ECCV-2020
作者分享:https://www.techbeat.net/talk-info?id=462
Code:https://github.com/lxtGH/DecoupleSegNets
文章目录
- 1 Background and Motivation
- 2 Related Work
- 3 Advantages / Contributions
- 4 Method
- 4.1 Decoupled segmentation framework
- 4.2 Body generation module
- 4.3 Edge preservation module
- 4.4 Decoupled body and edge supervision
- 4.5 Network architecture
- 5 Experiments
- 5.1 Datasets
- 5.2 Ablation studies
- 5.3 Visual analysis
- 5.4 Results on other datasets
- 6 Conclusion(own)
1 Background and Motivation
现有语义分割方法的缺点:
- RF grows slowly,不能 model longer-range relationships between pixels,分割时,物体内部会产生歧义和噪声
- 下采样操作,会带来 blurred predictions
针对缺点 1 的提升方法有(提升 object inner consistency)
- dilated convolution
- pyramid pooling module
- non-local operators
- graph convolution network
- dynamic graph
针对缺点 2 的提升方法有(提升 object boundaries)
- embed low-level features into high-level features
- refine the outputs
上述的方法要么增加了 object inner consistency(属于同一物体的特征靠近一些,分割在一起),要么增加了 object boundaries,没有考虑 body 和 boundary 之间的交互,作者从图片低频高频分别代表 body 和 boundary 角度出发,把特征解耦成 body feature 和 boundary(edge) feature 部分, and then jointly optimizing them in a unified framework

2 Related Work
- Semantic segmentation
- structured prediction operators:eg CRF
- Deep Learning:eg PSPNet,DeepLab series
- Boundary processing
- Multi task learning
3 Advantages / Contributions
- Improving Semantic Segmentation via 解耦 body 和 edge 特征(然后用 loss 进行监督)
- 设计了 Body Generation Module 用来专门提取 body feature 的模块
- 提出的方法较为轻便,很容易加入到现有的 semantic segmentation 方法中
- 在 4 个 driving scene semantic segmentation 数据集上取得了 SOTA
4 Method
1)object inner consistency
improve the object’s inner consistency by modeling the global context
2)object boundaries
refine objects detail along their boundaries by multi-scale feature fusion
4.1 Decoupled segmentation framework
F ^ = F b o d y + φ ( F e d g e ) = F b o d y + φ ( F − F b o d y ) = ϕ ( F ) + φ ( F − ϕ ( F ) ) \begin{aligned} \hat{F} &= F_{body} + \varphi(F_{edge}) \\ &= F_{body} + \varphi(F - F_{body}) \\ &= \phi(F) + \varphi(F- \phi(F)) \end{aligned} F^=Fbody+φ(Fedge)=Fbody+φ(F−Fbody)=ϕ(F)+φ(F−ϕ(F))
- ϕ \phi ϕ 是 body generation module
- φ \varphi φ 是 edge perservation module
- F F F 是原始特征图, F = F b o d y + F e d g e F = F_{body} + F_{edge} F=Fbody+Fedge
- F ^ \hat{F} F^ 是加强后的特征图
4.2 Body generation module
目的是 generating more consistent feature representations for pixels inside the same object
learn a flow field δ ∈ R H × W × 2 \delta \in \mathbb{R}^{H \times W \times 2} δ∈RH×W×2 generated by the network itself to warp features towards object inner parts
1)Flow field generation
核心的思想如下
Low spatial frequency parts capture the summation of images, and a lower resolution feature map represents the most salient part where we view it as pseudo-center location or the set of seed points.
特征图分辨率很小的时候,其代表的都是每个区域最 salient 的部分
整体结构如下,借鉴的是《Flownet: Learning optical flow with convolutional networks》

采用的是 encoder-decoder 的结构
Down-sampling 的作用是产生伪中心点,或者说 coarse 的中心点,之后上采样成原始特征图分辨率,然后与原始特征图 concatenation 在一起来 learn flow filed

2)Feature warping
让同一目标的特征尽量往其中心靠近

w w w 是 flow map 对应的值
F F F 是原始特征
Flow field 的作用方式是对四领域内的点进行加权求和
4.3 Edge preservation module

思路:原始特征减去 body 特征,之后再和 low-level 特征进行融合来 supply the missing fine details information

上图紫色的部分为 F − F b o d y F-F_{body} F−Fbody
∣ ∣ || ∣∣ 表示 concatenation, γ \gamma γ 是 1×1 conv
F f i n e F_{fine} Ffine 表示的是 low-level feature,来自 backbone 的浅层
4.4 Decoupled body and edge supervision


监督了 F b o d y F_{body} Fbody, F e d g e F_{edge} Fedge 和 F ^ \hat{F} F^(也即 F f i n a l F_{final} Ffinal)

- b b b 表示 F e d g e F_{edge} Fedge,a boundary map
- s b o d y s_{body} sbody 表示 F b o d y F_{body} Fbody 预测的结果
- s f i n a l y s_{finaly} sfinaly 表示 F f i n a l F_{final} Ffinal 预测的结果
- s ^ \hat{s} s^ 表示 GT semantic label
- b ^ \hat{b} b^ 表示 GT binary masks which is generated by s ^ \hat{s} s^
- L f i n a l L_{final} Lfinal 是 cross entropy loss for segmentation task
- L b o d y L_{body} Lbody 采用的是 boundaries relaxation loss(借鉴的是 《Improving semantic segmentation via propagation and label relaxation》——CVPR 2019),在训练时,仅 sample part of pixels within the objects for training
- L e d g e L_{edge} Ledge 如公式 4 所示

Most of the hardest pixels to classify lie on the boundary between object classes.(边界点是难样本)
It is not easy to classify the center pixel of a receptive field when poentially half or more of the input context could be a new class!
作者解决的方法是,引入 edge prior,配合 OHEM
公式 4 分为 L b c e L_{bce} Lbce 和 L c e L_{ce} Lce 两部分
-
L b c e L_{bce} Lbce 是边界 label 和预测边界之间的 binary cross entropy loss
-
L c e L_{ce} Lce 是 cross entropy loss,如公式 5 所示

- N N N 是 total pixels in the image
- K = 0.10 ⋅ N K = 0.10 \cdot N K=0.10⋅N
- s ^ i \hat{s}_i s^i 是 pixel i i i 的 GT 类别
- s i , j s_{i,j} si,j 是 predicted posterior probability for pixel i i i and class j j j,可以简单理解为 i i i 预测为 s ^ i \hat{s}_i s^i 的概率
- I [ x ] = 1 \mathbb{I[x] = 1} I[x]=1 如果 x x x 是 True,否则为 0
- σ \sigma σ 是 sigmoid 函数,来来判断是否为边界
- t K t_K tK 是 OHEM 中的阈值, 选取 K highest losses
- t b t_b tb 是判断是否为边界的阈值
仔细分析下公式 5,交叉熵 loss,-plogq 的形式,目的让 q 接近 p,也即预测出为边界的点 (q) 尽可能的是边界(p)
在实际发挥功效过程中, L b o d y L_{body} Lbody 和 L e d g e L_{edge} Ledge 相互补偿,他们 sample 的 pixels separately from different regions
4.5 Network architecture
用的是 DeepLab V3+ 框架,dilated ResNet 作为 backbone
作者提出的模块插入在
DeepLab V3+ 框架中 ASPP module 之后
FCN 框架中 final output layer of the backbone
PSPNet 框架中的 PPM module
5 Experiments
5.1 Datasets
-
Cityscapes

-
CamVid

-
KIITI
-
BDD

5.2 Ablation studies

1)Improvements over baseline model
+US 是加入了 uniform sampling trick(《Improving semantic segmentation via propagation and label relaxation》——CVPR 2019))

作者的方法真的好猛,3 个多点的提升
2)Ablation studies on decoupled supervisions

BG 和 EP 是 body generation module 和 edge preservation module
L b c e L_{bce} Lbce 和 L e d g e − o h e m L_{edge-ohem} Ledge−ohem 就是 L e d g e L_{edge} Ledge 的两个损失
默认都有正常分割的 loss,也即 L f i n a l L_{final} Lfinal 的 loss
注意到仅引入 L b c e L_{bce} Lbce,模型精度没有提升,作者的解释为
since there is no direct supervision to segmentation prediction(仅看论文,表示解释的不太清晰)
3)Ablation study on the effect of each component

没有 BG warp 不晓得可不可以理解为, flow filed 作用的时候仅针对一个点,而不是邻域加权
4)Comparison with related methods

用 SPN 和 DCN 替换 BG
5)Improvements upon different base models
 Table2 (a)
Table2 (a)
都有不小的提升,强强强
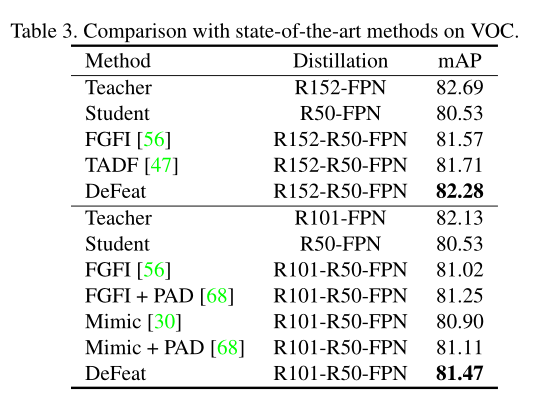
6)Comparison to state-of-the-arts
Table2 (b)
MS 是 multi-scale inference

5.3 Visual analysis
1)Improvement analysis

FCN 中引入作者的模块,大目标提升比较明显(内部一致性)
DeepLab v3+ 和 PSPNet 中引入作者的模块,小目标(边界信息)提升比较明显(since most large patterns are handled by context aggregation modules like PPM and ASPP)


一三行是 prediction,二四行是 error
2)Visualization on decoupled feature representation and prediction


3)Visualization on flow field in BG



FCN 中 flow field 指向 inner part
DeepLab V3+ 中 flow field 指向 boundary(inner part 被 ASPP 模块基本搞定),
和 Table 4 中的现象一致
5.4 Results on other datasets

6 Conclusion(own)
- 上下文信息

语义分割上下文信息的定义是什么? - 托比昂的回答 - 知乎
-
采用了 poly learning rate policy
( 1 − i t e r t o t a l _ i t e r ) 0.9 (1- \frac{iter}{total\_iter})^{0.9} (1−total_iteriter)0.9 -
uniform sampling trick

![[论文评析]Decoupled Knowledge Distillation, CVPR2022](https://img-blog.csdnimg.cn/2b25cab197874350950dd594ea607da4.png#pic_center)