源码基于 API 25
主要参考文章:面试必备:ArrayMap源码解析
1、概述


截图自:面试必备:ArrayMap源码解析
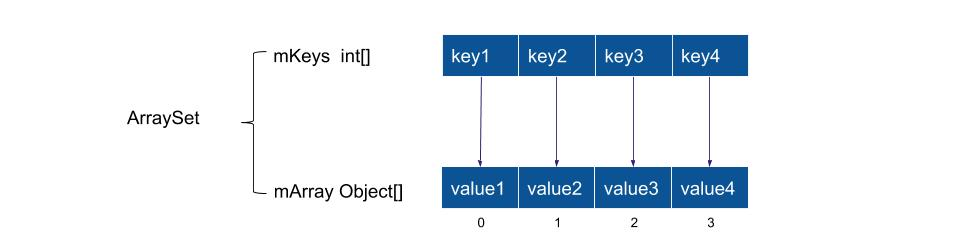
在开始讲解源码之前,需要说明 ArrayMap 的底层实现结构,即两个数组:
int[] mHashes; // 用于存储 key 对应的 hash 值
Object[] mArray; // 根据映射规则,用于存储 key 和 value
其中,mHashes 按照 hash 值的大小从到大排序,这样就可以实现二分查找。
假设对于某一 key,有对应的 hash 值 X,如果 X 在 mHashes 中对应的下标为 index,则对于 mArray,mArray[index<<1] 存储着 key,mArray[(index<<1)+1] 存储着 value。
因此,mArray 的长度是 mHashes 的两倍。
2、成员及构造函数
// 用于缓存数组用的,后面会说到
static Object[] mBaseCache;
static int mBaseCacheSize;
static Object[] mTwiceBaseCache;
static int mTwiceBaseCacheSize;// 判断通过 key 生成 hash 值时是否使用特殊的方法
final boolean mIdentityHashCode;int[] mHashes;
Object[] mArray;
int mSize;public ArrayMap() {this(0, false);
}/*** Create a new ArrayMap with a given initial capacity.*/
public ArrayMap(int capacity) {this(capacity, false);
}/** {@hide} */
public ArrayMap(int capacity, boolean identityHashCode) {mIdentityHashCode = identityHashCode;// If this is immutable, use the sentinal EMPTY_IMMUTABLE_INTS// instance instead of the usual EmptyArray.INT. The reference// is checked later to see if the array is allowed to grow.if (capacity < 0) {mHashes = EMPTY_IMMUTABLE_INTS;mArray = EmptyArray.OBJECT;} else if (capacity == 0) {mHashes = EmptyArray.INT;mArray = EmptyArray.OBJECT;} else {// allocArrays() 方法用于构建指定容量的 mHashes 和 mArrayallocArrays(capacity);}mSize = 0;
}/*** Create a new ArrayMap with the mappings from the given ArrayMap.*/
public ArrayMap(ArrayMap<K, V> map) {this();if (map != null) {putAll(map);}
}
3、成员方法
3.1 增
对于成员方法,其中,我认为 put(K key, V value) 方法是最先需要理解的,理解了 put(),其他的就好理解了。
public V put(K key, V value) {final int hash;int index;// 得到 key 的 hash 值,进一步的到该 hash 在 mHashes 中对应的 indexif (key == null) {hash = 0;index = indexOfNull();} else {// 根据 mIdentityHashCode 判断怎样生成 key 对应的 hash 值hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();// indexOf() 方法用于根据 key 以及其 hash 值得到在 mHashes 中对应的 indexindex = indexOf(key, hash);}// 如果 index >= 0,表示 key 已经存在,则直接替换对应位置的 valueif (index >= 0) {index = (index<<1) + 1;final V old = (V)mArray[index];mArray[index] = value;return old;}// 否则,该 key 原本没有,是需要新增的// 因此 ~index 为需要新增插入的位置index = ~index;if (mSize >= mHashes.length) {// 如果已经满了,则需要扩容final int n = mSize >= (BASE_SIZE*2) ? (mSize+(mSize>>1)): (mSize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);// 将原 mHashes、mArray 分别赋值给临时变量 ohashes、oarrayfinal int[] ohashes = mHashes;final Object[] oarray = mArray;// 将 mHashes、mArray 扩容到指定容量allocArrays(n);// 将原 mHashes、mArray 的值复制到新的数组中if (mHashes.length > 0) {System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);System.arraycopy(oarray, 0, mArray, 0, oarray.length);}// 将原数组进行回收缓存freeArrays(ohashes, oarray, mSize);}// 如果 index < mSize,则表示此时 mHashes[index] 本身是有值的,(后面对 indexOf() 方法的讲解会说明原因)// 因此需要将 index 及之后的往后挪动一位,// 避免原本的 mHashes[index] 被覆盖if (index < mSize) {System.arraycopy(mHashes, index, mHashes, index + 1, mSize - index);System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);}mHashes[index] = hash;mArray[index<<1] = key;mArray[(index<<1)+1] = value;mSize++;return null;
}
其中,需要进一步讲解 indexOf() 方法:
int indexOf(Object key, int hash) {// mSize 对应 mHashes 有效的长度final int N = mSize;// Important fast case: if nothing is in here, nothing to look for.if (N == 0) {return ~0;}// mHashes 中的 hash 元素是根据其大小排列的// 使用二分查找法得到目标索引值。// 关于 ContainerHelpers.binarySearch() 的实现可以参阅:// https://blog.csdn.net/OneDeveloper/article/details/89811122int index = ContainerHelpers.binarySearch(mHashes, N, hash);// If the hash code wasn't found, then we have no entry for this key.// 如果目标 key 不存在,直接返回if (index < 0) {return index;}// If the key at the returned index matches, that's what we want.// 如果根据 index 在 mArray 中对应的 mArray[index<<1](即索引对应的 key) 与目标 key 相等if (key.equals(mArray[index<<1])) {return index;}// Search for a matching key after the index.// 如果 index 直接对应的 key 与目标 key 不一致,则从 index+1 开始往后比对,找到 hash 值相等,且 key 相等的位置// 注意这里是要的 mHashes[end] == hash,相等即表示有多个 hash 值是一样的,即存在 hash 冲突的。// (因为这里解决哈希冲突的办法是开放地址法)// index 为某一 key 的 hash 值在 mHashes 数组的下标,而 index << 1 就转换为了 mArray 中对应 key 的下标int end;for (end = index + 1; end < N && mHashes[end] == hash; end++) {if (key.equals(mArray[end << 1])) return end;}// Search for a matching key before the index.// 如果往后没找到,则往前找,因为得到的 index 不一定相同 hash 中的第一个位置for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {if (key.equals(mArray[i << 1])) return i;}// Key not found -- return negative value indicating where a// new entry for this key should go. We use the end of the// hash chain to reduce the number of array entries that will// need to be copied when inserting.// 如果前后都没找到,则返回 ~end,end 即为往后遍历时出现 mHashes[end] != hash 时的位置。// 此时 end 对应的 mHashes[end] 可能已经存在值了return ~end;
}
涉及到哈希值,就会存在哈希冲突,而这里解决的方法,就是采用开放地址法,即如果 hash 值对应的 index 已经存在值了,则需要从 index 的两边去寻找与当前 key 匹配时对应的索引。
如果没有找到,则表示当前 key 原本不存在,需要新插入进来,而插入的位置,就是有着相同 hash 值且连续的子数组序列的末尾位置。

关于 ContainerHelpers.binarySearch() 的实现,可以参阅:SparseArray 笔记整理
indexOfNull() 的实现类似。
然后就是 allocArrays() 、freeArrays()。
// size 为目标容量大小,该方法的作用是将 mHashes、mArray 设置成指定的容量
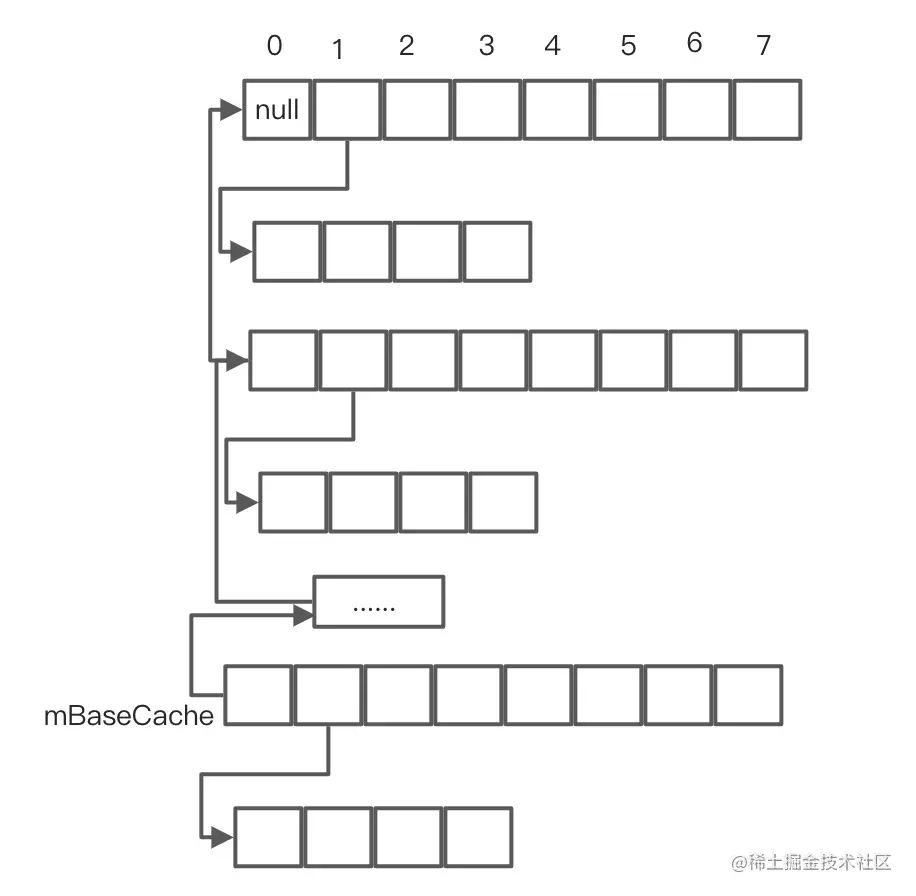
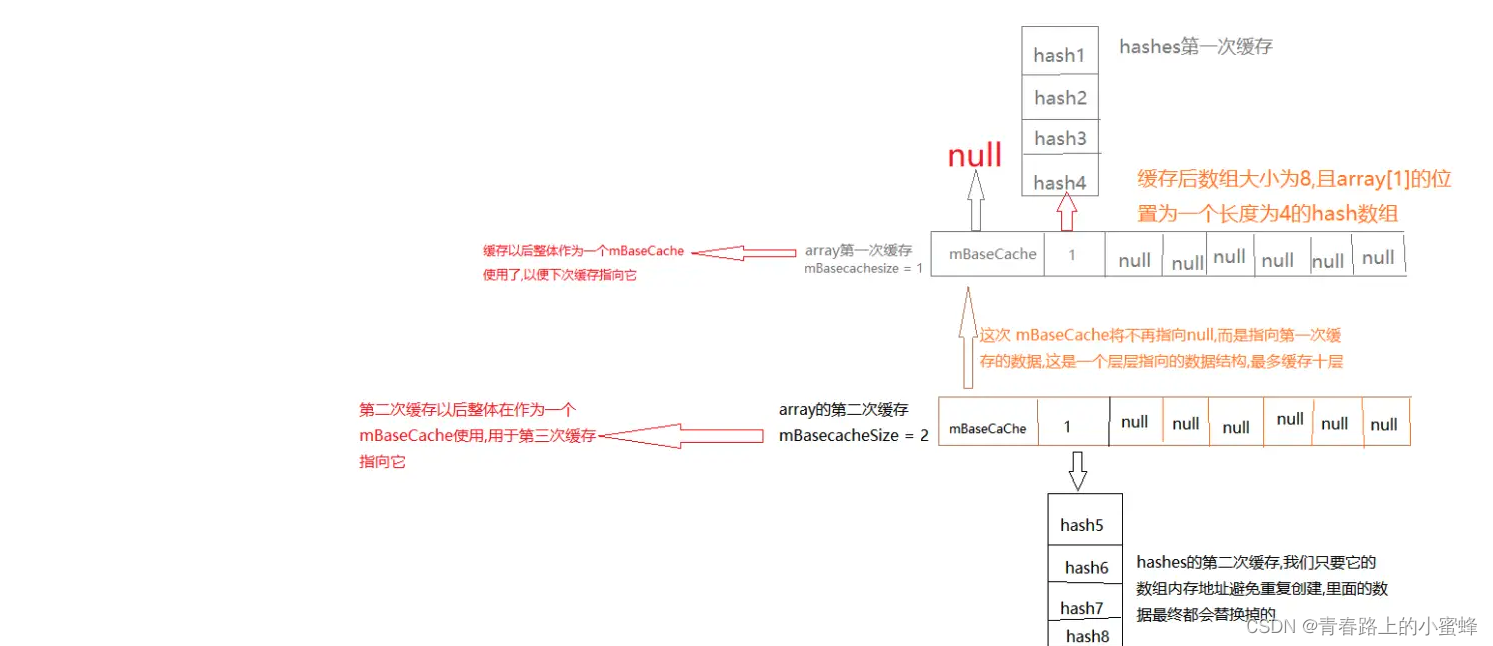
private void allocArrays(final int size) {if (mHashes == EMPTY_IMMUTABLE_INTS) {throw new UnsupportedOperationException("ArrayMap is immutable");}if (size == (BASE_SIZE*2)) {synchronized (ArrayMap.class) {if (mTwiceBaseCache != null) {final Object[] array = mTwiceBaseCache;// 下面的引用变量的指向情况变化在后面有配图// mTwiceBaseCache 本身就是一个 Object 数组,则该数组中的每一个元素是不定的,// 可以是任意 Object,如 int 数组,因为任何一个类都继承自 Object。// 这里将 mTwiceBaseCache 赋值给 mArray,即直接复用缓存的 Object 数组,提高效率// 之后在给 mArray[0] 赋值时,是不会影响到 array[0] 的,// 因此赋值就会把原 mArray[0] 指向 array[0] 的引用给覆盖掉,即 mArray[0] 不再指向 array[0]mArray = array;// 将缓存的 Object[] 数组赋值给 mArray,实现复用// 将原 mTwiceBaseCache[0] 赋值给 mTwiceBaseCachemTwiceBaseCache = (Object[])array[0];// 将原 mTwiceBaseCache[1] 赋值给 mHashesmHashes = (int[])array[1];// 将缓存的 int 数组赋值给 mHashes,实现复用// 将 array[0]、array[1] 这两个引用的指向置为 nullarray[0] = array[1] = null;mTwiceBaseCacheSize--;// return 了return;}}} else if (size == BASE_SIZE) {synchronized (ArrayMap.class) {if (mBaseCache != null) {final Object[] array = mBaseCache;mArray = array;mBaseCache = (Object[])array[0];mHashes = (int[])array[1];array[0] = array[1] = null;mBaseCacheSize--;return;}}}mHashes = new int[size];mArray = new Object[size<<1];
}
allocArrays() 不单单只为了实现扩容,另一方面,也可以实现缩容(在 remove 的时候会涉及)。因为该方法的作用是为了将 mHashes、mArray 设置成指定的容量。
配图:
原本的指向:
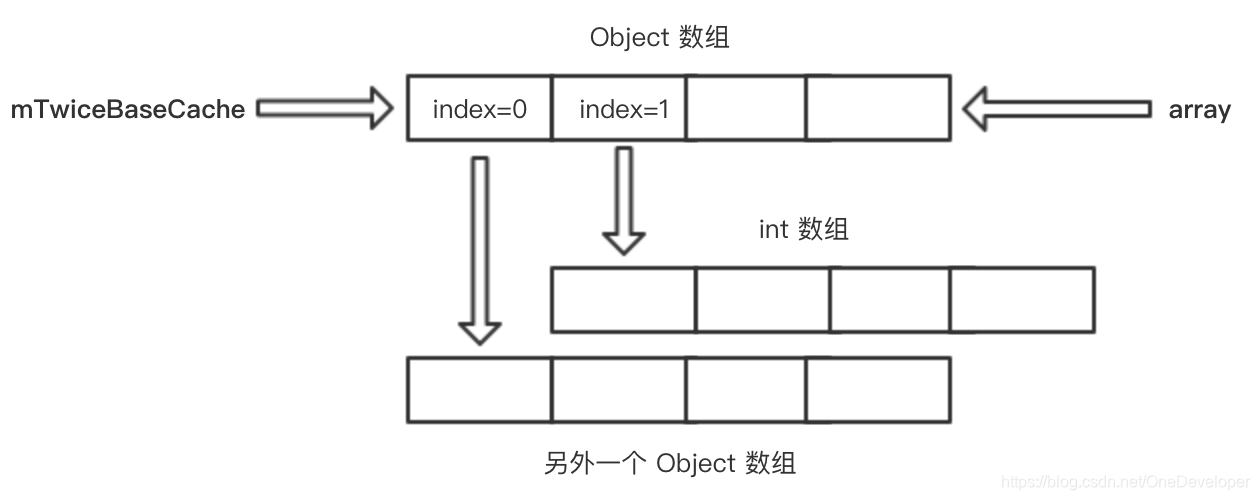
后面的指向:
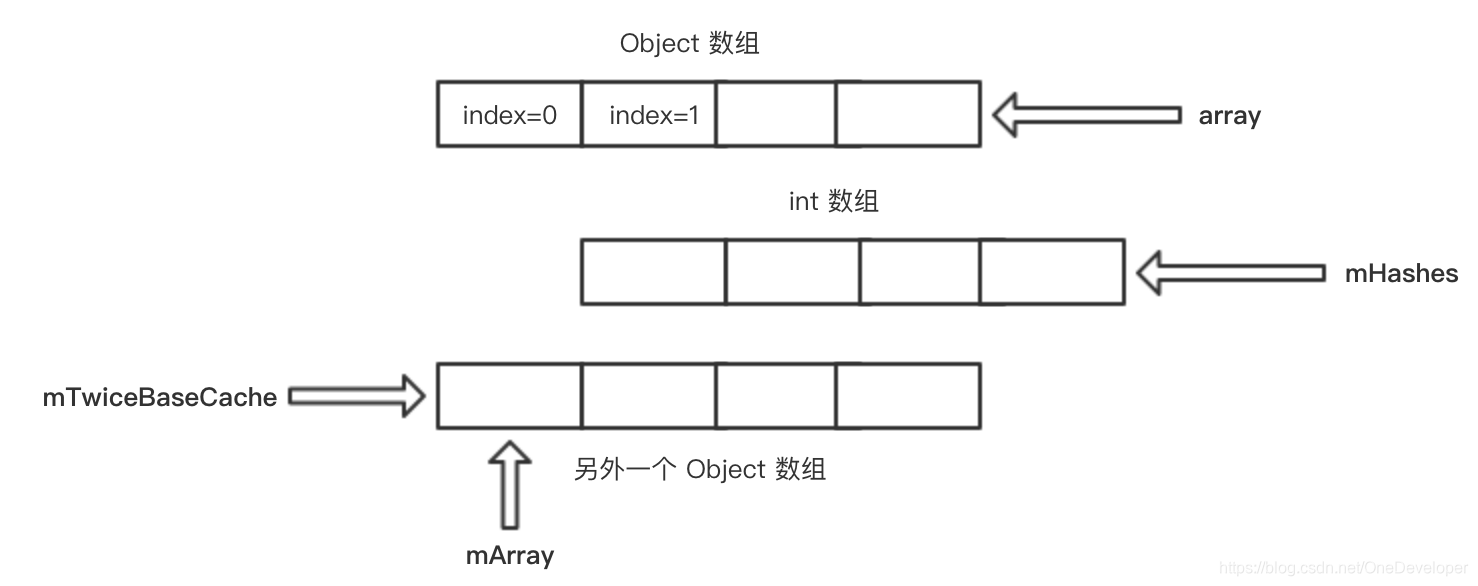
// 如果符合条件,将 hashes、array 数组缓存起来,用以复用
private static void freeArrays(final int[] hashes, final Object[] array, final int size) if (hashes.length == (BASE_SIZE*2)) {synchronized (ArrayMap.class) {if (mTwiceBaseCacheSize < CACHE_SIZE) {// 在 allocArrays() 中,mTwiceBaseCache 指向了另外一个 Object 数组,如图array[0] = mTwiceBaseCache;array[1] = hashes;for (int i=(size<<1)-1; i>=2; i--) {array[i] = null;}// 然后将 mTwiceBaseCache 重新指向原本的 Object 数组mTwiceBaseCache = array;mTwiceBaseCacheSize++; }}} else if (hashes.length == BASE_SIZE) {synchronized (ArrayMap.class) {if (mBaseCacheSize < CACHE_SIZE) {array[0] = mBaseCache;array[1] = hashes;for (int i=(size<<1)-1; i>=2; i--) {array[i] = null;}mBaseCache = array;mBaseCacheSize++; }}}
}
freeArrays() 则会将传递过来的老的 hashes、array,根据条件,进行缓存回收。
理解了 put() 方法,则基本理解了 ArrayMap 的实现原理。
public void putAll(ArrayMap<? extends K, ? extends V> array) {final int N = array.mSize;ensureCapacity(mSize + N);if (mSize == 0) {if (N > 0) {System.arraycopy(array.mHashes, 0, mHashes, 0, N);System.arraycopy(array.mArray, 0, mArray, 0, N<<1);mSize = N;}} else {for (int i=0; i<N; i++) {put(array.keyAt(i), array.valueAt(i));}}
}
而 putAll() 则是基于 put() 方法实现的。

截图自:面试必备:ArrayMap源码解析
3.2 删
public V removeAt(int index) {final Object old = mArray[(index << 1) + 1];if (mSize <= 1) {// Now empty.freeArrays(mHashes, mArray, mSize);// 将 mHashes 置为空 int 数组(即 int[0])mHashes = EmptyArray.INT;// 将 mArray 置为空 Object 数组(即 Object[0])mArray = EmptyArray.OBJECT;mSize = 0;} else {if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {// Shrunk enough to reduce size of arrays. We don't allow it to// shrink smaller than (BASE_SIZE*2) to avoid flapping between// that and BASE_SIZE.final int n = mSize > (BASE_SIZE*2) ? (mSize + (mSize>>1)) : (BASE_SIZE*2);final int[] ohashes = mHashes;final Object[] oarray = mArray;// 这里就涉及到了缩容,即缩小 mHashes 的大小到 n,缩小 mArray 的大小到 2*nallocArrays(n);mSize--;// 将原本的值复制到新的缩容后的数组中if (index > 0) {// 先复制 0 到 index 的部分System.arraycopy(ohashes, 0, mHashes, 0, index);System.arraycopy(oarray, 0, mArray, 0, index << 1);}if (index < mSize) {// 在复制 index+1 到末尾的部分System.arraycopy(ohashes, index + 1, mHashes, index, mSize - index);System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,(mSize - index) << 1);}} else {mSize--;// 将 index+1 开始的往前挪动一位,覆盖掉 index,从而 remove 掉 index 对应的 key-valueif (index < mSize) {System.arraycopy(mHashes, index + 1, mHashes, index, mSize - index);System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,(mSize - index) << 1);}// 因为往前挪动了一位,所以最后一位要设置为 nullmArray[mSize << 1] = null;mArray[(mSize << 1) + 1] = null;}}return (V)old;
}
在删除的时候,根据元素数量和集合占用的空间情况,判断是否要执行收缩操作。
并且类似 ArrayList,用复制操作去覆盖元素达到删除的目的。
public V remove(Object key) {final int index = indexOfKey(key);if (index >= 0) {return removeAt(index);}return null;
}
remove() 则是基于 removeAt() 实现的。
public boolean removeAll(Collection<?> collection) {return MapCollections.removeAllHelper(this, collection);
}// MapCollections.java
public static <K, V> boolean removeAllHelper(Map<K, V> map, Collection<?> collection) {int oldSize = map.size();Iterator<?> it = collection.iterator();while (it.hasNext()) {map.remove(it.next());}// 如果元素数量与原来不等,说明成功删除元素return oldSize != map.size();
}
3.3 查
public V get(Object key) {final int index = indexOfKey(key);return index >= 0 ? (V)mArray[(index<<1)+1] : null;
}
查找是基于 indexOfKey() 的,因此关于解决查找时的哈希冲突看前面对 indexOfKey() 方法的讲解。
4、总结
- 每次插入时,根据 key 的哈希值,利用二分查找,去寻找 key 在 int[] mHashes 数组中的下标位置
- 如果出现了 hash 冲突,则从需要从目标点向两头遍历,找到正确的 index
- 扩容时,会查看之前是否有缓存的 int[] 数组和 object[] 数组,如果有,复用给 mArray
- mHashes
- 扩容规则:如果 mSize >= 8,则扩容为原来的 1.5 倍,否则,mSize >= 4,扩容为 8,mSize < 4,则扩为 4
- 根据 key 的 hash 值在 mHashs 中的 index,如何得到 key、value 在 mArray 中的下标位置呢?
key 的位置是 index2(由 index<<1 得到),value 的位置是 index2+1,也就是说 mArray 是利用连续的两位空间去存放 key、value - 根据元素数量和集合占用的空间情况,判断是否要执行收缩操作, 如果 mHashes 长度大于 8,且集合长度小于当前空间的 1/3,则执行一个 shrunk,收缩操作,避免空间的浪费
- 类似 ArrayList,用复制操作去覆盖元素达到删除的目的。
摘抄自:面试必备:ArrayMap源码解析