《DC-GNN: Decoupled Graph Neural Networks for Improving and Accelerating Large-Scale E-commerce Retrieval》(WWW’22)
在工业场景中,数百亿节点和数千亿的边直接端到端的GNN-based CTR模型开销太大,文章把整个GNN框架解耦成三阶段:预训练、聚合、CTR。
但实际上文章是把计算开销前移,将图卷积的计算开销转换成了采样子图的计算开销。
图与数据集
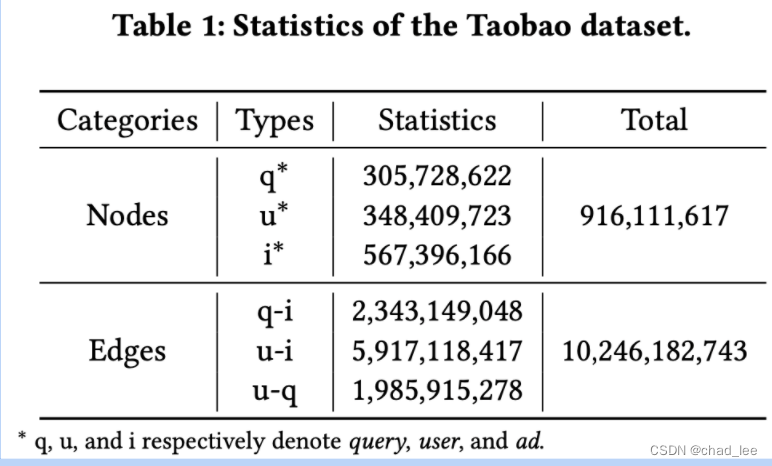
用Taobao近7天的记录作为数据集,有三类节点:user、query和item,每个节点都有丰富的节点属性:设备、年龄等。
有三类边:query搜索item、用户浏览item、用户搜索query。
一共9亿节点、100亿条边。
方法
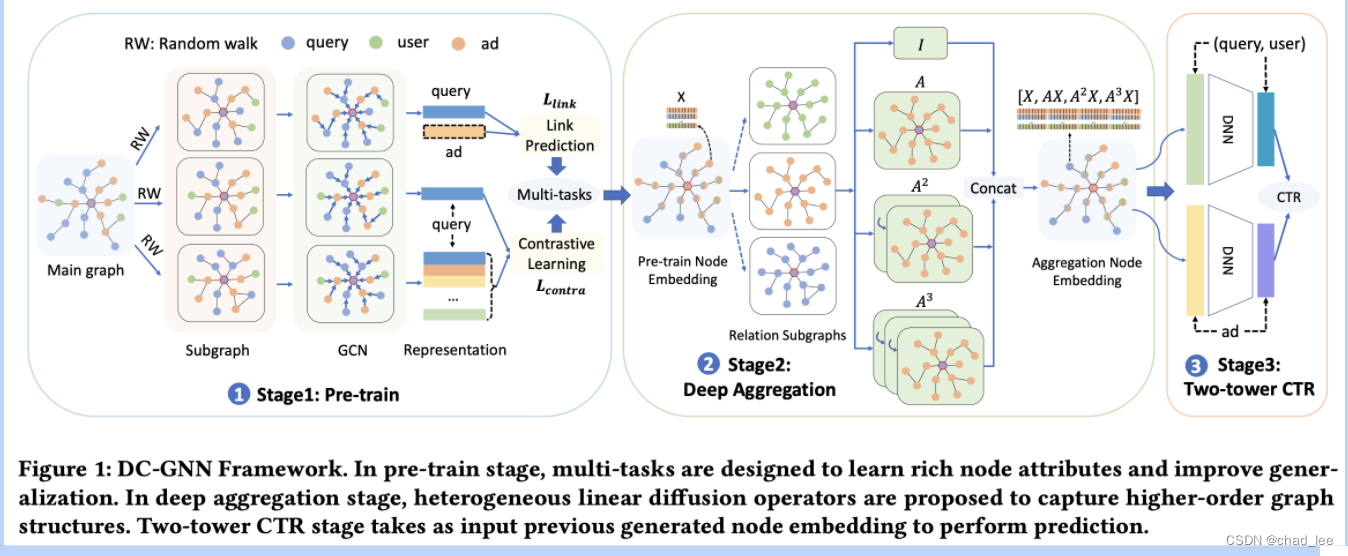
预训练
每个节点先用RW生成 三个 该节点的子图,然后在子图上用GNN encoder对节点进行卷积编码,得到节点的embedding,然后两个预训练任务:
Link Prediction
L l i n k = ∑ ( q , i p ) ∈ E ( − log σ ( f s ( q , i p ) ) − ∑ k log ( 1 − σ ( f s ( q , i n k ) ) ) ) \mathcal{L}_{l i n k}=\sum_{\left(q, i_{p}\right) \in \mathcal{E}}\left(-\log \sigma\left(f_{s}\left(q, i_{p}\right)\right)-\sum_{k} \log \left(1-\sigma\left(f_{s}\left(q, i_{n}^{k}\right)\right)\right)\right) Llink=(q,ip)∈E∑(−logσ(fs(q,ip))−k∑log(1−σ(fs(q,ink))))
有边连接的是正例,然后采集k个负例,负例用到了难负样本挖掘:
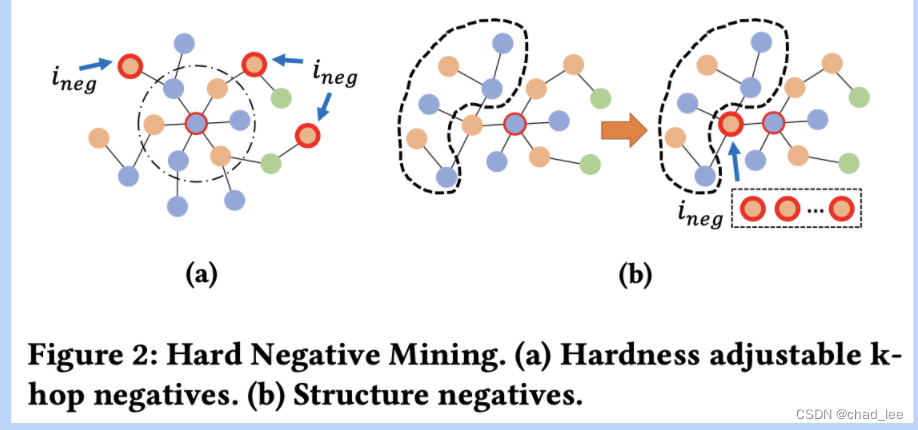
一种是选择K-hop的节点作为负样本,K可以控制难易程度;一种是在维持图结构不变的情况下,将一个正样本替换成全局采得负样本。
文章认为这两种做法都可以强化GNN更加注意节点的属性学习上,避免GNN过分依赖图结构特征,从而缓解over-smoothing。
Multi-view graph contrastive learning
第二个子图和第三个子图得到的embedding,进行对比学习,同一个节点在两个视图的embedding是正例,不同节点是负例。这里只考虑同一类节点之间计算InfoNCE loss,因此会有三个对比学习loss。
所有的loss加起来是total loss:
L q u e r y = ∑ q 1 ∈ v q − log exp ( w f s ( q 1 , q 2 ) ) ∑ v ∈ exp ( w f s ( q 1 , v 2 ) ) L u s e r = ∑ u 1 ∈ v u , v u ∈ V − log exp ( w f s ( u 1 , u 2 ) ) ∑ v exp ( w f s ( u 1 , v 2 ) ) L a d = ∑ i 1 ∈ v i , v i ∈ V − log exp ( w f s ( i 1 , i 2 ) ) ∑ v exp ( w f s ( i 1 , v 2 ) ) L contra = L query + L user + L a d L total = L link + λ 1 L contra + λ 2 ∥ θ ∥ 2 2 \begin{aligned} \mathcal{L}_{q u e r y}&=\sum_{q_{1} \in v_{q}}-\log \frac{\exp \left(w f_{s}\left(q_{1}, q_{2}\right)\right)}{\sum_{v} \in \exp \left(w f_{s}\left(q_{1}, v_{2}\right)\right)}\\ \mathcal{L}_{u s e r} &=\sum_{\substack{u_{1} \in v_{u}, v_{u} \in \mathcal{V}}}-\log \frac{\exp \left(w f_{s}\left(u_{1}, u_{2}\right)\right)}{\sum_{v} \exp \left(w f_{s}\left(u_{1}, v_{2}\right)\right)} \\ \mathcal{L}_{a d} &=\sum_{\substack{i_{1} \in v_{i}, v_{i} \in \mathcal{V}}}-\log \frac{\exp \left(w f_{s}\left(i_{1}, i_{2}\right)\right)}{\sum_{v} \exp \left(w f_{s}\left(i_{1}, v_{2}\right)\right)}\\ \mathcal{L}_{\text {contra }}&=\mathcal{L}_{\text {query }}+\mathcal{L}_{\text {user }}+\mathcal{L}_{a d} \\ \mathcal{L}_{\text {total }}&=\mathcal{L}_{\text {link }}+\lambda_{1} \mathcal{L}_{\text {contra }}+\lambda_{2}\|\theta\|_{2}^{2} \end{aligned} LqueryLuserLadLcontra Ltotal =q1∈vq∑−log∑v∈exp(wfs(q1,v2))exp(wfs(q1,q2))=u1∈vu,vu∈V∑−log∑vexp(wfs(u1,v2))exp(wfs(u1,u2))=i1∈vi,vi∈V∑−log∑vexp(wfs(i1,v2))exp(wfs(i1,i2))=Lquery +Luser +Lad=Llink +λ1Lcontra +λ2∥θ∥22
Deep Aggregation
第一阶段每个节点已经有一个embedding $X了,然后再一次采样图,对于每个节点,采样三个不同种类子图出来,比如target node是user,给这个节点采样三个子图出来,每个子图出了target node之外,分别只包含 user、query、item节点。
然后在已有子图的基础上,和SIGN那篇一样,直接将不同阶卷积的向量拼接起来 [ X , A X , A 2 X , A 3 X ] \left[X, A X, A^{2} X, A^{3} X\right] [X,AX,A2X,A3X] 作为模型的输入。但其实这里有误导的地方,应该是 1+3*3=10 个向量拼接起来,因为有三种子图,每个子图有三阶矩阵,所以实际应该是:
[ X , A 1 X , A 1 2 X , A 1 3 X , A 2 X , A 2 2 X , A 2 3 X , A 3 X , A 3 2 X , A 3 3 X ] \left[X, A_1X, A_1^{2} X, A_1^{3} X,A_2X, A_2^{2} X, A_2^{3} X,A_3X, A_3^{2} X, A_3^{3} X\right] [X,A1X,A12X,A13X,A2X,A22X,A23X,A3X,A32X,A33X]
CTR Prediction
图1.3,拼接好的向量分别送入双塔中,进行CTR预估。负样本是曝光未点击样本:
L C T R = ∑ ( − log σ ( f s ( ( q , u ) , i c l k ) ) − ∑ k log ( 1 − σ ( f s ( ( q , u ) , i p v k ) ) ) ) \mathcal{L}_{C T R}=\sum\left(-\log \sigma\left(f_{s}\left((q, u), i_{c l k}\right)\right)-\sum_{k} \log \left(1-\sigma\left(f_{s}\left((q, u), i_{p v}^{k}\right)\right)\right)\right) LCTR=∑(−logσ(fs((q,u),iclk))−k∑log(1−σ(fs((q,u),ipvk))))
实验
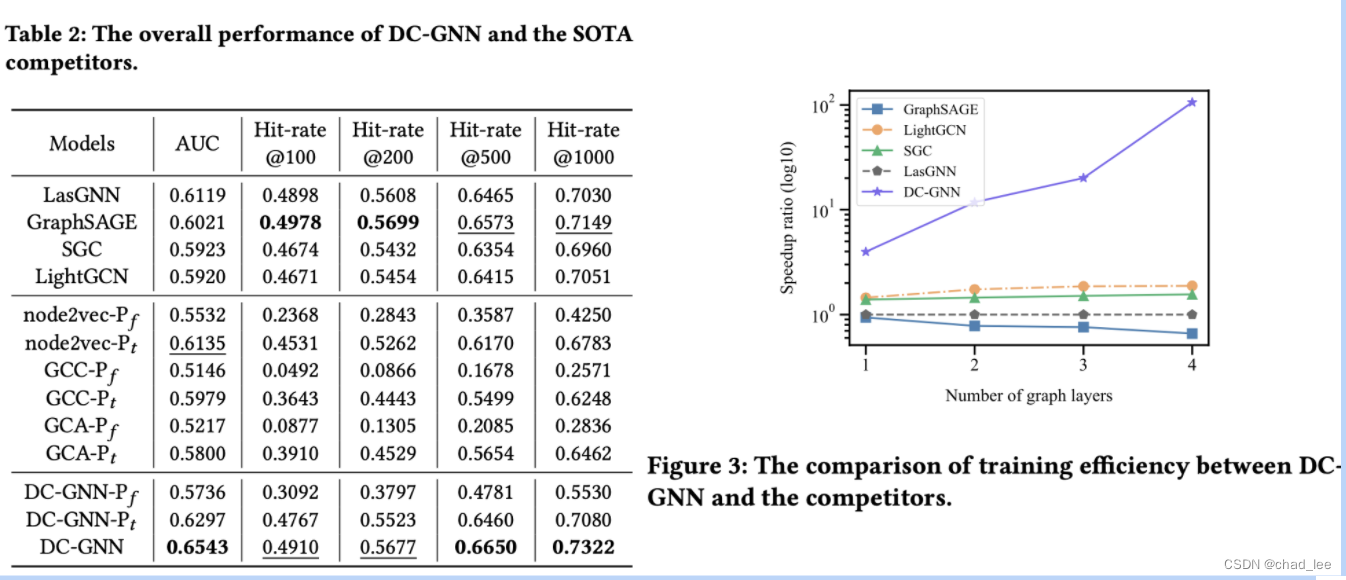
DC-GNN-Pf和DC-GNN-Pt是指跳过Deep Aggregation,直接用pretrain的输出embedding输入CTR,然后fix或者fine-tuning embedding。