13903908e-02 -1.74580872e-014.39242758e-02 -2.22267807e-01 -1.09185934e-01 -1.62346154e-012.11286068e-01 2.44934723e-01 -1.95910111e-02 2.33887792e-01-7.72107393e-02 -6.28366888e-01 -1.30844399e-01 1.01614185e-01-2.42928267e-02 4.28218693e-02 -3.78409088e-01 2.31552869e-013.49486321e-02 8.70033056e-02 -4.75800633e-01 5.37340902e-022.29140893e-02 3.87787819e-04 -5.77102527e-02 1.44286081e-031.33415654e-01 2.14263964e-02 9.26891491e-02 -2.24226922e-017.32692927e-02 -1.52607411e-01 -1.42978013e-01 -4.28122580e-029.64387357e-02 7.77726322e-02 -4.48957413e-01 -6.19397573e-02-1.22236833e-01 -6.12100661e-02 -5.51685333e-01 -1.35704070e-01-1.66864052e-01 7.26311505e-02 -4.55838069e-02 -5.94963729e-021.23811573e-01 6.13824800e-02 2.12341957e-02 -9.38200951e-02-1.40030123e-03 2.17677400e-01 -6.04508296e-02 -4.68601920e-022.30288744e-01 -2.68855840e-01 7.73726255e-02 1.22143216e-013.72817874e-01 -1.87924504e-01 -1.39104724e-01 -5.74962497e-01-2.42888659e-01 -7.35510439e-02 -6.01616681e-01 -2.18178451e-01]
检查词向量的效果:搜索其最近邻居(nearest neighbor (nn)),给出向量捕获语义信息的直觉观感(在教程中英文拼错了也能用,但是中文这咋试,算了)
(向量距离用余弦相似度计算得到)
print(model.get_nearest_neighbors('房间'))
输出:[(0.804237425327301, '小房间'), (0.7725597023963928, '房屋'), (0.7687026858329773, '尽头'), (0.7665393352508545, '第一间'), (0.7633816599845886, '但床'), (0.7551409006118774, '成旧'), (0.7520463466644287, '屋子里'), (0.750516414642334, '压抑'), (0.7492958903312683, '油漆味'), (0.7476236820220947, '知')]
word analogies(预测跟第三个词组成与前两个词之间关系的词):
print(model.get_analogies('房间','压抑','环境'))
输出:[(0.7665581703186035, '优越'), (0.7352521419525146, '地理位置'), (0.7330452799797058, '安静'), (0.7157530784606934, '周边环境'), (0.7050396800041199, '自然环境'), (0.6963807344436646, '服务到位'), (0.6960451602935791, '也好'), (0.6948464512825012, '优雅'), (0.6906660795211792, '地点'), (0.6869651079177856, '地理')]
其他函数:
model.save_model(path)fasttext.load_model(path)返回model
fasttext.train_unsupervised()其他参数:
dim向量维度(默认值是100,100-300都是常用值)minnmaxn最大和最小的subword子字符串(默认值是3-6)epoch(默认值是5)lr学习率高会更快收敛,但是可能过拟合(默认值是0.05,常见选择范围是 [0.01, 1] )thread(默认值是12)
input # training file path (required)model # unsupervised fasttext model {cbow, skipgram} [skipgram]lr # learning rate [0.05]dim # size of word vectors [100]ws # size of the context window [5]epoch # number of epochs [5]minCount # minimal number of word occurences [5]minn # min length of char ngram [3]maxn # max length of char ngram [6]neg # number of negatives sampled [5]wordNgrams # max length of word ngram [1]loss # loss function {ns, hs, softmax, ova} [ns]bucket # number of buckets [2000000]thread # number of threads [number of cpus]lrUpdateRate # change the rate of updates for the learning rate [100]t # sampling threshold [0.0001]verbose # verbose [2]
fastText官方提供已训练好的300维多语言词向量:Wiki word vectors · fastText 新版:Word vectors for 157 languages · fastText
2.2 原理介绍
在论文中如使用词向量,需要引用这篇文献:Enriching Word Vectors with Subword Information
skipgram和cbow应该不太需要介绍,这是NLP的常识知识。skipgram用一个随机选择的邻近词预测目标单词,cbow用上下文(在一个window内,比如加总向量)预测目标单词。
fasttext所使用的词向量兼顾了subword信息(用子字符串表征加总,作为整体的表征),比单使用word信息能获得更丰富的语义,运算速度更快,而且可以得到原语料中不存在的词语。
3. 文本分类
3.1 代码实现
官方详细教程:Text classification · fastText(官方教程使用的数据集是英文烹饪领域stackexchange数据集)
本文中介绍的是one-label的情况,如果想使用multi-label的范式,可参考官方教程中的相应部分:https://fasttext.cc/docs/en/supervised-tutorial.html#multi-label-classification,以及我撰写的另一篇博文:multi-class分类模型评估指标的定义、原理及其Python实现
首先将原始数据处理成fasttext分类格式(需要手动对中文分词,标签以__label__为开头)(由于fasttext只有训练代码和测试代码,所以我只分了训练集和测试集),代码可参考:
import csv,jieba,random
with open('data/cls/ChnSentiCorp_htl_all.csv') as f:reader=csv.reader(f)header = next(reader) #表头data = [[row[0],row[1]] for row in reader] #每个元素是一个由字符串组成的列表,第一个元素是标签(01),第二个元素是评论文本。tofiledir='data/cls'
#随机抽取80%训练集,20%测试集
random.seed(14560704)
random.shuffle(data)
split_point=int(len(data)*0.8)
with open(tofiledir+'/train.txt','w') as f:train_data=data[:split_point]f.writelines([' '.join(jieba.cut(row[1]))+' __label__'+row[0]+'\n' for row in train_data])
with open(tofiledir+'/test.txt','w') as f:test_data=data[split_point:]f.writelines([' '.join(jieba.cut(row[1]))+' __label__'+row[0]+'\n' for row in test_data])
文件示例:

训练分类模型,并进行测试,打印测试结果:
import fasttext
model=fasttext.train_supervised('data/cls/train.txt')
print(model.words[:10])
print(model.labels)print(model.test('data/cls/test.txt'))print(model.predict('酒店 环境 还 可以 , 服务 也 很 好 , 就是 房间 的 卫生 稍稍 马虎 了 一些 , 坐便器 擦 得 不是 十分 干净 , 其它 方面 都 还好 。 尤其 是 早餐 , 在 我 住 过 的 四星 酒店 里 算是 花样 比较 多 的 了 。 因为 游泳池 是 在 室外 , 所以 这个 季节 去 了 怕冷 的 人 就 没有 办法 游泳 。 补充 点评 2007 年 11 月 16 日 : 服务 方面 忘 了 说 一点 , 因为 我落 了 一样 小东西 在 酒店 , 还 以为 就算 了 , 没想到 昨天 离开 , 今天 就 收到 邮件 提醒 我 说 我 落 了 东西 , 问 我 需要 不 需要 他们 给 寄 回来 , 这 一点 比 有些 酒店 要 好 很多 。'))
输出:
Read 0M words
Number of words: 26133
Number of labels: 2
Progress: 100.0% words/sec/thread: 397956 lr: 0.000000 avg.loss: 0.353336 ETA: 0h 0m 0s
[',', '的', '。', ',', '了', '酒店', '是', '</s>', '很', '房间']
['__label__1', '__label__0']
(1554, 0.8783783783783784, 0.8783783783783784)
(('__label__1',), array([0.83198541]))
test()函数的输出依次是:样本数,precision@1,recall@1
(这个P@1大概意思是得分最高的标签属于正确标签的比例,可以参考:IR-ratio: Precision-at-1 and Reciprocal Rank。R@1是正确标签被预测到的概率)
predict()函数也可以传入字符串列表。
test()和predict()的入参k可以指定返回的标签数量,默认为1。
将训练好的模型储存到本地:model.save_model(saved_bin)
从本地加载训练好的模型:model=fasttext.load_model(saved_bin)
在加载时会报一个警告,可以忽略。可参考:Warning : load_model does not return WordVectorModel or SupervisedModel any more(fasttext 0.9.2) · Issue #1056 · facebookresearch/fastText
train_supervised()其他入参:
epoch(默认值为5)lr(效果好的范围为0.1-1)wordNgrams用n-gram而不是unigram(当使用语序很重要的分类任务(如情感分析)时很重要)bucketdimloss- 使用
hs(hierarchical softmax) 代替标准softmax,可以加速运行
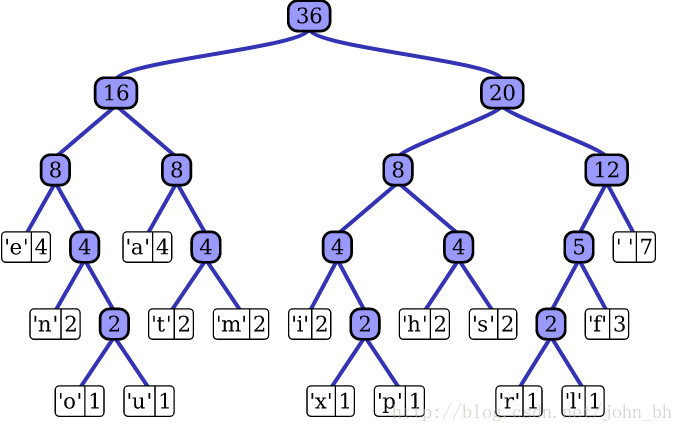
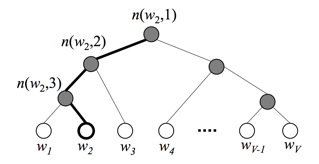
hierarchical softmax:看了一下没太看懂,总之大概来说是用二叉树来表示标签,这样复杂度就不呈线性增长而是呈对数增长了。fasttext中用的是哈夫曼树,平均查询时间最优。fasttext官方介绍:https://fasttext.cc/docs/en/supervised-tutorial.html#advanced-readers-hierarchical-softmax 此外还给出了一个YouTube讲解视频:Neural networks [10.7] : Natural language processing - hierarchical output layer - YouTube one-vs-all或ova:multi-label范式,将每个标签都单独建模成一个one-label分类任务(相比其他损失函数,建议调低学习率。predict()时指定k=-1输出尽量多的预测结果,threshold规定输出大于阈值的标签。test()时直接指定k=-1)
- 使用
input # training file path (required)lr # learning rate [0.1]dim # size of word vectors [100]ws # size of the context window [5]epoch # number of epochs [5]minCount # minimal number of word occurences [1]minCountLabel # minimal number of label occurences [1]minn # min length of char ngram [0]maxn # max length of char ngram [0]neg # number of negatives sampled [5]wordNgrams # max length of word ngram [1]loss # loss function {ns, hs, softmax, ova} [softmax]bucket # number of buckets [2000000]thread # number of threads [number of cpus]lrUpdateRate # change the rate of updates for the learning rate [100]t # sampling threshold [0.0001]label # label prefix ['__label__']verbose # verbose [2]pretrainedVectors # pretrained word vectors (.vec file) for supervised learning []
3.2 原理介绍
在论文中如使用文本分类功能需引用该文献:Bag of Tricks for Efficient Text Classification
感觉是个比较直觉的简单模型,计算词向量后求平均值,计算输出标签。具体细节待补。
4. 量化实现模型压缩
# with the previously trained `model` object, call :
model.quantize(input='data.train.txt', retrain=True)# then display results and save the new model :
print_results(*model.test(valid_data))
model.save_model("model_filename.ftz")
5. 模型的属性和方法

方法:
get_dimension # Get the dimension (size) of a lookup vector (hidden layer).# This is equivalent to `dim` property.get_input_vector # Given an index, get the corresponding vector of the Input Matrix.get_input_matrix # Get a copy of the full input matrix of a Model.get_labels # Get the entire list of labels of the dictionary# This is equivalent to `labels` property.get_line # Split a line of text into words and labels.get_output_matrix # Get a copy of the full output matrix of a Model.get_sentence_vector # Given a string, get a single vector represenation. This function# assumes to be given a single line of text. We split words on# whitespace (space, newline, tab, vertical tab) and the control# characters carriage return, formfeed and the null character.get_subword_id # Given a subword, return the index (within input matrix) it hashes to.get_subwords # Given a word, get the subwords and their indicies.get_word_id # Given a word, get the word id within the dictionary.get_word_vector # Get the vector representation of word.get_words # Get the entire list of words of the dictionary# This is equivalent to `words` property.is_quantized # whether the model has been quantizedpredict # Given a string, get a list of labels and a list of corresponding probabilities.quantize # Quantize the model reducing the size of the model and it's memory footprint.save_model # Save the model to the given pathtest # Evaluate supervised model using file given by pathtest_label # Return the precision and recall score for each label.
model.words # equivalent to model.get_words()
model.labels # equivalent to model.get_labels()
model['king'] # equivalent to model.get_word_vector('king')
'king' in model # equivalent to `'king' in model.get_words()`
6. 忽略警告
在调用本地存储的文本分类模型checkpoint(model=fasttext.load_model(model_path))时会报这个警告:
Warning : `load_model` does not return WordVectorModel or SupervisedModel any more, but a `FastText` object which is very similar.
解决方案是:
try:# silences warnings as the package does not properly use the python 'warnings' package# see https://github.com/facebookresearch/fastText/issues/1056fasttext.FastText.eprint = lambda *args,**kwargs: None
except:pass
7. 其他在正文及脚注中未提及的参考资料
- NLP实战之Fasttext中文文本分类_vivian_ll的博客-CSDN博客_fasttext 中文:这一篇去除了停用词,此外还介绍了gensim包中计算词向量的方法。
- [原创]《使用 fastText 做中文文本分类》文章合集 – 编码无悔 / Intent & Focused:这一篇是使用Java做的,因为数据量很大,所以想用map-reduce实现。数据标签是通过腾讯云文本分类免费API来调取得到的……
- 关于文本分类(情感分析)的中文数据集汇总_樱与刀的博客-CSDN博客_情感分析数据集
- Python3读取CSV数据_柿子镭的博客-CSDN博客_python3读取csv文件
- python读取csv时skipinitialspace参数的使用_vanlywang的博客-CSDN博客
- Warning :
load_modeldoes not return WordVectorModel or SupervisedModel any more, but aFastText_GodGump的博客-CSDN博客:这篇解决方案跟我文中提及的参考资料是相同的
Cannot install fastText because gcc 7.3.1 does not support C++11 on Amazon Linux - Stack Overflow
Python 编译错误 Unsupported compiler – at least C++11 support is needed! 解决方案 - 码农教程 ↩︎



![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)