提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 目标
- 一、fastText的模型架构
- 1. N-gram的理解
- 1.1 bag of word
- 2. fastTex模型中层次化的softmax
- 2.1 哈夫曼树和哈夫曼编码
- 2.1.1 哈夫曼树的定义
- 2.1.2 哈夫曼树的相关概念
- 2.1.3 哈夫曼树的构造算法
- 2.1.3 哈夫曼树编码
- 2.1.4 梯度计算
- 3. 负采样
目标
1. 能够说出fastText的架构
2. 能够说出fastText速度快的原因
3. 能够说出fastText中层次化的softmax是如何实现的
提示:以下是本篇文章正文内容,下面案例可供参考
一、fastText的模型架构
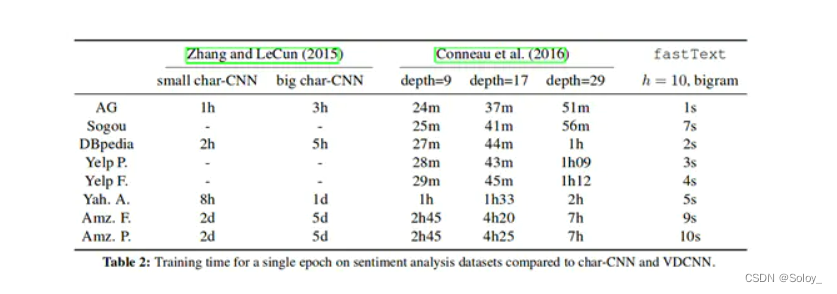
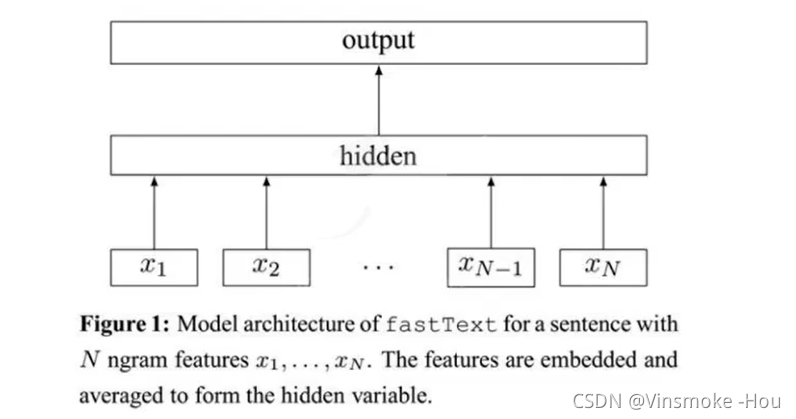
fastText的结构非常简单,有三层:输入层、隐藏层、输出层(softmax)
**输入层:**是对文档embedding之后的向量,包含N-gram特征
**隐藏层:**是对输入数据的求和平均
**输出层:**是文档对应标签
如图所示:
1. N-gram的理解
1.1 bag of word

bag of word 又称为词袋,是一种只统计词频的手段,在fastText的输入层,不仅有分词之后的词语,还有包含有N-gram的组合词语一起作为输入。在机器学习中countVectorizer和TfidfVectorizer都可以理解为一种bow模型。
2. fastTex模型中层次化的softmax
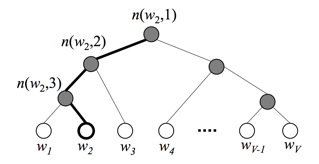
为了提高效率,在fastText中计算分类标签概率的时候,不再使用传统的softmax来进行多分类的计算,而是使用哈夫曼树,使用层次化的softmax来进行概率的计算。
2.1 哈夫曼树和哈夫曼编码

2.1.1 哈夫曼树的定义
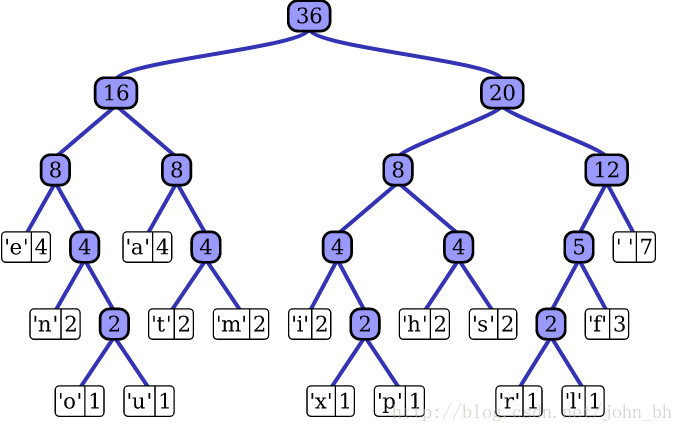
哈夫曼树概念:给定n个权值作为n个叶子节点,构造一个二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树。哈夫曼树是带权路径长度最短的树,权值较大的节点离根较近。
2.1.2 哈夫曼树的相关概念
**二叉树:**每个节点最多有2个子树的有序树,两个子树分别称为左子树、右子树。有序的意思是:树有左右之分,不能颠倒。
**叶子节点:**一棵树当中没有子节点的节点称为叶子节点。
**路径和路径长度:**在一棵树中,从一个节点往下可以到达孩子或孙子节点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定跟接地那的层数为1,则从跟接地那到第L层节点的路径长度为L-1。
**节点的权及带权路径长度:**若将树中节点赋予一个有某种含义的数值,则这个数值称为该节点的权,节点的带权路径长度为:从根节点到该节点之间的路径长度与该节点的权的乘积。
**树的带权路径长度:**树的带权路径长度规定为所有叶子节点的带权路径长度之和。
**树的高度:**树中节点的最大层次。包含n个节点的二叉树的高度至少为 l o g 2 ( n + 1 ) log_2(n+1) log2(n+1)。
2.1.3 哈夫曼树的构造算法
- 把 W 1 , W 2 , W 3.... W n {W1,W2,W3....Wn} W1,W2,W3....Wn看成n棵树的森林
- 在森林中选择两个根节点权值最小的树进行合并,作为一颗新树的左右子树,新树的根节点权值为左右子树的和
- 删除之前选择出的子树,把新树加入森林
- 重复2-3步骤,直到森林只有一颗树为止,该树就是所求的哈夫曼树。

可见:
- 权重越大,距离根节点越近
- 叶子的个数为n,构造哈夫曼树中新增的节点的个数为n-1
2.1.3 哈夫曼树编码
为了提高数据传送的效率,同时为了保证在任一字符的编码都不是另一个字符编码的前缀,这种编码称为前缀编码,可以使用哈夫曼树生成哈夫曼编码解决问题。
可用字符集中的每个字符作为叶子节点生成一颗编码二叉树,为了获得传送保温的最短长度,可将每个字符的出现频率作为字符节点的权值赋予该节点上,显然字使用频率越小权值越小,权值越小叶子就越靠下,于是频率小编码常,频率高编码短,这样就保证了此树的最小带权路径长度效果上就是传送保温的最短长度。

2.1.4 梯度计算



层次化的softmax的好处:传统的softmax的时间复杂度为L(labels的数量),但是使用层次化softmax之后时间复杂度的log(L)(二叉树的高度和宽度的近似),从而在多分类的场景提高了效率。
3. 负采样
negative sampling,即每次从除当前label外的其他label中选择几个作为负样本,作为出现负样本的概率加到损失函数中。



好处:
- 提高训练速度,选择了部分数据进行计算损失,同时整个对没一个label而言都是一个二分类,损失时计算更加简单,只需要让当前label的值的概率尽可能大,其他label的都为反例,概率尽可能小。
- 改进效果,增加部分负样本,能够模拟真实场景下的噪声情况,能够让模型的稳健性更强
例如:
假设句子1对应的类别有Label1,Label2,Label3,Label4,Label5总共5个类别,假设句子1属于label2,那么我们的目标就是让P(Label2|句子1)这个概率最大,但是我们需要同时计算其他四类的概率,并再利用反向传播进行优化的时候需要对词向量都进行更新。这样计算量很大。
但是我们换个方式考虑:使用负采样的时候,把Label2认为是正样本,其他认为是负样本,那么只需要计算P(D=1|句子1,Label2)和P(D=0|句子1,Label2)们只需要计算之前的2/5倍的参数,那么负采样每次让一个训练样本仅仅更新一部分的权重,这样就会降低梯度下降过程中的计算量。
对softmax优化的方法有:
- 层次化的softmax
- 负采样




![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)