0、引言
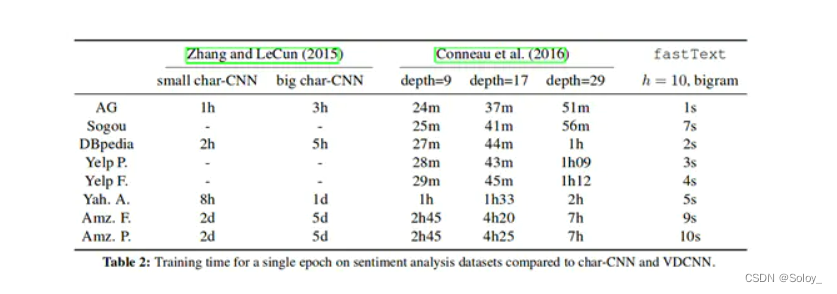
FastText是facebook开源的一款集word2vec、文本分类等一体的机器学习训练工具。在之前的论文中,作者用FastText和char-CNN、deepCNN等主流的深度学习框架,在同样的公开数据集上进行对比测试,在保证准确率稳定的情况下,FastText在训练时间上,有着惊人的表现,近百倍的速度提升
1、fastText文本分类
一般情况下,使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物
(1)字符级别的n-gram
word2vec把语料库中的每个单词当成原子,它会为每个单词生成一个向量,这忽略了单词内部的形态特征,如“apple”与“apples”,两个单词都有较多的公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词,对于“apple”,假设n的取值为3,则它的trigram有:
"<ap","app","ppl","ple","le>"
其中<表示前缀,>表示后缀,我们可以使用这5个trigram的向量叠加来表示“apple”的词向量
优点:
对于低频词生成的词向量效果会更好,因为它们的n-gram可以和其他词共享;对于训练词库之外的单词,仍然可以构建它们的词向量,可以叠加它们的字符级别n-gram向量
(2)模型架构
fastText模型架构和word2vec的CBOW模型架构非常相似,下面就是fastText模型的架构图:

从上图可以看出来,fastText模型包括输入层、隐含层、输出层共三层。其中输入的是词向量,输出的是label,隐含层是对多个词向量的叠加平均。
1)CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些单词用来表示单个文档
2)CBOW的输入单词被one-hot编码过,fastText的输入特征时被embedding过
3)CBOW的输出是目标词汇,fastText的输出是文档对应的类标
(3)核心思想
将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类
小技巧:字符级n-gram特征的引入以及分层softmax分类
2、安装
pip install fasttext
3、实践
具体代码如下所示:
# coidng:utf-8
import fasttext# 模型的训练
def train():model = fasttext.train_supervised("train.txt", lr=0.1, dim=100, epoch=500, word_ngrams=4, loss='softmax')model.save_model("model_file.bin")# 模型的测试
def test_1():classifier = fasttext.load_model("model_file.bin")# 测试模型result = classifier.test("test.txt")print("准确率:", result)f1 = open('prediction.txt', 'w', encoding='utf-8')with open('test.txt', encoding='utf-8') as fp:for line in fp.readlines():line = line.strip()if line == '':continuef1.write(line + '\t#####\t' + classifier.predict([line])[0][0][0] + '\n')f1.close()if __name__ == '__main__':train()test_1()
欢迎同道者交流