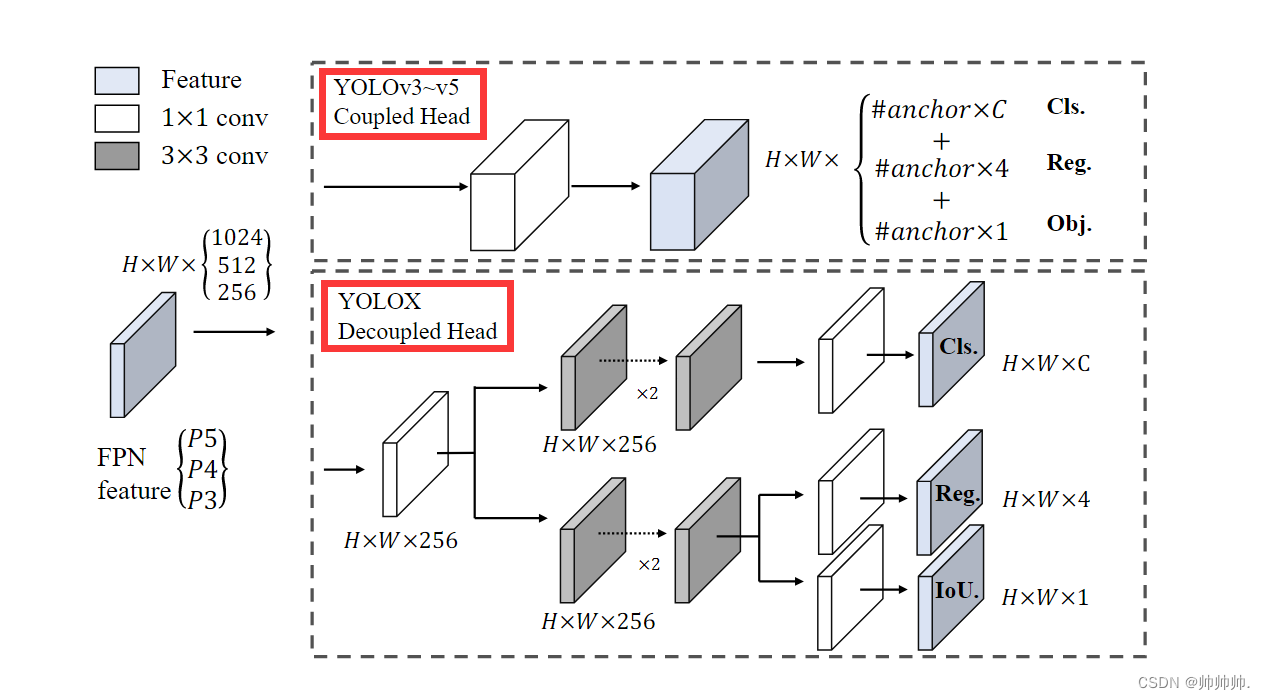
[论文评析]Decoupled Knowledge Distillation, CVPR2022
- 文章信息
- 动机
- 方法
- Basic notions
- KL Loss
- 重要发现
- 伪码
- 思考
- References
文章信息
题目:Decoupled Knowledge Distillation
发表: CVPR ,2022
作者:Borui Zhao 11,Quan Cui 2, Renjie Song 1, Yiyu Qiu 1,3, Jiajun Liang
动机
当前的知识蒸馏研究主要集中在中间特征层的蒸馏,而输出Logit的蒸馏被忽视。基于此,作者从经典的KL loss出发,通过巧妙的变形将KL Loss拆分成了两部分的和,前半部分与目标类别有关,后半部分与非目标类别有关, 从而发现了KL Loss的一些本质性的问题, 进而提出了一种新的Loss能够更好的进行知识蒸馏。
方法
这篇文章最核心的实际上就是对KL loss的Reformulation, 在开始对KL loss进行变形之前先来声明一些定义,后面会用到。
Basic notions
对于C各类别的分类问题,模型的输出记为:
 其中第i个分量表示输入属于第i个类别的概率,计算公式如下:
其中第i个分量表示输入属于第i个类别的概率,计算公式如下:
 其中zi即为激活之前模型的第i个输出值logit。
其中zi即为激活之前模型的第i个输出值logit。
根据是否为目标类,将概率集合分类为两部分 b = [ p t , p / t ] b=[p_{t}, p_{/ t}] b=[pt,p/t], 定义如下:
 进一步,对于非目标类别集合进一步定义归一化的概率集合
进一步,对于非目标类别集合进一步定义归一化的概率集合
,定义如下:
 其中 i ∈ { 1 , . . . , t − 1 , t + 1 , . . . , C } i \in \{1,...,t-1, t+1,...,C\} i∈{1,...,t−1,t+1,...,C}。
其中 i ∈ { 1 , . . . , t − 1 , t + 1 , . . . , C } i \in \{1,...,t-1, t+1,...,C\} i∈{1,...,t−1,t+1,...,C}。
可以看到:

KL Loss
KL散度的定义如下,并根据是否为目标类别作如下拆分:
 其中 P T P^{T} PT, P S P^{S} PS分别为ground_truth和Prediction, 都为概率向量的形式,ground_truth可由teacher model获得。
其中 P T P^{T} PT, P S P^{S} PS分别为ground_truth和Prediction, 都为概率向量的形式,ground_truth可由teacher model获得。
将下式带入
 可进一步得到:
可进一步得到:
 因此KL loss拆分为:
因此KL loss拆分为:
 可以看到公式右边前半部分代表目标类的知识蒸馏
可以看到公式右边前半部分代表目标类的知识蒸馏
Target class knowledge distillation (TCKD), 后半部分代表非目标类的知识蒸馏Non-target class knowledge distillation (NCKD), KD被拆分为这二者的加权和:
二者的作用:
TCKD: 通过binary classification 关注与目标类相关的知识,实际上是在学习/迁移与训练样本难度的知识;
NCKD: 关注非目标类的知识,NCKD是logit distillation起作用的重要原因;
重要发现
基于对KD loss的reformulation,作者揭示了KD loss存在的一些本质性问题:
(1)NCKD很重要,但是在经典的KD loss中,NCKD的权重为 1 − p t T 1-p_{t}^{T} 1−ptT,这意味着对于对于预测较好的样本,该项权重接近于0,从而NCKD的作用被限制了;
(2)在经典的KD loss中,二者的权重纠缠在一起,不能够调整二者的权重以平衡这两项的重要度;
基于上述发现的完呢提,作者提出了所谓的解藕知识蒸馏Decoupled knowledge distillation (DKD),新的损失表达式如下:
 可以看到作者引入了两个超参数来— α , β {\alpha, \beta} α,β允许调整二者的权重,从而拜托了原始KD loss的问题。
可以看到作者引入了两个超参数来— α , β {\alpha, \beta} α,β允许调整二者的权重,从而拜托了原始KD loss的问题。
伪码
DKD loss的伪码如下,代码非常简洁,

思考
1.总体而言,文章还是非常intuitive, 揭示了KD loss存在的一些本质性问题,并且提出了可行的办法来解决这些问题。但是,又引入了连个超参数,这些超参数往往需要根据具体的任务&数据集进行调整。另外,作者也提到 β \beta β与蒸馏性能之间的关系尚需进一步探索;
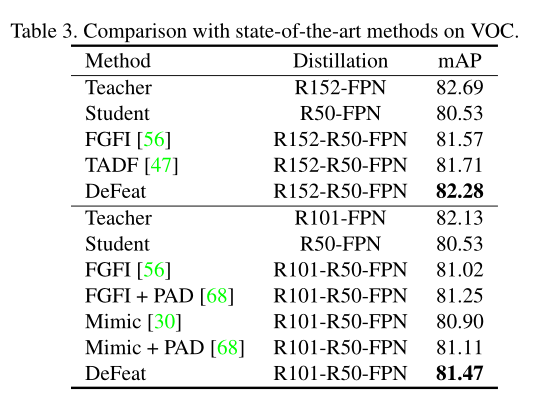
2.作者也提到,在目标检测任务上,logit distillation方法比不上feature distillation的方法,原因在logit distillation不能够迁移有关定位的信息。
References
1.Zhao B, Cui Q, Song R, et al. Decoupled Knowledge Distillation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 11953-11962.
2.https://zhuanlan.zhihu.com/p/523253106;
3.官方代码:https://github.com/megvii-
research/mdistiller