神经机器翻译(Neural machine translation, NMT)是最近提出的机器翻译方法。与传统的统计机器翻译不同,NMT的目标是建立一个单一的神经网络,可以共同调整以最大化翻译性能。最近提出的用于神经机器翻译的模型经常属于编码器-解码器这种结构,他们将源句子编码成固定长度的矢量,解码器从该矢量生成翻译。在本文中,我们推测使用固定长度向量是提高这种基本编码器-解码器架构性能的瓶颈,提出让模型从源语句中自动寻找和目标单词相关的部分,而不是人为的将源语句显示分割进行关系对应。采用这种新方法,我们实现了与现有最先进的基于短语的系统相媲美的英文到法文翻译的翻译性能。
之前的NMT在处理长句子的时候会有些困难,尤其是比训练数据集更长的文本。随着数据句子长度增加,基本的编码解码器表现会急剧下降。
谷歌开放GNMT教程:如何使用TensorFlow构建自己的神经机器翻译系统
GitHub 链接:https://github.com/tensorflow/nmt
1. 关于神经机器翻译
以词组为基础的传统翻译系统将源语言句子拆分成多个词块,然后进行词对词的翻译。这使得翻译输出结果流畅性大打折扣,远远不如人类译文。而我们会通读整个源语言句子,了解句子含义,然后输出翻译结果。神经机器翻译(NMT)竟然可以模仿人类的翻译过程。

编码器-解码器结构----神经机器翻译的通用方法实例。编码器将源语言句子转换成[意义]向量,然后通过解码器输出翻译结果。
具体来说,神经机器翻译系统首先使用编码器读取源语言句子,构建一个[思想]向量,即代表句义的一串数字;然后使用解码器处理该容器,并输出翻译结果,如上图所示。这就是我们通常所说的编码器-解码器结构。神经机器翻译用这种方法解决以词组为基础的传统翻译系统遇到的翻译问题;神经机器翻译能够捕捉语言中的长距离依赖结构,如词性一致,句法结构等,然后输出流利度更高的翻译结果,正如谷歌神经机器翻译系统已经做到的那样。
NMT模型在具体的结构中会发生变化。对于序列数据而言,最好的选择是循环神经网络(RNN),这也被大多数NMT模型采用。通常情况下,编码器和解码器都可使用循环神经网络。但是循环神经网络模型在下列情况中发生变化:
(1)方向性(directionality),单向或双向;
(2)深度,单层或多层;
(3)类型,通常是vanilla(普通) RNN、长短期记忆(Long Short-term Memory, LSTM),或门控循环单元(gated recurrent unit, GRU).
本教程中,我们将以单向的深度多层RNN(deep multi-layer RNN)为例,它使用LSTM作为循环单元。模型实例如下图所示。

上图中,「<s>」代表解码过程开始,「</s>」代表解码过程结束。
我们在该实例中构建了一个模型,将源语言句子[I am a student]翻译成目标语言「Je suis étudiant」。该NMT模型包括两个循环神经网络:编码器RNN,在不预测的情况下将输入的源语言单词进行编码;解码器,在预测下一个单词的条件下处理目标句子。
2. 安装该教程
首先确保已经安装TensorFlow。然后再将本教程的代码clone☞本地。
3. 训练-如何构建我们第一个NMT系统
一个NMT模型具体代码的核心----model.py
在网络的底层,编码器和解码器RNN接收到以下收入:首先是原句子,然后是从编码到解码模式的过渡边界符号「<s>」,最后是目标语句。
对于训练来说,我们将为系统提供以下张量,它们是以时间为主(time-major)的格式,并包括了单词索引:
- encoder_inputs [max_encoder_time, batch_size]:源输入词。
- decoder_inputs [max_decoder_time, batch_size]:目标输入词。
- decoder_outputs [max_decoder_time, batch_size]:目标输出词,这些是 decoder_inputs 按一个时间步向左移动,并且在右边有句子结束符。
为了更高的效率,我们一次用多个句子(batch_size)进行训练。






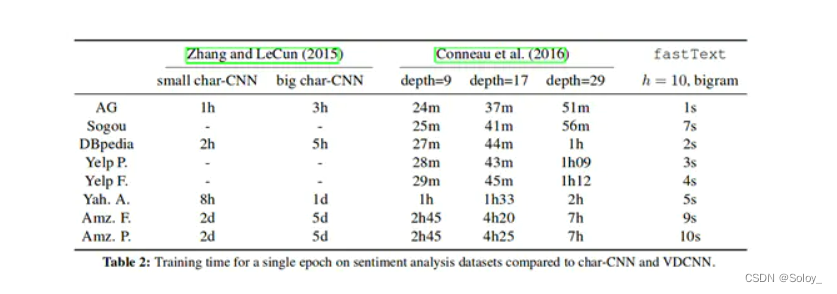
![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)