1.数据准备
termcolor.colered 对输出进行染色,凸显。colored(f"tokenize('hello'): ", 'green')
from termcolor import colored
import random
import numpy as npimport trax
from trax import layers as tl
from trax.fastmath import numpy as fastnp
from trax.supervised import training!pip list | grep trax#generator for train and eval
train_stream_fn = trax.data.TFDS('opus/medical',data_dir='./data/',keys=('en', 'de'),eval_holdout_size=0.01, # 1% for evaltrain=True)# Get generator function for the eval set
eval_stream_fn = trax.data.TFDS('opus/medical',data_dir='./data/',keys=('en', 'de'),eval_holdout_size=0.01, # 1% for evaltrain=False)#tokenize
# global variables that state the filename and directory of the vocabulary file
VOCAB_FILE = 'ende_32k.subword'
VOCAB_DIR = 'data/'# Tokenize the dataset.
tokenized_train_stream = trax.data.Tokenize(vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR)(train_stream)
tokenized_eval_stream = trax.data.Tokenize(vocab_file=VOCAB_FILE, vocab_dir=VOCAB_DIR)(eval_stream)#append EOS for each sentence
EOS = 1# generator helper function to append EOS to each sentence
def append_eos(stream):for (inputs, targets) in stream:inputs_with_eos = list(inputs) + [EOS]targets_with_eos = list(targets) + [EOS]yield np.array(inputs_with_eos), np.array(targets_with_eos)# append EOS to the train data
tokenized_train_stream = append_eos(tokenized_train_stream)# append EOS to the eval data
tokenized_eval_stream = append_eos(tokenized_eval_stream)# Filter too long sentences to not run out of memory.
# length_keys=[0, 1] means we filter both English and German sentences, so
# both much be not longer that 256 tokens for training / 512 for eval.
filtered_train_stream = trax.data.FilterByLength(max_length=256, length_keys=[0, 1])(tokenized_train_stream)
filtered_eval_stream = trax.data.FilterByLength(max_length=512, length_keys=[0, 1])(tokenized_eval_stream)# print a sample input-target pair of tokenized sentences
train_input, train_target = next(filtered_train_stream)#build helper func(tokenize & detokenize)
def tokenize(input_str, vocab_file=None, vocab_dir=None):"""Encodes a string to an array of integersArgs:input_str (str): human-readable string to encodevocab_file (str): filename of the vocabulary text filevocab_dir (str): path to the vocabulary fileReturns:numpy.ndarray: tokenized version of the input string"""# Set the encoding of the "end of sentence" as 1EOS = 1# Use the trax.data.tokenize method. It takes streams and returns streams,# we get around it by making a 1-element stream with `iter`.inputs = next(trax.data.tokenize(iter([input_str]),vocab_file=vocab_file, vocab_dir=vocab_dir))# Mark the end of the sentence with EOSinputs = list(inputs) + [EOS]# Adding the batch dimension to the front of the shapebatch_inputs = np.reshape(np.array(inputs), [1, -1])return batch_inputsdef detokenize(integers, vocab_file=None, vocab_dir=None):"""Decodes an array of integers to a human readable stringArgs:integers (numpy.ndarray): array of integers to decodevocab_file (str): filename of the vocabulary text filevocab_dir (str): path to the vocabulary fileReturns:str: the decoded sentence."""# Remove the dimensions of size 1integers = list(np.squeeze(integers))# Set the encoding of the "end of sentence" as 1EOS = 1# Remove the EOS to decode only the original tokensif EOS in integers:integers = integers[:integers.index(EOS)] return trax.data.detokenize(integers, vocab_file=vocab_file, vocab_dir=vocab_dir)#build different length buckets for save the memory
# Buckets are defined in terms of boundaries and batch sizes.
# Batch_sizes[i] determines the batch size for items with length < boundaries[i]
# So below, we'll take a batch of 256 sentences of length < 8, 128 if length is
# between 8 and 16, and so on -- and only 2 if length is over 512.
boundaries = [8, 16, 32, 64, 128, 256, 512]
batch_sizes = [256, 128, 64, 32, 16, 8, 4, 2]# Create the generators.
train_batch_stream = trax.data.BucketByLength(boundaries, batch_sizes,length_keys=[0, 1] # As before: count inputs and targets to length.
)(filtered_train_stream)eval_batch_stream = trax.data.BucketByLength(boundaries, batch_sizes,length_keys=[0, 1] # As before: count inputs and targets to length.
)(filtered_eval_stream)# Add masking for the padding (0s).
train_batch_stream = trax.data.AddLossWeights(id_to_mask=0)(train_batch_stream)
eval_batch_stream = trax.data.AddLossWeights(id_to_mask=0)(eval_batch_stream)2.模型

def input_encoder_fn(input_vocab_size, d_model, n_encoder_layers):""" Input encoder runs on the input sentence and createsactivations that will be the keys and values for attention.Args:input_vocab_size: int: vocab size of the inputd_model: int: depth of embedding (n_units in the LSTM cell)n_encoder_layers: int: number of LSTM layers in the encoderReturns:tl.Serial: The input encoder"""# create a serial networkinput_encoder = tl.Serial( ### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### create an embedding layer to convert tokens to vectorstl.Embedding(vocab_size=input_vocab_size,d_feature=d_model),# feed the embeddings to the LSTM layers. It is a stack of n_encoder_layers LSTM layers[tl.LSTM(n_units=d_model) for _ in range(n_encoder_layers)]### END CODE HERE ###)return input_encoder 
def pre_attention_decoder_fn(mode, target_vocab_size, d_model):""" Pre-attention decoder runs on the targets and createsactivations that are used as queries in attention.Args:mode: str: 'train' or 'eval'target_vocab_size: int: vocab size of the targetd_model: int: depth of embedding (n_units in the LSTM cell)Returns:tl.Serial: The pre-attention decoder"""# create a serial networkpre_attention_decoder = tl.Serial(### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### shift right to insert start-of-sentence token and implement# teacher forcing during trainingtl.ShiftRight(),# run an embedding layer to convert tokens to vectorstl.Embedding(vocab_size=target_vocab_size,d_feature=d_model),# feed to an LSTM layertl.LSTM(n_units=d_model)### END CODE HERE ###)return pre_attention_decoderdef prepare_attention_input(encoder_activations, decoder_activations, inputs):"""Prepare queries, keys, values and mask for attention.Args:encoder_activations fastnp.array(batch_size, padded_input_length, d_model): output from the input encoderdecoder_activations fastnp.array(batch_size, padded_input_length, d_model): output from the pre-attention decoderinputs fastnp.array(batch_size, padded_input_length): padded input tokensReturns:queries, keys, values and mask for attention."""### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### set the keys and values to the encoder activationskeys = encoder_activationsvalues = encoder_activations# set the queries to the decoder activationsqueries = decoder_activations# generate the mask to distinguish real tokens from padding# hint: inputs is 1 for real tokens and 0 where they are paddingmask = 1 - fastnp.equal(inputs,0)### END CODE HERE #### add axes to the mask for attention heads and decoder length.mask = fastnp.reshape(mask, (mask.shape[0], 1, 1, mask.shape[1]))# broadcast so mask shape is [batch size, attention heads, decoder-len, encoder-len].# note: for this assignment, attention heads is set to 1.mask = mask + fastnp.zeros((1, 1, decoder_activations.shape[1], 1))return queries, keys, values, mask 
def NMTAttn(input_vocab_size=33300,target_vocab_size=33300,d_model=1024,n_encoder_layers=2,n_decoder_layers=2,n_attention_heads=4,attention_dropout=0.0,mode='train'):"""Returns an LSTM sequence-to-sequence model with attention.The input to the model is a pair (input tokens, target tokens), e.g.,an English sentence (tokenized) and its translation into German (tokenized).Args:input_vocab_size: int: vocab size of the inputtarget_vocab_size: int: vocab size of the targetd_model: int: depth of embedding (n_units in the LSTM cell)n_encoder_layers: int: number of LSTM layers in the encodern_decoder_layers: int: number of LSTM layers in the decoder after attentionn_attention_heads: int: number of attention headsattention_dropout: float, dropout for the attention layermode: str: 'train', 'eval' or 'predict', predict mode is for fast inferenceReturns:A LSTM sequence-to-sequence model with attention."""### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### Step 0: call the helper function to create layers for the input encoderinput_encoder = input_encoder_fn(input_vocab_size, d_model, n_encoder_layers)# Step 0: call the helper function to create layers for the pre-attention decoderpre_attention_decoder = pre_attention_decoder_fn(mode, target_vocab_size, d_model)# Step 1: create a serial networkmodel = tl.Serial( # Step 2: copy input tokens and target tokens as they will be needed later.tl.Select([0,1,0,1]),# Step 3: run input encoder on the input and pre-attention decoder the target.tl.Parallel(input_encoder, pre_attention_decoder),# Step 4: prepare queries, keys, values and mask for attention.tl.Fn('PrepareAttentionInput', f=prepare_attention_input, n_out=4),# Step 5: run the AttentionQKV layer# nest it inside a Residual layer to add to the pre-attention decoder activations(i.e. queries)tl.Residual(tl.AttentionQKV(d_model, n_heads=n_attention_heads, dropout=attention_dropout, mode=mode)),# Step 6: drop attention mask (i.e. index = Nonetl.Select([0,2]),# Step 7: run the rest of the RNN decoder[tl.LSTM(n_units=d_model) for _ in range(n_decoder_layers)],# Step 8: prepare output by making it the right sizetl.Dense(n_units=target_vocab_size),# Step 9: Log-softmax for outputtl.LogSoftmax())### END CODE HEREreturn model3.训练
train_task = training.TrainTask(### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### use the train batch stream as labeled datalabeled_data= train_batch_stream ,# use the cross entropy lossloss_layer= tl.CrossEntropyLoss(),# use the Adam optimizer with learning rate of 0.01optimizer= trax.optimizers.Adam(0.01),# use the `trax.lr.warmup_and_rsqrt_decay` as the learning rate schedule# have 1000 warmup steps with a max value of 0.01lr_schedule= trax.lr.warmup_and_rsqrt_decay(n_warmup_steps=1000,max_value=0.01),# have a checkpoint every 10 stepsn_steps_per_checkpoint= 10,### END CODE HERE ###
)eval_task = training.EvalTask(## use the eval batch stream as labeled datalabeled_data=eval_batch_stream,## use the cross entropy loss and accuracy as metricsmetrics=[tl.CrossEntropyLoss(), tl.Accuracy()],
)training_loop = training.Loop(NMTAttn(mode='train'),train_task,eval_tasks=[eval_task],output_dir=output_dir)training_loop.run(10)4.测试
def logsoftmax_sample(log_probs, temperature=1.0): # pylint: disable=invalid-name"""Returns a sample from a log-softmax output, with temperature.Args:log_probs: Logarithms of probabilities (often coming from LogSofmax)temperature: For scaling before sampling (1.0 = default, 0.0 = pick argmax)"""# This is equivalent to sampling from a softmax with temperature.u = np.random.uniform(low=1e-6, high=1.0 - 1e-6, size=log_probs.shape)g = -np.log(-np.log(u))return np.argmax(log_probs + g * temperature, axis=-1)def next_symbol(NMTAttn, input_tokens, cur_output_tokens, temperature):"""Returns the index of the next token.Args:NMTAttn (tl.Serial): An LSTM sequence-to-sequence model with attention.input_tokens (np.ndarray 1 x n_tokens): tokenized representation of the input sentencecur_output_tokens (list): tokenized representation of previously translated wordstemperature (float): parameter for sampling ranging from 0.0 to 1.0.0.0: same as argmax, always pick the most probable token1.0: sampling from the distribution (can sometimes say random things)Returns:int: index of the next token in the translated sentencefloat: log probability of the next symbol"""### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### set the length of the current output tokenstoken_length = len(cur_output_tokens)# calculate next power of 2 for padding length padded_length = 2**int(np.ceil(np.log2(token_length + 1)))# pad cur_output_tokens up to the padded_lengthpadded = cur_output_tokens + [0]*(padded_length-token_length)# model expects the output to have an axis for the batch size in front so# convert `padded` list to a numpy array with shape (x, <padded_length>) where the# x position is the batch axis. (hint: you can use np.expand_dims() with axis=0 to insert a new axis)padded_with_batch = np.expand_dims(np.array(padded),axis=0)# get the model prediction. remember to use the `NMAttn` argument defined above.# hint: the model accepts a tuple as input (e.g. `my_model((input1, input2))`)output, _ = NMTAttn((input_tokens,padded_with_batch))# get log probabilities from the last token outputlog_probs = output[0,token_length,:]# get the next symbol by getting a logsoftmax sample (*hint: cast to an int)symbol = int(tl.logsoftmax_sample(log_probs, temperature))### END CODE HERE ###return symbol, float(log_probs[symbol])def sampling_decode(input_sentence, NMTAttn = None, temperature=0.0, vocab_file=None, vocab_dir=None):"""Returns the translated sentence.Args:input_sentence (str): sentence to translate.NMTAttn (tl.Serial): An LSTM sequence-to-sequence model with attention.temperature (float): parameter for sampling ranging from 0.0 to 1.0.0.0: same as argmax, always pick the most probable token1.0: sampling from the distribution (can sometimes say random things)vocab_file (str): filename of the vocabularyvocab_dir (str): path to the vocabulary fileReturns:tuple: (list, str, float)list of int: tokenized version of the translated sentencefloat: log probability of the translated sentencestr: the translated sentence"""### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### encode the input sentenceinput_tokens = tokenize(input_sentence, vocab_file=vocab_file, vocab_dir=vocab_dir)# initialize the list of output tokenscur_output_tokens = []# initialize an integer that represents the current output indexcur_output = 0# Set the encoding of the "end of sentence" as 1EOS = 1# check that the current output is not the end of sentence tokenwhile cur_output != EOS:# update the current output token by getting the index of the next word (hint: use next_symbol)cur_output, log_prob = next_symbol(NMTAttn, input_tokens, cur_output_tokens, temperature)# append the current output token to the list of output tokenscur_output_tokens.append(cur_output)# detokenize the output tokenssentence = detokenize(cur_output_tokens,vocab_file=vocab_file, vocab_dir=vocab_dir)### END CODE HERE ###return cur_output_tokens, log_prob, sentencedef greedy_decode_test(sentence, NMTAttn=None, vocab_file=None, vocab_dir=None):"""Prints the input and output of our NMTAttn model using greedy decodeArgs:sentence (str): a custom string.NMTAttn (tl.Serial): An LSTM sequence-to-sequence model with attention.vocab_file (str): filename of the vocabularyvocab_dir (str): path to the vocabulary fileReturns:str: the translated sentence"""_,_, translated_sentence = sampling_decode(sentence, NMTAttn, vocab_file=vocab_file, vocab_dir=vocab_dir)print("English: ", sentence)print("German: ", translated_sentence)return translated_sentence生成多个样本进行比较
def generate_samples(sentence, n_samples, NMTAttn=None, temperature=0.6, vocab_file=None, vocab_dir=None):"""Generates samples using sampling_decode()Args:sentence (str): sentence to translate.n_samples (int): number of samples to generateNMTAttn (tl.Serial): An LSTM sequence-to-sequence model with attention.temperature (float): parameter for sampling ranging from 0.0 to 1.0.0.0: same as argmax, always pick the most probable token1.0: sampling from the distribution (can sometimes say random things)vocab_file (str): filename of the vocabularyvocab_dir (str): path to the vocabulary fileReturns:tuple: (list, list)list of lists: token list per samplelist of floats: log probability per sample"""# define lists to contain samples and probabilitiessamples, log_probs = [], []# run a for loop to generate n samplesfor _ in range(n_samples):# get a sample using the sampling_decode() functionsample, logp, _ = sampling_decode(sentence, NMTAttn, temperature, vocab_file=vocab_file, vocab_dir=vocab_dir)# append the token list to the samples listsamples.append(sample)# append the log probability to the log_probs listlog_probs.append(logp)return samples, log_probs#相似度比较--jaccard
def jaccard_similarity(candidate, reference):"""Returns the Jaccard similarity between two token listsArgs:candidate (list of int): tokenized version of the candidate translationreference (list of int): tokenized version of the reference translationReturns:float: overlap between the two token lists"""# convert the lists to a set to get the unique tokenscan_unigram_set, ref_unigram_set = set(candidate), set(reference) # get the set of tokens common to both candidate and referencejoint_elems = can_unigram_set.intersection(ref_unigram_set)# get the set of all tokens found in either candidate or referenceall_elems = can_unigram_set.union(ref_unigram_set)# divide the number of joint elements by the number of all elementsoverlap = len(joint_elems) / len(all_elems)return overlap#相似度比较--rougel-1
from collections import Counterdef rouge1_similarity(system, reference):"""Returns the ROUGE-1 score between two token listsArgs:system (list of int): tokenized version of the system translationreference (list of int): tokenized version of the reference translationReturns:float: overlap between the two token lists""" ### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### make a frequency table of the system tokens (hint: use the Counter class)sys_counter = Counter(system)# make a frequency table of the reference tokens (hint: use the Counter class)ref_counter = Counter(reference)# initialize overlap to 0overlap = 0# run a for loop over the sys_counter object (can be treated as a dictionary)for token in sys_counter:# lookup the value of the token in the sys_counter dictionary (hint: use the get() method)token_count_sys = sys_counter.get(token,0)# lookup the value of the token in the ref_counter dictionary (hint: use the get() method)token_count_ref = ref_counter.get(token,0)# update the overlap by getting the smaller number between the two token counts aboveoverlap += min(token_count_sys,token_count_ref)# get the precision (i.e. number of overlapping tokens / number of system tokens)precision = overlap/len(system)# get the recall (i.e. number of overlapping tokens / number of reference tokens)recall = overlap/len(reference)if precision + recall != 0:# compute the f1-scorerouge1_score = 2*(precision*recall)/(precision+recall)else:rouge1_score = 0 ### END CODE HERE ###return rouge1_scoredef average_overlap(similarity_fn, samples, *ignore_params):"""Returns the arithmetic mean of each candidate sentence in the samplesArgs:similarity_fn (function): similarity function used to compute the overlapsamples (list of lists): tokenized version of the translated sentences*ignore_params: additional parameters will be ignoredReturns:dict: scores of each samplekey: index of the samplevalue: score of the sample""" # initialize dictionaryscores = {}# run a for loop for each samplefor index_candidate, candidate in enumerate(samples): ### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### initialize overlap to 0.0overlap = 0.0# run a for loop for each samplefor index_sample, sample in enumerate(samples): # skip if the candidate index is the same as the sample indexif index_candidate == index_sample:continue# get the overlap between candidate and sample using the similarity functionsample_overlap = similarity_fn(candidate, sample)# add the sample overlap to the total overlapoverlap += sample_overlap# get the score for the candidate by computing the averagescore = overlap/(len(samples)-1)# save the score in the dictionary. use index as the key.scores[index_candidate] = score### END CODE HERE ###return scoresdef weighted_avg_overlap(similarity_fn, samples, log_probs):"""Returns the weighted mean of each candidate sentence in the samplesArgs:samples (list of lists): tokenized version of the translated sentenceslog_probs (list of float): log probability of the translated sentencesReturns:dict: scores of each samplekey: index of the samplevalue: score of the sample"""# initialize dictionaryscores = {}# run a for loop for each samplefor index_candidate, candidate in enumerate(samples): # initialize overlap and weighted sumoverlap, weight_sum = 0.0, 0.0# run a for loop for each samplefor index_sample, (sample, logp) in enumerate(zip(samples, log_probs)):# skip if the candidate index is the same as the sample index if index_candidate == index_sample:continue# convert log probability to linear scalesample_p = float(np.exp(logp))# update the weighted sumweight_sum += sample_p# get the unigram overlap between candidate and samplesample_overlap = similarity_fn(candidate, sample)# update the overlapoverlap += sample_p * sample_overlap# get the score for the candidatescore = overlap / weight_sum# save the score in the dictionary. use index as the key.scores[index_candidate] = scorereturn scores##将所有的函数汇总
def mbr_decode(sentence, n_samples, score_fn, similarity_fn, NMTAttn=None, temperature=0.6, vocab_file=None, vocab_dir=None):"""Returns the translated sentence using Minimum Bayes Risk decodingArgs:sentence (str): sentence to translate.n_samples (int): number of samples to generatescore_fn (function): function that generates the score for each samplesimilarity_fn (function): function used to compute the overlap between a pair of samplesNMTAttn (tl.Serial): An LSTM sequence-to-sequence model with attention.temperature (float): parameter for sampling ranging from 0.0 to 1.0.0.0: same as argmax, always pick the most probable token1.0: sampling from the distribution (can sometimes say random things)vocab_file (str): filename of the vocabularyvocab_dir (str): path to the vocabulary fileReturns:str: the translated sentence"""### START CODE HERE (REPLACE INSTANCES OF `None` WITH YOUR CODE) #### generate samplessamples, log_probs = generate_samples(sentence, n_samples, NMTAttn=NMTAttn, temperature=temperature, vocab_file=vocab_file, vocab_dir=vocab_dir)# use the scoring function to get a dictionary of scores# pass in the relevant parameters as shown in the function definition of # the mean methods you developed earlierscores = score_fn(similarity_fn, samples,log_probs)# find the key with the highest scoremax_index = max(scores,key=lambda x :scores[x])# detokenize the token list associated with the max_indextranslated_sentence = detokenize(samples[max_index],vocab_file,vocab_dir)### END CODE HERE ###return (translated_sentence, max_index, scores)









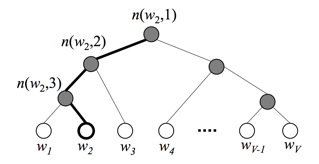
![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)