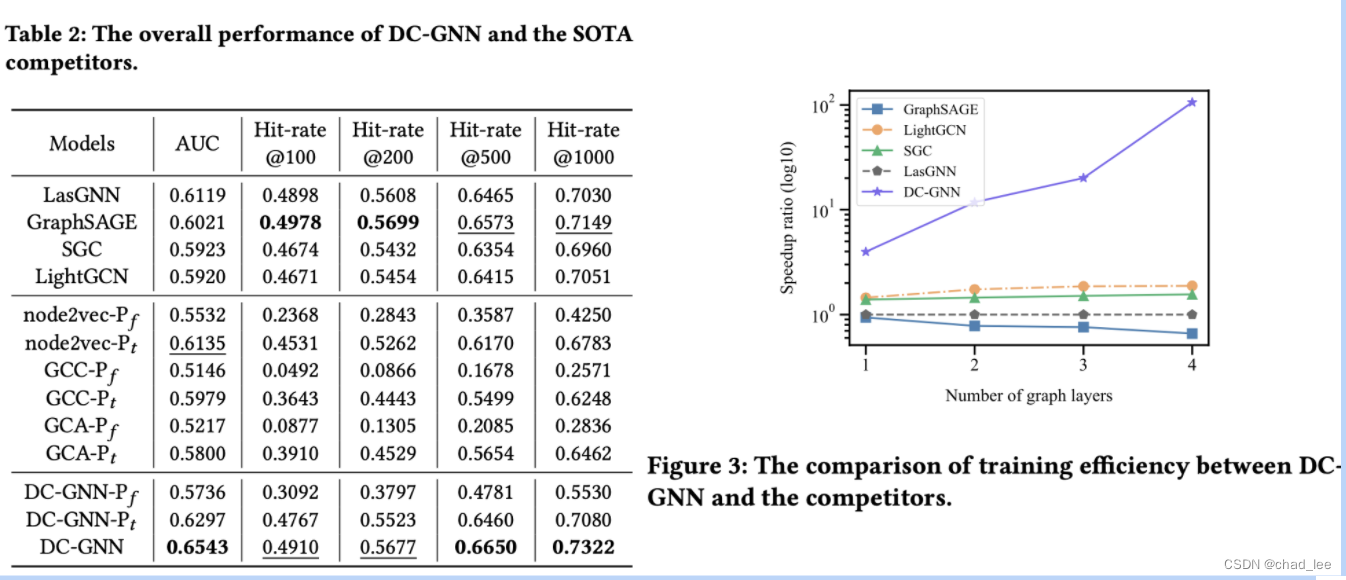
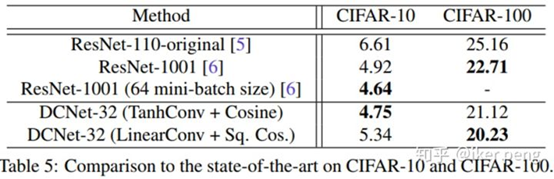
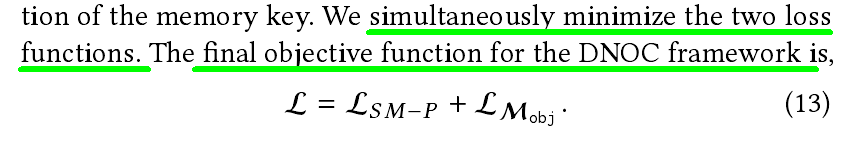通过传统知识蒸馏的解耦分析,DKD(Decoupled Knowledge Distillation)重新审视了暗知识的本质,并通过蒸馏损失函数的改进、获得DKD loss,显著改善了任务相关知识迁移的效果:

Paper地址:https://arxiv.org/abs/2203.08679
GitHub链接:GitHub - megvii-research/mdistiller: The official implementation of [CVPR2022] Decoupled Knowledge Distillation https://arxiv.org/abs/2203.08679
有关知识蒸馏的详细讨论,可参考:
知识蒸馏(Knowledge Distillation)

如上图所示,DKD通过将网络Classification Head预测的概率分布、解耦为目标分布与非目标分布,并分别计算二者的蒸馏Loss(Teacher的预测输出亦作相同解耦),然后进行加权求和获得新的蒸馏Loss。
DKD可改善传统得分蒸馏(Hinton KD)的知识迁移效果,其解耦改进的具体原理如下所述:
- 多类目预测得分的概率分布(The multi-class prediction probability),可拆分为目标分布与非目标分布,如下所示:

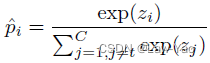
- 基于目标分布与非目标分布,传统得分蒸馏的损失函数,可推导为TCKD与NCKD的加权求和(加权系数为Teacher的目标概率):
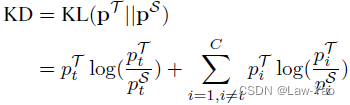

![]()
![]()
- 对于多类目分类任务,传统KD loss中Teacher的目标概率越高,NCKD越被抑制;然而,单独使用TCKD鲜有收益,而在某些场景下单独使用NCKD、可获得比TCKD更好的效果(详见论文的Ablation分析);并且,TCKD主要迁移难例相关的知识,NCKD则能够真正反映暗知识(Dark knowledge)。因此,为充分体现TCKD与NCKD的作用,通过引入二者的平衡系数,可重新构造获得新的损失函数(DKD Loss):
![]()
def dkd_loss(logits_student, logits_teacher, target, alpha, beta, temperature):gt_mask = _get_gt_mask(logits_student, target)other_mask = _get_other_mask(logits_student, target)pred_student = F.softmax(logits_student / temperature, dim=1)pred_teacher = F.softmax(logits_teacher / temperature, dim=1)pred_student = cat_mask(pred_student, gt_mask, other_mask)pred_teacher = cat_mask(pred_teacher, gt_mask, other_mask)log_pred_student = torch.log(pred_student)tckd_loss = (F.kl_div(log_pred_student, pred_teacher, size_average=False)* (temperature**2)/ target.shape[0])pred_teacher_part2 = F.softmax(logits_teacher / temperature - 1000.0 * gt_mask, dim=1)log_pred_student_part2 = F.log_softmax(logits_student / temperature - 1000.0 * gt_mask, dim=1)nckd_loss = (F.kl_div(log_pred_student_part2, pred_teacher_part2, size_average=False)* (temperature**2)/ target.shape[0])return alpha * tckd_loss + beta * nckd_loss