
来自:天宏NLP
进NLP群—>加入NLP交流群
本文主要介绍NMT模型鲁棒性的相关改进工作,介绍一下对抗训练的三部曲,一作皆是ChengYong,分别中了2018,2019和2020的ACL。
第一项工作为 Towards Robust Neural Machine Translation (ACL 2018)
本文的问题引入为一个小实验,即将机器翻译的源句进行微小扰动(同义词替换),69.74%的翻译句子也随之改变,并且原始输入和扰动输入对应的翻译句间BLEU仅为79.01,因此,作者希望通过对抗训练来加强Encoder和Decoder的抗干扰能力。
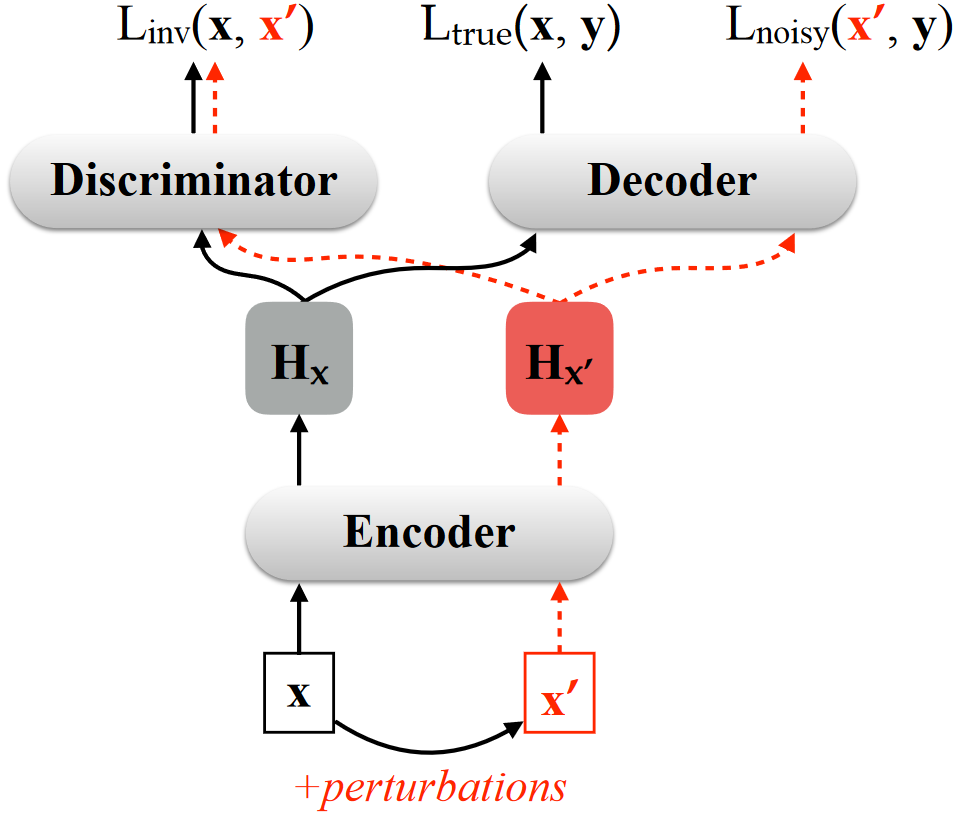
具体做法如上图,首先是噪声的引入,作者提出两种方式:1)词汇级别,计算余弦相似度进行同义词替换;2)特征级别,在词向量上加入高斯噪声。然后是噪声数据的使用,对应上图中三个损失函数:1)Ltrue(x, y)是正常训练NMT的损失函数;2)Lnoisy(x', y)是加强Decoder的去噪能力,即对应有噪声的Hx',Decoder也能得到正确的输出;3)Linv(x, x'),旨在加强Encoder的去噪能力,即针对噪声数据x',Encoder得到的Hx'也应与原表征Hx相近,训练过程采用了min-max two-player策略,引入Discriminator进行交互对抗训练,Encoder得到Hx和Hx'应该尽可能相似骗过Discriminator,而Discriminator则要分开有、无噪声的数据,两者迭代训练以加强Encoder对噪声数据x'的建模能力。
文章优势在于不改变模型结构,可拓展到任意噪声干扰或是针对特定任务进行设计,如作者对输入数据进行删除、替换等token级噪声时,发现使用词汇级别噪声的引入训练的模型更鲁棒。
第二项工作为 Robust Neural Machine Translation with Doubly Adversarial Inputs (ACL 2019)
这项工作不同于上文的模型无关,而是将NMT看成“白盒”,从而基于梯度生成对抗输入,文章的核心思想就是下面这条式子,其中x',x分别代表有无噪声的数据,R(·)为相似性度量,后面的是负对数Loss,通俗来讲就是找到噪声不是太大的x'(保证x'与x语义相近),使得模型的Loss最大,这样才能最有效地加强模型鲁棒性。
![]()
具体做法分为两部分,分别是Encoder攻击和Decoder防御。在Encoder端,x为Encoder的输入,模型会算出某个词表征xi的梯度gxi,然后在词表中找出使Loss最大的x替换原有的词xi,做法是在词典中计算表征“e(x)-e(xi)”与gxi的相似度,使相似度最大的xi'为所得。同时,噪声xi'不应与原始xi差太远,作者使用了Masked LM提取候选词,在原句中,会将需要替换的词先mask,然后选择预测的topk作为候选项,至于哪些词会被mask或替换则为随机均匀采样。
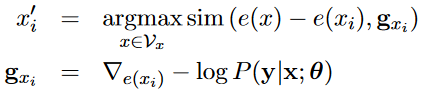
在Decoder端,z为Decoder的输入,与Encoder中的噪声xi'类似,以同样的方法得到zi',但针对zi的采样与xi有关,即xi随机采样,zi需要大概率在xi替换的同样位置进行替换。因此,回望整个训练方式,Encoder的作用是找到使梯度最大的xi'扰乱模型,Decoder的作用是即使输入为zi',仍能输入正确的结果,具有一定鲁棒性。
我觉得本文有两点值得思考,首先是基于梯度最大来找噪声词,能够更有力的对模型鲁棒能力发起攻击,其实这个可以更进一步,Encoder输入中需要被替换的词并非随机采样,而是找使Loss最大的词,相关文章改进CE Loss为Focal Loss也就是这个思想,我们可以直觉判断,模型建模较好的是高频词,建模不好的是低频词,低频词的Loss比较大,我们在大Loss的基础上再找大梯度,这样攻击效果更强力,同时可以提高模型对低频词的鲁棒性。第二点是作者对xi的替换处理,还要回词典中寻找进行词替换,这样未免更加麻烦了,为什么不在一定范围内,直接找梯度最大的向量进行替换了呢?如果 怕语义信息不相似,缩小相似度量范围就好了,这样更方便。
第三项工作为 AdvAug: Robust Adversarial Augmentation for Neural Machine Translation (ACL 2020)
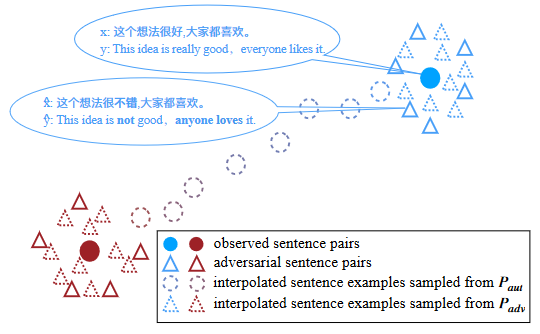
这项工作是在第二项的基础上进行了数据增强的改进,采用的方法为线性插值,首先针对原始数据(x, y),作者用第二项工作的方法造出一堆噪声数据,然后对噪声数据进行线性插值生成更多的伪数据,令人比较奇怪的是,作者对不同的parallel data pair同样进行了线性插值,可能两句话虽不同含义,但是插值后在向量空间,源句和目标句也能表达类似语义?
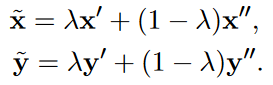
进NLP群—>加入NLP交流群















![[NLP]文本分类之fastText详解](https://img-blog.csdnimg.cn/20200406144622118.png#pic_center#pic_center#pic_center#pic_center#pic_center)

