Video Anomaly Detection by Solving Decoupled Spatio-Temp
- 什么是SSL? Self-Supervised Learning,又称为自监督学习
- 什么是多标签分类问题: 一个数据有多个标签
- pretext 任务:
简单的来说,通过另一个任务简介完成主任务
比如,要训练一个网络来对 ImageNet 分类,可以表达为 f θ ( x ) : x → y f_{\theta}(x): x \rightarrow y fθ(x):x→y ,目的是获得具有语义特征提取/推理能力的 θ \theta θ 。假设有另外一个任务 (Pretext task ),可以近似获得 θ \theta θ。 比如, A u t o − e n c o d e r Auto-encoder Auto−encoder ( A E \mathrm{AE} AE) , 表示为: g θ ( x ) : x → x g_{\theta}(x): x \rightarrow x gθ(x):x→x 。为什么 A E AE AE 可以近似 θ \theta θ 呢? 因为 AE 要重建 x x x 就必须学习 x x x 中的内在关系,而这种内在关系的学习又是有利于我们学习 $ f_{\theta}(x)$ 的。这种方式也叫做预训练,为了在目标任务上获得更好的泛化能力,一般还需要进行 f i n e − t u n i n g fine-tuning fine−tuning 等操作。在本文中,作者提出一个任务(拼图任务)的训练完成主任务(视频异常检测)
主要内容:
在本文中,提出了一种简单而有效的VAD自我监督学习方法,通过解决一个直观但具有挑战性的pretext任务,即时空拼图。通过这种排列,在帧内对补丁进行空间洗牌,以构建空间拼图,或者在时间上对连续帧序列进行洗牌,从而构建时间拼图。训练目标是从其空间或时间排列版本中恢复原始序列。
我们假设,成功解决此类难题需要网络通过学习强大的时空表示来理解视频帧的非常详细的空间和时间一致性,这对VAD至关重要。为此,我们考虑了所有可能的排列,以增加拼图的难度,目的是为区分特征提供细粒度的监督信号。基于异常事件通常涉及异常外观和异常运动的观察,我们在空间和时间维度上解耦了时空拼图,分别负责建模外观和运动模式。
贡献:
- 优化了自监督框架
- 允许网络从pretext任务中捕获细微的时空异常。为了确保计算效率,我们将解谜公式化为一个多标签学习问题,考虑了变化数量的因素。
- 无需预先训练的网络
作者方法的创新性:
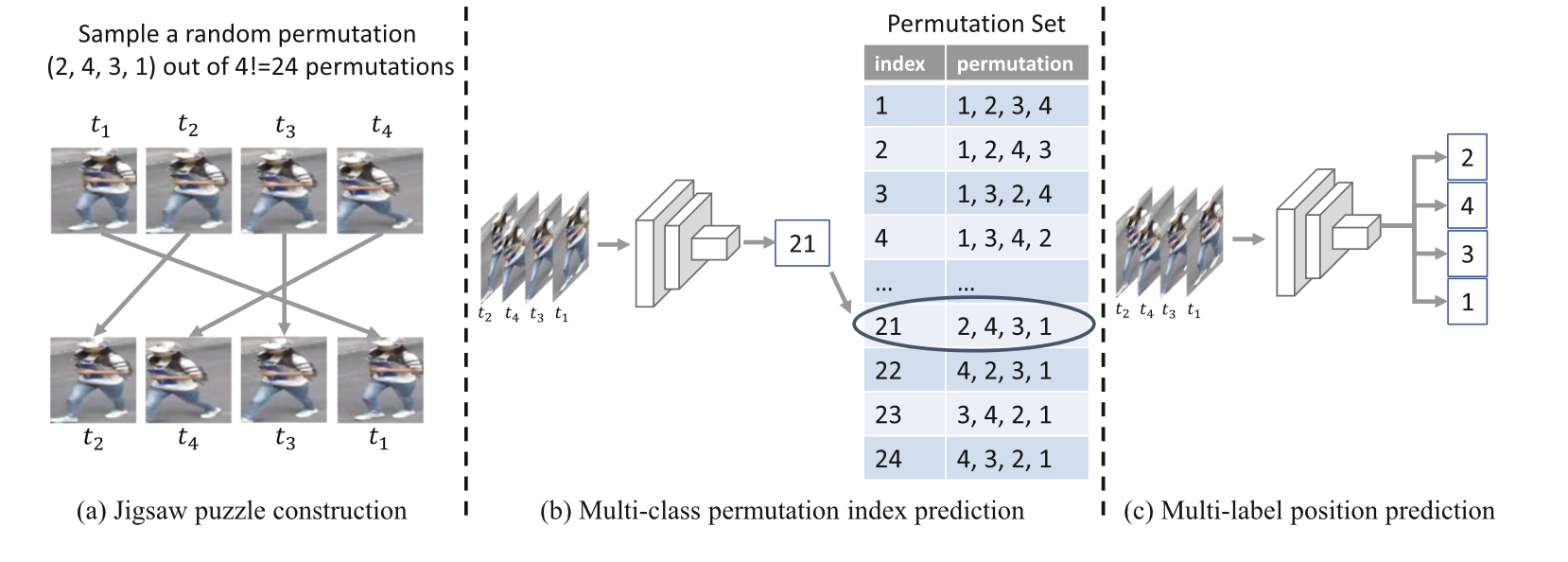
(a)将图片在时间顺序上随机打乱
(b) 传统方法:通过神经网络预测正确连续帧的排列组合
© 作者方法:直接预测输出连续帧的顺序
算法流程:
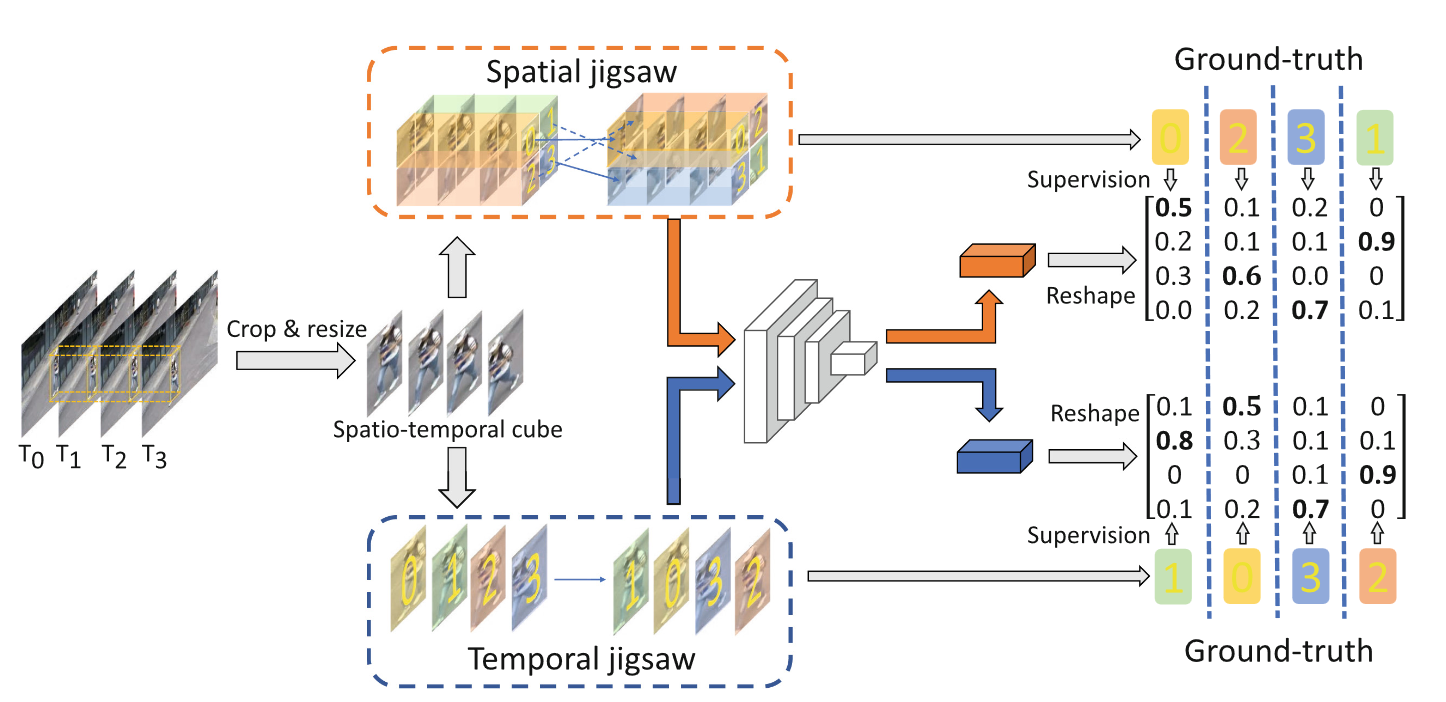
训练阶段主要步骤:
首先,使用现成的对象检测器[46]来提取帧中的所有对象,并沿时间维度堆叠对象以构建以对象为中心的立方体。从n!中排列组合中选择一个排列。对于每个立方体,我们进一步应用空间或时间洗牌来构建相应的空间或时间拼图。(Spatial jigswa\Temporal jisaw)
接着,在时间上或者空间上进行洗牌,训练目标是从其空间或时间排列版本中恢复原始序列(多标签分类问题)
最后,卷积神经网络充当拼图解算器,试图从其空间或时间排列版本中恢复原始序列。所提出的方法等效于解决多标签分类问题,并以端到端的方式进行训练。(预测出来的是一个预测矩阵,i位置的物体是在位置j的可能性)
测试阶段:
利用对象提取器提取所有对象,并沿时间维度堆叠对象以构建以对象为中心的立方体。不用经过洗牌,直接利用训练好的拼图解算器来获得规则性分数,并获得两个矩阵Ms和Mt,分别对应于空间和时间排列预测
如何评价?
正常事件的对角线(i,i) 的预测概率一定大于异常事件的。作者选择矩阵对角线上的最小分数作为生成的对象级规则性分数(因为根据训练中的细粒度多标签监督,只要错误预测了一个帧或补丁,示例就可能是异常的。)
{ r s = min ( diag ( M s ) ) r t = min ( diag ( M t ) ) \left\{\begin{array}{l} r_s=\min \left(\operatorname{diag}\left(M_s\right)\right) \\ r_t=\min \left(\operatorname{diag}\left(M_t\right)\right) \end{array}\right. {rs=min(diag(Ms))rt=min(diag(Mt))
diag(·)提取矩阵对角线,rs和rt表示对象级别的规则性得分
归一化:
{ R s = R s − min ( R s ) max ( R s ) − min ( R s ) R t = R t − min ( R t ) max ( R t ) − min ( R t ) \left\{\begin{aligned} R_s & =\frac{R_s-\min \left(R_s\right)}{\max \left(R_s\right)-\min \left(R_s\right)} \\ R_t & =\frac{R_t-\min \left(R_t\right)}{\max \left(R_t\right)-\min \left(R_t\right)} \end{aligned}\right. ⎩ ⎨ ⎧RsRt=max(Rs)−min(Rs)Rs−min(Rs)=max(Rt)−min(Rt)Rt−min(Rt)
加权得分:
R = w ∗ R s + ( 1 − w ) ∗ R t R=w * R_s+(1-w) * R_t R=w∗Rs+(1−w)∗Rt
实验:
实验参数
对象提取器(物体检测) : YoloV3 , 实验参数与Anomaly detection in video via self-supervised and multi-task learning. 原论文保持一致
评估指标:
具体来说,我们连接数据集中的所有帧,然后计算整体帧级AUC,即微平均AUROC
消融实验:
从四个方面:
a)排列数量;整体都在上升,并且做作者算法内存消耗小可以使用更大的数量,表现更好。
b) 帧数/补丁数;时间维度上的帧数(l)和空间维度上的面片数(n2),从5/4-9/16 先升高后恶化
c) 谜题类型;根据何时和哪些拼图游戏被激活,设计了四种可选配置 来验证多任务学习带来的效益
d)拼图游戏以外的其他pretext 任务。