1. 数据结构
public final class ArrayMap<K,V> implements Map<K,V>
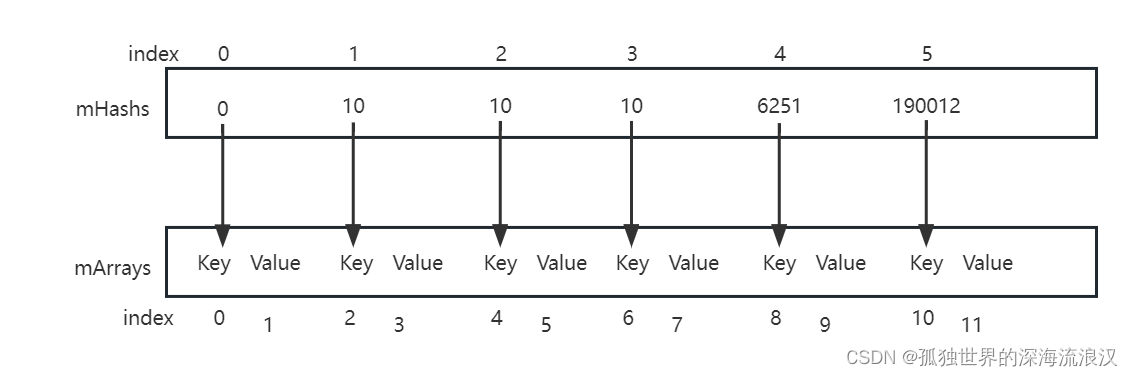
- 由两个数组组成,一个
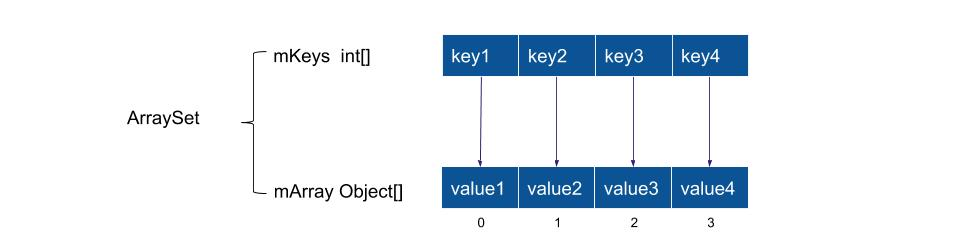
int[] mHashes用来存放Key的hash值,一个Object[] mArrays用来连续存放成对的Key和Value - mHashes数组按非严格升序排列
- 初始默认容量为0
- 减容:
- mHashes的长度就表征了 ArrayMap 当前的容量 ,而 mSize 则表征当前元素个数
- 删除元素后如果当前mHashes长度比 BASE_SIZE*2 大,但总元素个数又没到当前容量的 1/3 就减容
- 扩容:
- 插入元素时,如果需要扩容:
- 如果当前长度大于8,就按1.5倍扩容
- 如果当前长度大于4,小于8,就扩容到8
- 如果当前长度小于4,扩容到4
- 由于使用了hash,可能存在哈希冲突,结局方式:将相同的hash的key连续存放
- mHashes的index和Key、Value的下标对应关系
key = mArrays[index*2]–>key = mArrays[index << 1]value = mArrays[index*2 +1]-->value = mArrays[index<<1+1]
public final class ArrayMap<K, V> implements Map<K, V> {@UnsupportedAppUsage(maxTargetSdk = 28) // Hashes are an implementation detail. Use public key/value API.int[] mHashes;@UnsupportedAppUsage(maxTargetSdk = 28) // Storage is an implementation detail. Use public key/value API.Object[] mArray;@UnsupportedAppUsage(maxTargetSdk = 28) // Use size()int mSize;//扩容的判断条件private static final int BASE_SIZE = 4;}
2. 插入
public V put(K key, V value)
ArrayMap和HashMap一样,允许Key为null,且其hash默认置为0,且可以通过判空或者equals()来进行Hash冲突时,对目标Key的判断。在插入时,主要做了:
- 找到Key所在的mHashes下标
- 如果之前已经添加过,直接覆盖value
- 如果之前没有添加过,插入元素(可能需要先扩容)
@Override
public V put(K key, V value) {final int osize = mSize;final int hash;int index;if (key == null) {//key=null的时候认为hash=0,HashMap也是这样设计的!hash = 0;//根据key=null去寻找合适的index//----------解释(1)----------index = indexOfNull();} else {//如果key不为空,就可以获取一个hash值,可以用系统的方法,也可以用这个对象本身的hashcode()hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();//由于可能用到对象本身的hashcode()这久无法避免出现hash冲突//通过hash和key来查找合适的下标。为了避免hash冲突,还把key放进来了,可以通过equals()来处理hash冲突//----------解释(2)----------index = indexOf(key, hash);}//假设index找到了,是个正数,说明之前已经添加过这个key的元素了,直接对value进行替换!if (index >= 0) {//放在index/2+1的位置index = (index << 1) + 1;//把旧数据返回出去final V old = (V) mArray[index];//新数据填入mArray[index] = value;return old;}//如果之前没有添加过这个Key的元素,这下要添加,就要移动数组后续部分//index又取反回来,得到了之前找的最后一步end所在的位置,也就是需要插入的位置index = ~index;//如果需要扩容if (osize >= mHashes.length) {//1. 如果旧size超过了 base_size*2,那么新的大小为 osize * 1.5;//2. 如果还没超过 base_size*2://2.1 如果超过了 base_size, 那么新大小直接定为 base_size * 2;//2.2 否则,新大小直接定为 base_sizefinal int n =osize >= (BASE_SIZE * 2) ?(osize + (osize >> 1)) : (osize >= BASE_SIZE ? (BASE_SIZE * 2) : BASE_SIZE);final int[] ohashes = mHashes;//原来的hash数组final Object[] oarray = mArray;//原来的元素实体数组//根据 n 去申请一个新的数组//----------解释(3)----------allocArrays(n);if (mHashes.length > 0) {//把原来的值赋值填充到新的数组上去System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);System.arraycopy(oarray, 0, mArray, 0, oarray.length);}//“起死回生”,尝试将无用的原有数组用作缓存,如果不能用作缓存,就直接释放不管了//----------解释(3)----------freeArrays(ohashes, oarray, osize);}//判断是否需要扩容,并完成需要的扩容之后,开始插入元素//1. 平移一下,让出位置if (index < osize) {if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (osize - index)+ " to " + (index + 1));//元素的hash是一个接一个的,所以只需要挪动一个位置即可System.arraycopy(mHashes, index, mHashes, index + 1, osize - index);//但是元素本身存储,需要连着存储其key和value,占用两个数组单元,// 所以挪动的时候,需要将hash个数对应两倍的个数进行挪动System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);}if (CONCURRENT_MODIFICATION_EXCEPTIONS) {if (osize != mSize || index >= mHashes.length) {throw new ConcurrentModificationException();}}//2. 插入数据//可以看出来,index*2和 index*2+1连续两个位置,存放着key和value!// 也就是不用额外造一个对象,而是直接两个数据一起填入//mArray放的是数据[key0,value0,key1,value1,...,keyN,valueN,...]//mHashes则是在对应index存放key的hash值mHashes[index] = hash;mArray[index << 1] = key;mArray[(index << 1) + 1] = value;//更新mSizemSize++;//由于并没有把谁“覆盖掉”,所以不需要返回oldValue,直接返回null即可return null;
}
在此之前,认为读者已经熟知SparseArray的源码,了解其中的按位取反~设计、二分查找设计的思想。来看一下插入的大概流程:
解释(1)
indexOfNull()
可以看到,如果要插入的Key为null,需要在mHashes中查找hash=0的元素位置。除了null的hash=0,其他元素的hash也有可能为0,所以需要进行hash冲突情况下的key查找:
int indexOfNull() {final int N = mSize;if (N == 0) {//~~0可以得到接下来可以插入的位置(为0)return ~0;}//先找hash=0是否存在int index = binarySearchHashes(mHashes, N, 0);//如果之前都没有插入过hash=0的元素,直接返回一个负数//~index可以得到接下来可以插入的位置if (index < 0) {return index;}//如果存在hash=0,那么就找到对应的Key,如果是null,就对了if (null == mArray[index << 1]) {return index;}//如果存在hash=0,但是对应的key不是null,说明存在hash冲突int end;//index为Key的hash在mHashes[]中的下标//end<<1 = end*2 即定位到mArrays中Key的位置//由于相同的hash在mHashes[]中是连续存放的,所以只需要向左向右遍历判断Key是否一致即可//从index处的key开始向右遍历判断for (end = index + 1; end < N && mHashes[end] == 0; end++) {//如果找到了一个Key为null,就返回这个indexif (null == mArray[end << 1]) return end;}//如果找到结尾了都没找到,就往前找for (int i = index - 1; i >= 0 && mHashes[i] == 0; i--) {if (null == mArray[i << 1]) return i;}//如果整个mArrays[]都没有null这个key,就返回一个负数表示没有找到return ~end;
}
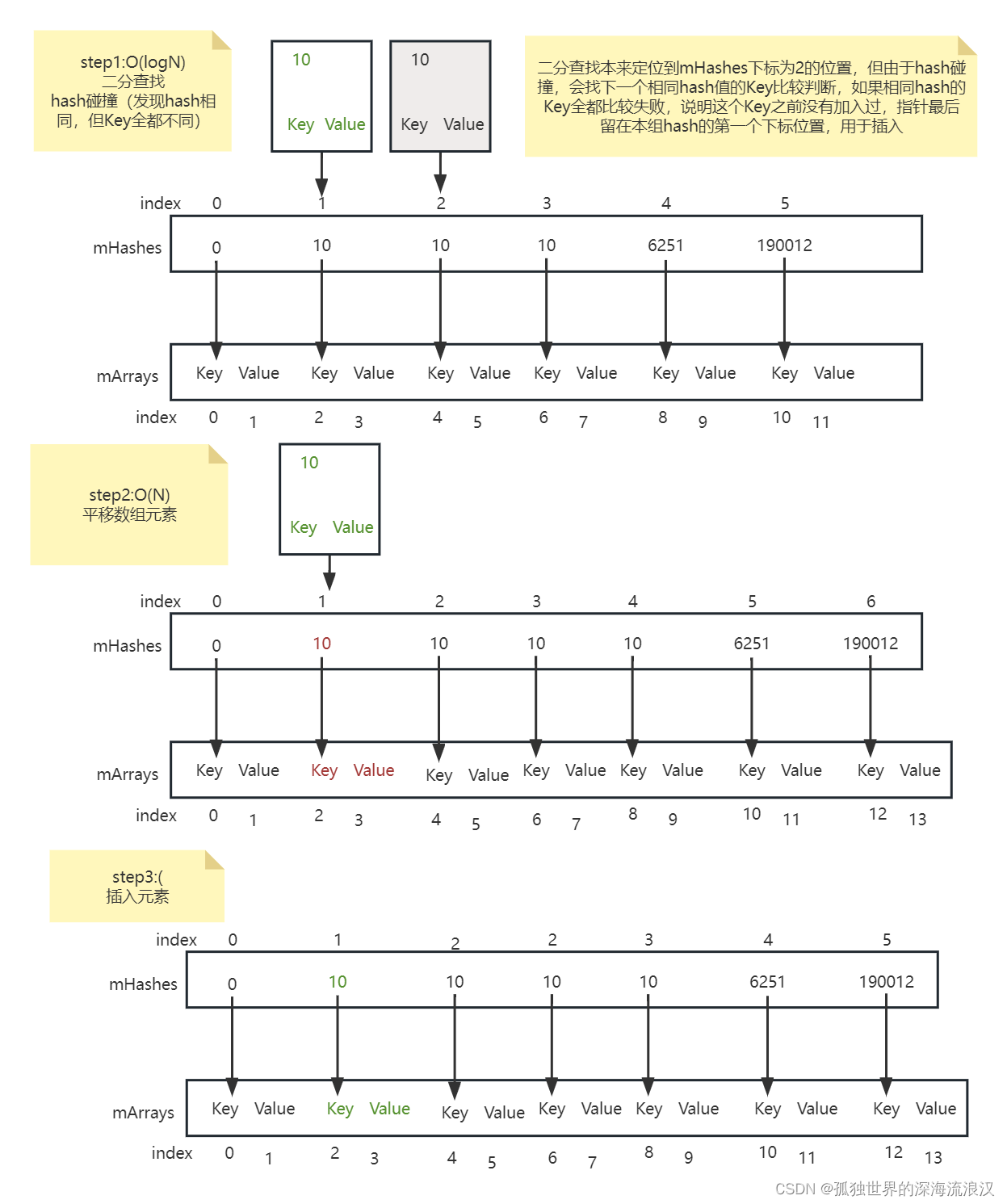
需要注意的是,二分查找找到一个hash,它不一定是一组连续相同hash的第一个index。
例如我们要查的Key的hash=10,相同的Key应当在mArrays中下标为2位置:
首先根据Key的hash值来快速定位Key的大致位置
- 二分发现值为10的hash在mHashes数组中下标index为2,其对应的Key的下标为index*2也就是4
进行hash冲突判断
- 发现在mArrays中index=4的Key,并不是我们要找的Key(发生了hash冲突)
接下来就要在这一组相同hash中查找和目标Key一样的Key
- 先向右遍历查找,找到了在mArrays中index=6的Key,但仍然不是我们要找的Key(假设我们要找的Key应当是mArrays中index=2的Key)
- 然后在向左遍历查找,最后找到了在mArrays中index=2的Key
如果在这一组相同hash中都查不到和目标Key一样的Key,就返回一个负数~end,表示之前并没有差如果这个Key。而且这个~end如果外界再次按位取反~~end就可以得到如果要插入该元素,应该插在哪个下标位置,进而移动数组,插入元素。
解释(2)
indexOf(Object key,int hash)
它的hash冲突处理方式与上述 解释(1) 中的思路一致。区别是传入参数,key是用来处理在hash冲突的情况下,找到正确的key。
hash直接使用的是key这个类自身的hashcode()或者系统的hash算法,不做额外处理:
hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();
index = indexOf(key, hash);
还有一个区别是比较Key时不再为比较null,而是使用key.equals()来比较:
//hash为原始哈希值,可能是系统的,也可能是用户自定义hashcode()的,
// key可以用来equals()来判断处理哈希冲突
@UnsupportedAppUsage(maxTargetSdk = 28)
int indexOf(Object key, int hash) {final int N = mSize;//如果一个元素都没有,直接返回负数,找不到,下一个插入的mHashes[]的位置为0if (N == 0) {//从0变为 -2^32return ~0;}//如果数组非空,就可以进行二分查找来找到下标//需要注意的是,ArrayMap的int[] mHashes是用来存储keys的hash的//通过它的下标位置*2(+1)可以得到Key和Value在mArrays[]中的位置。//由于使用了hash,所以需要处理hash冲突,ArrayMap将相同的hash连续存放在mHashes[]中,可以遍历这一组hash对应的key来查找目标Key// 也就是不论K的类型是什么,都以其hashcode作为key,升序保存//底层通过ContainerHelper来二分查找,如果是负数,说明没找到//但是对该负数按位取反可以得到最后一个检索到的下标int index = binarySearchHashes(mHashes, N, hash);//如果没找到,返回一个负数if (index < 0) {return index;}//如果之前插入的key有这个hash值的,那么定位到这个Key所在的位置(index*2)if (key.equals(mArray[index << 1])) {//如果没有hash冲突,这个位置就是我们要找的key,直接返回return index;}int end;//ArrayMap将相同的hash连续存放在mHashes[]中,可以遍历这一组hash对应的key来查找目标Key//mHashes[]从index+1开始往后找相同hash对应的Keyfor (end = index + 1; end < N && mHashes[end] == hash; end++) {if (key.equals(mArray[end << 1])) return end;}//由于二分定位到的hash的下标可能是这一组相同hash的中间某个元素,所以也要往前找一找for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {if (key.equals(mArray[i << 1])) return i;}//如果还是没找到,返回一个负数//~~end=end,可以用作插入的下标return ~end;
}
解释(3)
allocArrays(int size)
如果要扩容,就要根据新的长度去申请一块新的数组。源码中也发现了,扩容的逻辑是:
- 如果旧size超过了8,就按1.5倍来扩容
- 如果旧size在4和8之间,扩容到8
- 如果旧size小于4,扩容到4
@UnsupportedAppUsage(maxTargetSdk = 28)
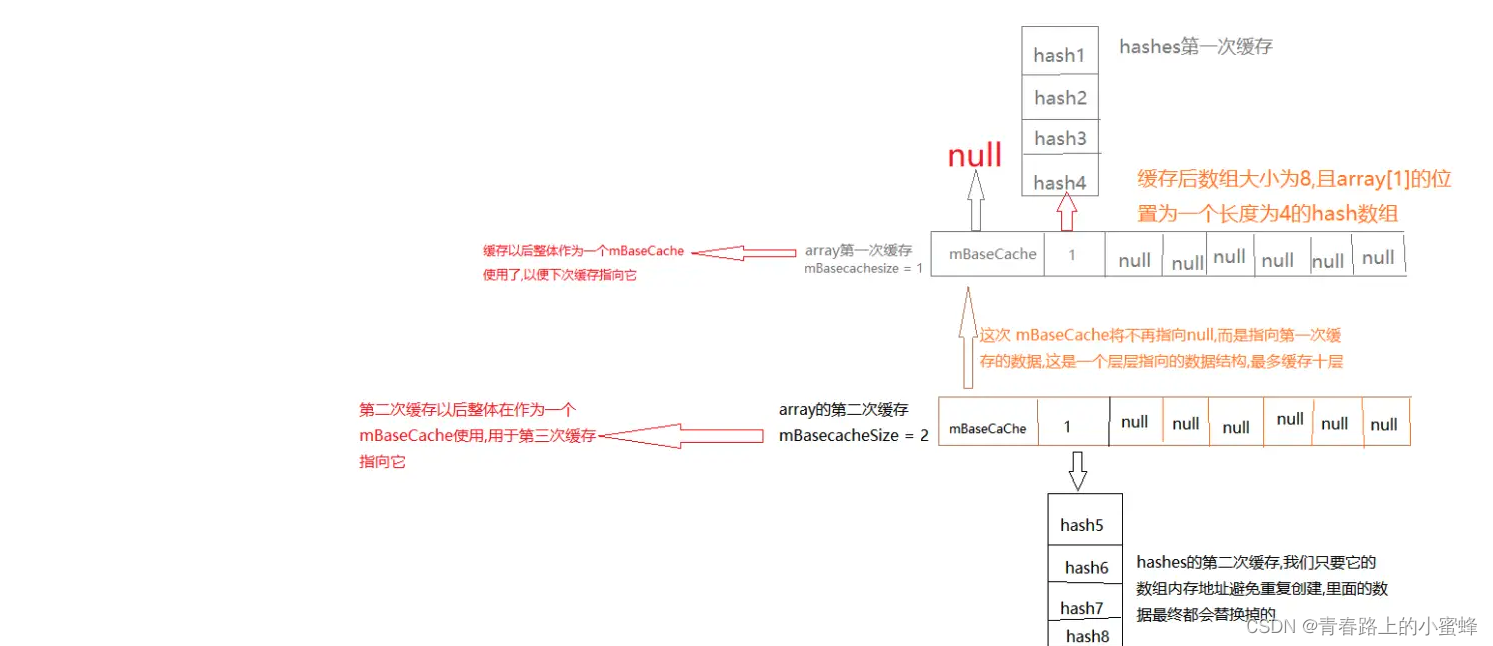
private void allocArrays(final int size) {if (mHashes == EMPTY_IMMUTABLE_INTS) {throw new UnsupportedOperationException("ArrayMap is immutable");}//如果需要扩容到8if (size == (BASE_SIZE * 2)) {synchronized (sTwiceBaseCacheLock) {if (mTwiceBaseCache != null) {//缓存(长度为4*2=8),不要再另外申请开辟空间了,这个缓存来自 freeArrays()final Object[] array = mTwiceBaseCache;//直接使用缓存空间mArray = array;try {mTwiceBaseCache = (Object[]) array[0];mHashes = (int[]) array[1];if (mHashes != null) {//如果都是空,就可用,returnarray[0] = array[1] = null;mTwiceBaseCacheSize--;return;}} catch (ClassCastException e) {}mTwiceBaseCache = null;mTwiceBaseCacheSize = 0;}}} else if (size == BASE_SIZE) {//如果新容量为4synchronized (sBaseCacheLock) {if (mBaseCache != null) {//使用缓存(长度为4),来自freeArrays()final Object[] array = mBaseCache;mArray = array;try {mBaseCache = (Object[]) array[0];mHashes = (int[]) array[1];if (mHashes != null) {array[0] = array[1] = null;mBaseCacheSize--;return;}} catch (ClassCastException e) {}mBaseCache = null;mBaseCacheSize = 0;}}}//如果扩容到更大的容量,或者缓存不可用,就新申请一块空间mHashes = new int[size];mArray = new Object[size << 1];
}
由于开辟一个数组需要时间,对于只需要容量为4和8的两种情况,直接尝试复用即可,复用缓存的情况一般出现在减容的过程中,因为扩容时总会经历扩容到4和8的情况。减容时可以复用之前被free掉的4和8容量的缓存。超过8容量的扩容直接申请新的数组即可。
解释(4)
put()过程中,如果需要扩容,紧接着就到了freeArrays(),释放原有的数组。如果被释放的数组长度为4或者8就分别缓存到mBaseCache和mTwiceBaseCache,更大的就不管了。这个缓存可以被 解释(3) 使用。
@UnsupportedAppUsage(maxTargetSdk = 28) // Allocations are an implementation detail.
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {//如果要释放的数组元素长度为8if (hashes.length == (BASE_SIZE * 2)) {synchronized (sTwiceBaseCacheLock) {if (mTwiceBaseCacheSize < CACHE_SIZE) {//原有mArrays[0]转为指向mTwiceBaseCache,第一次为nullarray[0] = mTwiceBaseCache;//原有mArrays[1]转为指向hashes数组array[1] = hashes;//将mArrays中剩余元素置空for (int i = (size << 1) - 1; i >= 2; i--) {//将原有元素置空array[i] = null;}//这个mArrays[]被拿来复用,由mTwiceBaseCache记录//每个ArrayMap允许有一个mTwiceBaseCache实例mTwiceBaseCache = array;//总缓存数+1,是类变量,全局唯一,避免整个进程出现过多的缓存mTwiceBaseCacheSize++;}}} else if (hashes.length == BASE_SIZE) {//如果要释放的数组元素长度为4synchronized (sBaseCacheLock) {if (mBaseCacheSize < CACHE_SIZE) {//原有mArrays[0]转为指向mBaseCache,第一次为nullarray[0] = mBaseCache;//原有mArrays[1]转为指向hashes数组array[1] = hashes;//将mArrays中剩余元素置空for (int i = (size << 1) - 1; i >= 2; i--) {array[i] = null;}//这个mArrays[]被拿来复用,由mBaseCache记录//每个ArrayMap允许有一个mBaseCache实例mBaseCache = array;//总缓存数+1,是类变量,全局唯一,避免整个进程出现过多的缓存mBaseCacheSize++;}}}
}
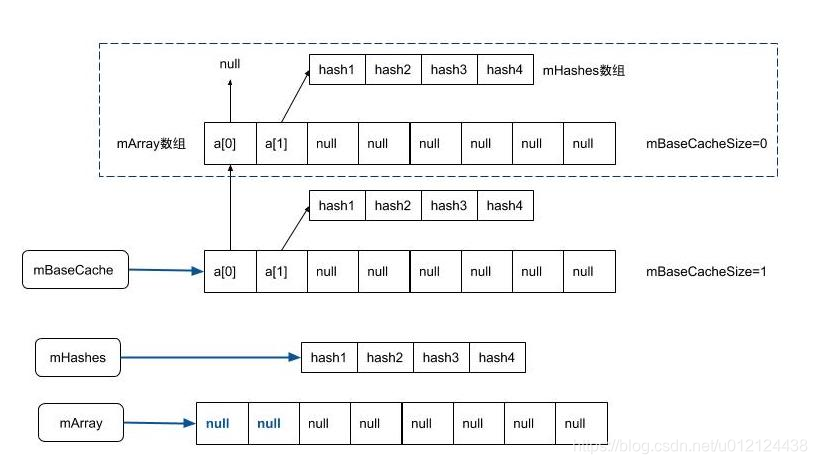
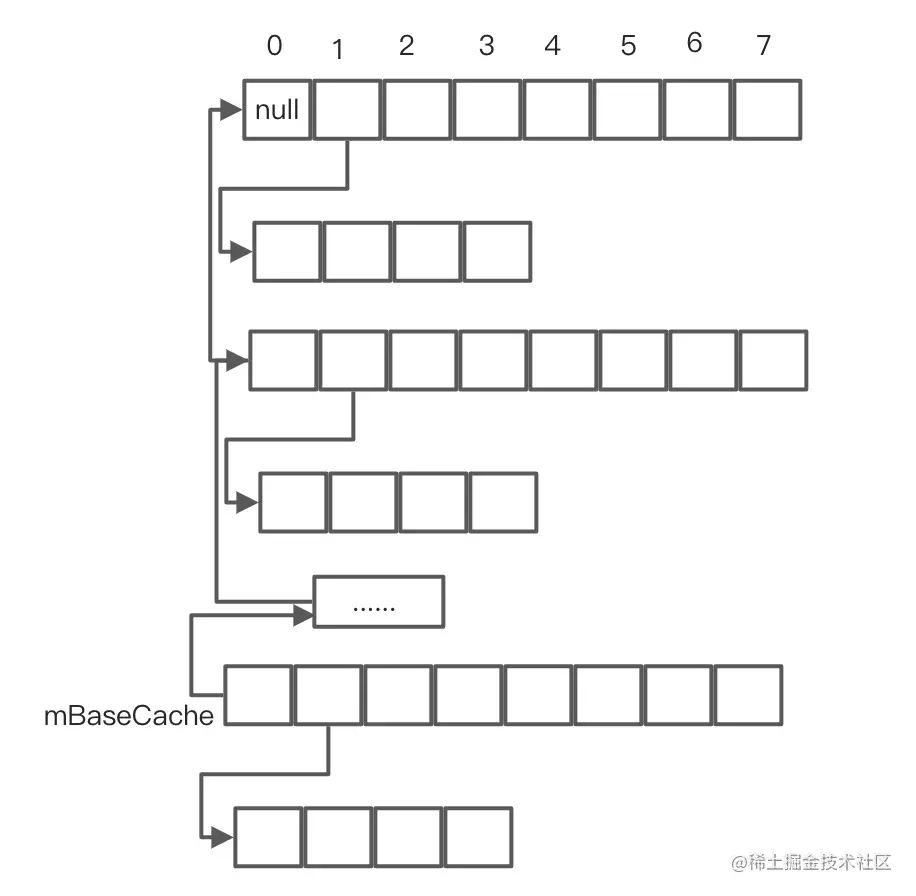
需要注意的是,整个进程中,mBaseCache和mTwiceBaseCache的数量都不允许超过 10。假设原先数组长度为4,但是需要扩容到8,则需要释放的两个数组被作为缓存,这个缓存的结构如下图所示:
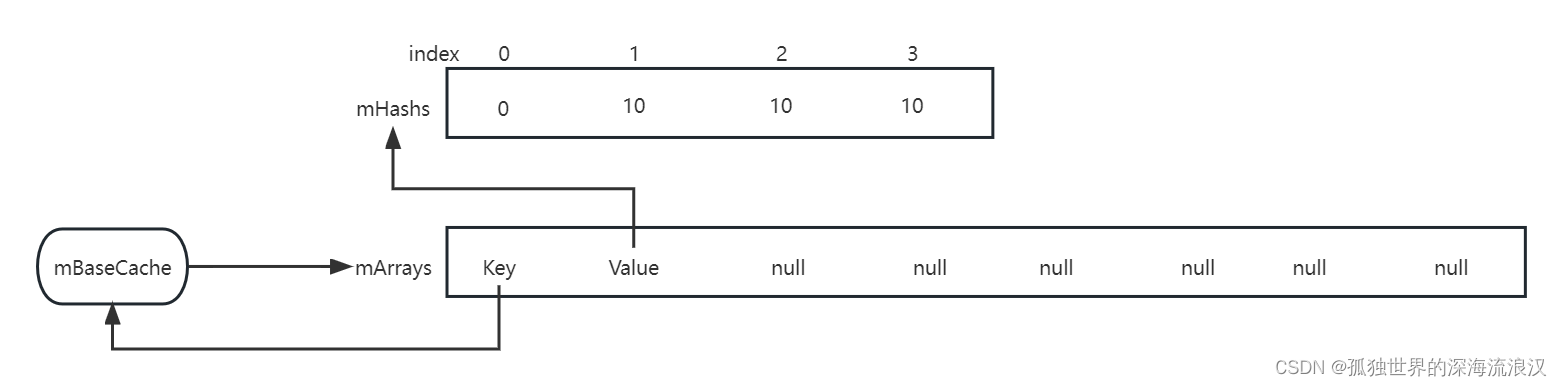
可以通过arrayMap.mBaseCache访问到被缓存的mArrays和mHashes,但mBaseCache在一个进程中不允许超过10个,mTwiceBaseCache也是一样的。
需要注意的是,这里的mHashes并没有清空,而mArrays被清空了。笔者认为有两个原因:
-
原因之一就是处理内存泄漏,mArrays对元素都是强引用,需要主动置空释放引用。mHashes没有引用问题,所以不用释放。
-
另一个原因就是在减容的过程中,如果复用了缓存,将会把新的数据填充进去,原先的mHashes的值会被覆盖,所以不用额外耗费精力去清空mHashes。
3. 删除
V remove(Object key)V removeAt(int index)
根据key删除元素,如果元素存在,将Value返回出去。删除元素过程中可能发生减容!!! 需要注意的是mHashes.length 和 mSize 是不同的。 mSize是真实元素个数, mHashes.length是容量。
如果发生了减容,并且减容后的容量为4或者8,就可能复用缓存。复用缓存的时候可以会把旧数组的数据拷贝进去。
@Override
public V remove(Object key) {//根据key找到元素在mHashes的下标,如果没找到返回负数final int index = indexOfKey(key);if (index >= 0) {//找到了该key在mHashes中的下标,根据index来删除元数,并返回value值return removeAt(index);}return null;
}//删除元素
public V removeAt(int index) {//越界判断if (index >= mSize && UtilConfig.sThrowExceptionForUpperArrayOutOfBounds) {throw new ArrayIndexOutOfBoundsException(index);}//记录一下 旧Valuefinal Object old = mArray[(index << 1) + 1];//旧sizefinal int osize = mSize;//计算新sizefinal int nsize;if (osize <= 1) {//删完后,为空// Now empty.//旧 mHashes[]final int[] ohashes = mHashes;//旧 mArrays[]final Object[] oarray = mArray;mHashes = EmptyArray.INT;mArray = EmptyArray.OBJECT;//尝试将原有数组标为缓存备用(如果原数组容量为4或8,且全局缓存不超过10个)freeArrays(ohashes, oarray, osize);nsize = 0;} else {//如果删完还剩下元素nsize = osize - 1;//如果空间浪费过多,就减容!//需要注意的是mHashes.length 和 mSize 是不同的。 mSize是真实元素个数, mHashes.length是容量if (mHashes.length > (BASE_SIZE * 2) && mSize < mHashes.length / 3) {//如果当前容量比BASE_SIZE*2来的大,但真实元素个数又没到当前容量的1/3//就减容!!! 核心目的就是为了减少内存消耗final int n = osize > (BASE_SIZE * 2) ? (osize + (osize >> 1)) : (BASE_SIZE * 2);//旧数据final int[] ohashes = mHashes;final Object[] oarray = mArray;//申请一块减容后长度的数组//如果减容后发现n=4或者8,可以尝试直接使用缓存allocArrays(n);if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}//拷贝时,就不拷贝该元素//先把这个元素之前的拷贝进去if (index > 0) {if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0");System.arraycopy(ohashes, 0, mHashes, 0, index);System.arraycopy(oarray, 0, mArray, 0, index << 1);}//再把这个元素之后的元素拷贝进去if (index < nsize) {if (DEBUG) Log.d(TAG, "remove: copy from " + (index + 1) + "-" + nsize+ " to " + index);System.arraycopy(ohashes, index + 1, mHashes, index, nsize - index);System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,(nsize - index) << 1);}} else {//如果不需要减容,就把后续的元素往前拷贝一位就够了,把要删除的元素覆盖掉if (index < nsize) {if (DEBUG) Log.d(TAG, "remove: move " + (index + 1) + "-" + nsize+ " to " + index);System.arraycopy(mHashes, index + 1, mHashes, index, nsize - index);System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,(nsize - index) << 1);}//将最后一位清空,防止引用错误、以及辅助GCmArray[nsize << 1] = null;mArray[(nsize << 1) + 1] = null;}}if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}//更新最新长度mSize = nsize;//返回旧的数据return (V) old;
}
4. 查找
V get(Object key)
插入部分分析完之后,剩下的逻辑就非常简单了。查找的逻辑就两步,根据key查找元素的hash所在mHashes[]的下标index,其Value位置对应为index*2+1
@Override
public V get(Object key) {//查找Key的hash在mHashes[]中的下标final int index = indexOfKey(key);//如果没找到,返回null,如果找到了,返回valuereturn index >= 0 ? (V) mArray[(index << 1) + 1] : null;
}
5. 根据index查找Key或者Value
K keyAt(int index)V valueAt(int index)
这部分代码也非常好理解,先是防越界(这里的界不是容量的界,而是真实数据的界,为什么要这样呢?因为有可能用到缓存,mHashes中,不再mSize范围中的部分会有脏数据!)然后就是根据下标计算拿到在mArrays中的Key或者Value
public K keyAt(int index) {if (index >= mSize && UtilConfig.sThrowExceptionForUpperArrayOutOfBounds) {// The array might be slightly bigger than mSize, in which case, indexing won't fail.// Check if exception should be thrown outside of the critical path.throw new ArrayIndexOutOfBoundsException(index);}return (K) mArray[index << 1];
}public V valueAt(int index) {if (index >= mSize && UtilConfig.sThrowExceptionForUpperArrayOutOfBounds) {// The array might be slightly bigger than mSize, in which case, indexing won't fail.// Check if exception should be thrown outside of the critical path.throw new ArrayIndexOutOfBoundsException(index);}return (V) mArray[(index << 1) + 1];
}
6. append() 插入
- ``append(K key, V value)`
和SparseArray的设计类似,如果连续插入hash递增的Key的元素,每次都二分查找效率是不够的,允许直接和当前最大hash值做判断。要么在末尾插入,要么二分查找合适的插入位置。
@UnsupportedAppUsage(maxTargetSdk = 28) // Storage is an implementation detail. Use put(K, V).
public void append(K key, V value) {int index = mSize;//先拿到key的hash值final int hash = key == null ? 0: (mIdentityHashCode ? System.identityHashCode(key) : key.hashCode());if (index >= mHashes.length) {//如果插入会发生越界,直接报错,不会智能地去扩容throw new IllegalStateException("Array is full");}if (index > 0 && mHashes[index - 1] > hash) {//如果key小,就正常的putput(key, value);return;}//否则,直接在最右边插入新元素即可mSize = index + 1;mHashes[index] = hash;index <<= 1;mArray[index] = key;mArray[index + 1] = value;
}
9. 遍历ArrayMap
K keyAt(int index)V valueAt(int index)int size()
在Parcel.writeArrayMapInternal()中的使用:
final int N = map.size();
for(int i = 0; i < N ; i++){writeString(map.keyAt(i));writeValue(map.valueAt(i));
}
8. validate()
validate()
使用append()可能导致ArrayMap失效,因为可能存在一样的Key出现在多处,validate()方法可以判断这个ArrayMap是否合法,如果有多处相同Key的问题存在,就抛出错误。主要用途还是用于判断经过IPC的unpack后的ArrayMap是否合法。也是因为IPC通信在发送端可能会有并发问题。
Android中的Bundle数据就是用ArrayMap来存储的
BaseBundle.mMap是ArrayMap<String,Object>类型的
最后会将mMap的数据写入Parcel
parcel.writeArrayMapInternal(map)
public void validate() {final int N = mSize;//如果只有一个元素,不可能出现重复Key的情况if (N <= 1) {// There can't be dups.return;}//需要前后比较hash是否相同,所以要先拿到第一个的hash值int basehash = mHashes[0];int basei = 0;for (int i = 1; i < N; i++) {int hash = mHashes[i];//如果遍历到的hash和前一个不一样if (hash != basehash) {//更新basehash = hash;basei = i;continue;}//如果hash一样,说明当时插入的时候出现了hash冲突// 这就需要检查Key是否equals()了//先拿到cur = Keyfinal Object cur = mArray[i << 1];//从hash冲突的index开始往前看,是否存在相同的Keyfor (int j = i - 1; j >= basei; j--) {final Object prev = mArray[j << 1];if (cur == prev) {//如果Key相同,说明之前出现了并发错误throw new IllegalArgumentException("Duplicate key in ArrayMap: " + cur);}if (cur != null && prev != null && cur.equals(prev)) {//如果都是非空元素,但是Key相同,说明之前出现了并发错误throw new IllegalArgumentException("Duplicate key in ArrayMap: " + cur);}}//如果一切正常,这个方法就不会抛出任何异常。}
}
总结
ArrayMap与SparseArray、HashMap、TreeMap的时间复杂度分析:
| 任务 | ArrayMap | 说明 | SparseArray | HashMap |
|---|---|---|---|---|
| 删除 | O(N) | 数组拷贝 | O(logN) | O(1) |
| 顺序插入 | O(1) or O(N) | O(1):append直接放在最后 O(N):移动数组 | O(1) or O(N) | O(1) |
| 随机插入 | O(logN) or O(N) | O(N):插入前可能要移动数组 O(logN):二分查找插入位置 | O(logN) or O(N) | O(1) |
| 逆序插入 | O(N) | O(logN):二分查找插入位置 O(N):必然要移动数组元素 | O(N) | O(1) |
| 更新 | O(logN) | O(logN):如果需要更新已存在的元素,只要二分查找的时间 | O(logN) | O(1) |
再来测算一下内存占用:
//TreeMap
Entry<K,V> root;// 21 * N Byte
class Entry<K,V>{//至少21 ByteK key;//4 ByteV value;//4 ByteEntry<K,V> left;//4 ByteEntry<K,V> right;//4 ByteEntry<K,V> parent;//4 Byteboolean color = BLACK;//1 Byte
}
//HashMap
Node<K,V>[] table;//16 * N Byte
class Node<K,V>{//至少16 Bytefinal int hash;//4 Bytefinal K key;//4 ByteV value;//4 ByteNode<K,V> next;//4 Byte
}
//SparseArray
int[] mKeys;//4 * N Byte
Object[] mValues;//4 * N Byte
//ArrayMap
int[] mHashes;//4 * N Byte
Object[] mArrays;//4 * 2* N Byte
如果不考虑缓存等内存占用:
- TreeMap一个元素至少占用 21 Byte
- HashMap一个元素至少占用 16 Byte
- SparseArray一个元素至少占用 8 Byte
- ArrayMap一个元素至少占用 12 Byte
ArrayMap虽然内存占用比SparseArray多,但其Key可以为任意类型,不局限于Integer,在这个情况下,与Key为任意类型的HashMap相比,又减少了许多内存占用。
所以,如果没有速度需求,尽量减少内存占用时:
- 如果Key为int类型,就使用SparseArray
- 如果Key为任意类型,就使用ArrayMap
随机插入的情况下,在10_000数据量下,HashMap、SparseArray、ArrayMap的执行速度差别并不大。