FastText:高效的文本分类工具
随着大数据时代的到来,文本分类成为了自然语言处理领域中最重要的任务之一。文本分类可以帮助我们自动将大量文本分为不同的类别,从而加快信息的处理和理解。FastText是Facebook AI Research团队开发的一个高效的文本分类工具,它能够在处理大规模文本数据时快速训练模型。在本篇博客中,我们将介绍FastText模型的原理、优缺点以及如何使用FastText模型来进行文本分类任务。
1. FastText模型原理
FastText模型是基于词向量的文本分类模型。它采用了基于字符级别的n-gram特征表示文本中的词,从而避免了传统的词袋模型需要考虑所有可能的词序列的问题。FastText的训练过程中,每个词会被表示成一个定长的向量,然后将这些向量组合成文本的向量表示,最后使用softmax函数进行分类。
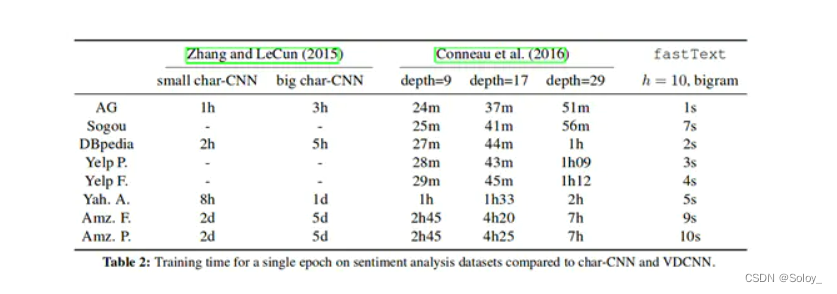
FastText的主要优势是其高效性。它使用了层级softmax(hierarchical softmax)来加速训练过程。层级softmax是一种用于处理大规模分类问题的方法。它将标签树化,使得每个标签只需要与其父节点的分类器进行计算,而不是对所有可能的标签进行计算。这种方法能够大大减少计算量,从而提高了训练速度。
除了层级softmax,FastText还使用了负采样(negative sampling)来训练模型。负采样是一种用于优化词向量训练的技术。它通过从未出现在当前上下文中的单词中随机采样一定数量的单词,将它们作为负样本与当前上下文中的单词进行比较。负采样可以使得模型更加鲁棒,同时也可以提高训练速度。
FastText模型的缺点是其对于长文本的处理能力相对较弱。由于FastText采用的是基于词向量的方法,它很难对于超出单词级别的信息进行建模。此外,由于FastText使用的是n-gram方法,对于较长的文本,它需要建模的特征数量较多,这也会导致训练过程的复杂度增加。
2. FastText模型的优缺点
FastText模型具有以下优点:
- 高效性:FastText采用了层级softmax和负采样技术来加速训练过程,从而能够处理大规模文本数据。
- 鲁棒性:FastText使用n-gram特征表示文本,能够捕捉到单词之间的关系,使得模型更加鲁棒。
- 高度可扩展:FastText模型能够轻松地适应新的类别或文本类型。
FastText模型的缺点包括:
- 对于超出单词级别的信息建模能力相对较弱。
- 对于较长的文本,模型需要建模的特征数量较多,训练过程的复杂度增加。
3. FastText模型案例
下面我们将介绍如何使用FastText模型来进行文本分类任务。我们将使用IMDb电影评论数据集进行实验。
(1)数据准备
下载IMDb数据集:https://ai.stanford.edu/~amaas/data/sentiment/
我们首先需要将数据集分为训练集和测试集。我们将70%的数据作为训练集,30%的数据作为测试集。
import pandas as pd
import numpy as np# 加载数据集
def load_data(file_path):data = pd.read_csv(file_path, header=None, delimiter="\t", names=['label', 'text'])data['label'] = np.where(data['label'] > 5, 1, 0) # 将评分大于5的评论视为正向评论return data# 划分训练集和测试集
def split_data(data, split_ratio=0.7):train_size = int(len(data) * split_ratio)train_data = data[:train_size]test_data = data[train_size:]return train_data, test_data# 加载数据集
data = load_data('imdb.tsv')# 划分训练集和测试集
train_data, test_data = split_data(data, 0.7)
接下来,我们需要对文本进行预处理。首先,我们将文本转换成小写,并去除标点符号和数字。然后,我们将文本分词,并去除停用词(如“the”、“a”、“an”等常用词语)。最后,我们将文本转换成n-gram特征表示。
import re
import string
import nltk
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import CountVectorizer# 预处理文本
def preprocess_text(text):# 将文本转换成小写text = text.lower()# 去除标点符号和数字text = re.sub('[%s]' % re.escape(string.punctuation + string.digits), '', text)# 分词tokens = nltk.word_tokenize(text)# 去除停用词stop_words = set(stopwords.words('english'))tokens = [token for token in tokens if token not in stop_words]# 提取n-gram特征表示vectorizer = CountVectorizer(analyzer='char', ngram_range=(1,3))features = vectorizer.fit_transform(tokens)return features# 对训练集和测试集进行预处理
train_features = [preprocess_text(text) for text in train_data['text']]
test_features = [preprocess_text(text) for text in test_data['text']]
(2)训练模型
接下来,我们使用FastText模型来训练文本分类模型。我们使用默认参数进行训练。
import fasttext# 训练模型
model = fasttext.train_supervised(input=train_features, label=train_data['label'])
(3)使用模型进行预测
训练完成后,我们可以使用训练好的模型对测试集进行预测,并计算模型的准确率、精确率、召回率和F1值。
# 对测试集进行预测
predicted_labels = model.predict(test_features)[0]
predicted_labels = [int(label[0]) for label in predicted_labels]# 计算准确率、精确率、召回率和F1值
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_scoreaccuracy = accuracy_score(test_data['label'], predicted_labels)
precision = precision_score(test_data['label'], predicted_labels)
recall = recall_score(test_data['label'], predicted_labels)
f1 = f1_score(test_data['label'], predicted_labels)print('Accuracy: {:.4f}'.format(accuracy))
print('Precision: {:.4f}'.format(precision))
print('Recall: {:.4f}'.format(recall))
print('F1: {:.4f}'.format(f1))
4. 结论
FastText是一种高效的文本分类模型,它使用n-gram特征表示文本,并采用层级softmax和负采样技术来加速训练过程。FastText模型的优点包括高效性、鲁棒性和高度可扩展性,但其缺点包括对于超出单词级别的信息建模能力相对较弱,以及对于较长的文本,训练过程的复杂度增加。在实际应用中,我们可以根据具体任务的需要选择不同的文本分类模型来进行训练。
5. FastText模型的公式推导
为了更好地理解FastText模型的原理,我们在此对其进行一些公式推导。
首先,我们可以将文本表示为一个词袋模型,其中每个词被表示成一个one-hot向量。假设文本中共有N个不同的单词,文本的词袋模型可以表示为一个N维向量,其中第i维表示第i个单词是否出现在文本中。
假设我们希望将文本分为K个类别,我们需要训练K个分类器。对于每个分类器i,我们将文本的词袋模型表示为一个定长的向量vi,其中每个元素表示与第i个类别相关的单词出现的频率。我们可以使用softmax函数将这个向量转换成概率分布,从而进行分类。
具体地,假设第i个分类器的权重矩阵为Wi,偏置为bi,则第i个分类器的输出可以表示为:
y i = 1 1 + exp ( − W i ⋅ v + b i ) y_i = \frac{1}{1+\exp(-W_i \cdot v + b_i)} yi=1+exp(−Wi⋅v+bi)1
其中,v表示文本的词袋模型向量, ⋅ \cdot ⋅表示向量内积, W i W_i Wi是一个维度为N×d的权重矩阵, b i b_i bi是一个长度为d的偏置向量, d d d是一个预定义的超参数,通常设置为较小的值(如20-200)。该模型可以使用随机梯度下降算法进行训练。
FastText模型的主要创新点在于其对于词向量的表示。FastText使用了基于字符级别的n-gram表示单词,从而避免了传统词袋模型需要考虑所有可能的词序列的问题。具体地,假设单词 w w w可以表示为字符序列 c 1 , c 2 , . . . , c m c_1, c_2, ..., c_m c1,c2,...,cm,则单词 w w w的n-gram表示可以定义为所有长度为 n n n的字符序列的和:
ϕ n ( w ) = c 1 c 2 . . . c n , c 2 c 3 . . . c n + 1 , . . . , c m − n + 1 c m − n + 2 . . . c m \phi_n(w) = {c_1c_2...c_n, c_2c_3...c_{n+1}, ..., c_{m-n+1}c_{m-n+2}...c_m} ϕn(w)=c1c2...cn,c2c3...cn+1,...,cm−n+1cm−n+2...cm
其中, n n n是一个预定义的超参数,通常设置为2-5。这样,每个单词 w w w都可以表示为一个定长的向量,即所有n-gram特征的平均值。
具体地,假设单词 w w w的词向量为 z w z_w zw,则:
z w = 1 ∣ ϕ n ( w ) ∣ ∑ g ∈ ϕ n ( w ) z g z_w = \frac{1}{|\phi_n(w)|} \sum_{g\in\phi_n(w)} z_g zw=∣ϕn(w)∣1g∈ϕn(w)∑zg
其中, z g z_g zg表示n-gram特征 g g g的向量表示。
最后,文本的向量表示可以定义为其中每个单词的词向量的平均值:
w 1 , w 2 , . . . , w M ∑ i = 1 M z w i {{w_1, w_2, ..., w_M}} \sum_{i=1}^{M} z_{w_i} w1,w2,...,wMi=1∑Mzwi
其中, M M M是文本中的单词数量。
总之,FastText模型是一种基于字符级别的n-gram特征的文本分类模型,它能够快速训练模型,并在处理大规模文本数据时表现出色。