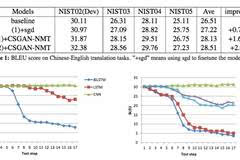
在机器翻译中,目前都采用的方法是bpe切分子词的方法来处理翻译中的未登录词。
如何使用?
https://github.com/rsennrich/subword-nmt这里面已经写了详细的方法,本文主要记录我处理中英语料时的步骤。
1.共享词典
直接clone了这个项目,但是没有安装的情况下,我们使用python命令来处理。否则参考原文给出的命令处理语料。
如果我们进行翻译的双语是共享字母表的,那么我们可以为这两种语言建立一个共享词典,比如:
python subword-nmt/learn_joint_bpe_and_vocab.py --input corpus.tc.en corpus.tc.de -s 32000 -o bpe32k --write-vocabulary vocab.en vocab.de通过上述方法我们可以得到bpe32k这个子词词表和 vocab.en,vocab.de的双语词典(里面是这两种语言的子词及其出现的频率)
接下来我们使用以下命令来对双语的语料进行subword切分处理,以下是对训练集进行处理,我们使用相同的命令来对验证集和测试集进行处理。
python subword-nmt/apply_bpe.py -c bpe32k --vocabulary vocab.en --vocabulary-threshold 50 < corpus.tc.en > corpus.bpe32k.en
python subword-nmt/apply_bpe.py -c bpe32k --vocabulary vocab.de --vocabulary-threshold 50 < corpus.tc.de > corpus.bpe32k.de2.不共享词典
对于中英翻译,中文和英文的字母表是不共享的,所以我们需要单独处理这两类语料。
step1:生成子词词典
subword-nmt learn-joint-bpe-and-vocab -i ./train.en -s 32000 -o ./use_bpe/bpe32k.en --write-vocabulary ./use_bpe/vocab.en
subword-nmt learn-joint-bpe-and-vocab -i ./train.zh -s 32000 -o ./use_bpe/bpe32k.zh --write-vocabulary ./use_bpe/vocab.zhstep2:根据第一步生成的词典过滤双语语料
subword-nmt apply-bpe -c bpe32k.en --vocabulary vocab.en --vocabulary-threshold 50 < ../train.en > train.BPE.en
subword-nmt apply-bpe -c bpe32k.zh --vocabulary vocab.zh --vocabulary-threshold 50 < ../train.zh > train.BPE.zh
subword-nmt apply-bpe -c bpe32k.en --vocabulary vocab.en --vocabulary-threshold 50 < ../valid.en > valid.BPE.en
subword-nmt apply-bpe -c bpe32k.zh --vocabulary vocab.zh --vocabulary-threshold 50 < ../valid.zh > valid.BPE.zh
subword-nmt apply-bpe -c bpe32k.en --vocabulary vocab.en --vocabulary-threshold 50 < ../test.en > test.BPE.en
subword-nmt apply-bpe -c bpe32k.zh --vocabulary vocab.zh --vocabulary-threshold 50 < ../test.zh > test.BPE.zh然后我们就可以使用bpe切分后的双语语料进行nmt训练了。
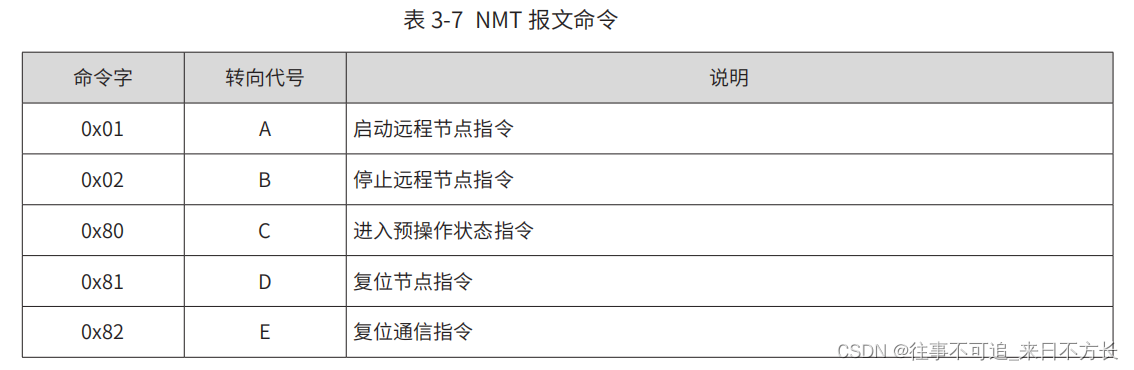
![学习CANopen --- [3] NMT报文](https://img-blog.csdnimg.cn/20200606102208730.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3doYWh1MTk4OQ==,size_16,color_FFFFFF,t_70)