SparseArray
SparseArray核心代码
两个构造函数默认数组容量10
public SparseArray() {this(10);
}
public SparseArray(int initialCapacity) {if (initialCapacity == 0) {mKeys = EmptyArray.INT;mValues = EmptyArray.OBJECT;} else {mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);mKeys = new int[mValues.length];}mSize = 0;
}//通过 key 来返回对应的 value,前面在分析 put() 的时候已经分析过了二分查找。那么这里如果找到了,就会通过下标直接从 mValues[] 中返回。
public E get(int key, E valueIfKeyNotFound) {int i = ContainerHelpers.binarySearch(mKeys, mSize, key);if (i < 0 || mValues[i] == DELETED) {return valueIfKeyNotFound;} else {return (E) mValues[i];}
}//This is Arrays.binarySearch(), but doesn't do any argument validation.
public static int binarySearch(int[] array, int size, int value) {int lo = 0;int hi = size - 1;while (lo <= hi) {// 高位+低位之各除以 2,写成右移,即通过位运算替代除法以提高运算效率final int mid = (lo + hi) >>> 1;final int midVal = array[mid];if (midVal < value) {lo = mid + 1;} else if (midVal > value) {hi = mid - 1;} else {return mid; // value found}}//若没找到,则lo是value应该插入的位置,是一个正数。对这个正数去反,返回负数回去return ~lo; // value not present
}public void put(int key, E value) {// 1.先进行二分查找int i = ContainerHelpers.binarySearch(mKeys, mSize, key);// 2. 如果找到了,则 i 必大于等于 0if (i >= 0) {mValues[i] = value;} else {// 3. 没找到,则找一个正确的位置再插入i = ~i;if (i < mSize && mValues[i] == DELETED) {mKeys[i] = key;mValues[i] = value;return;}//可能value元素已经被删除了if (mGarbage && mSize >= mKeys.length) {gc();//执行一次压缩,此gc非jvm的gc// 重新搜索一遍i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);}mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);mSize++;}
}public static int[] insert(int[] array, int currentSize, int index, int element) {//确认 当前集合长度 小于等于 array数组长度assert currentSize <= array.length;//不需要扩容if (currentSize + 1 <= array.length) {//将array数组内从 index 移到 index + 1,共移了 currentSize - index 个,即从index开始后移一位,那么就留出 index 的位置来插入新的值。System.arraycopy(array, index, array, index + 1, currentSize - index);//在index处插入新的值array[index] = element;return array;}//需要扩容,构建新的数组,新的数组大小由growSize() 计算得到int[] newArray = new int[growSize(currentSize)];//这里再分 3 阶段赋值。//1.将原数组中 index 之前的数据复制到新数组中System.arraycopy(array, 0, newArray, 0, index);//2.在index处插入新的值newArray[index] = element;//3.将原数组中 index 及其之后的数据赋值到新数组中System.arraycopy(array, index, newArray, index + 1, array.length - index);return newArray;
}public static int growSize(int currentSize) {//如果当前size 小于等于4,则返回8, 否则返回当前size的两倍return currentSize <= 4 ? 8 : currentSize * 2;
}public void removeAt(int index) {if (index >= mSize && UtilConfig.sThrowExceptionForUpperArrayOutOfBounds) {throw new ArrayIndexOutOfBoundsException(index);}if (mValues[index] != DELETED) {mValues[index] = DELETED;mGarbage = true;}
}删除了某个元素之后,被删除元素所占用的那个位置上的数据就标记成了垃圾数据,然后就会通过`gc`来去除这个位置上的元素,而本质上,对于数组而言,就是挪动位置覆盖掉这个位置咯,gc() 完之后,下标 i 可能会发生变化,因此需要重新查找一次,以得到一个新的下标 i。
private void gc() {int n = mSize;int o = 0;int[] keys = mKeys;Object[] values = mValues;for (int i = 0; i < n; i++) {Object val = values[i];if (val != DELETED) {if (i != o) {keys[o] = keys[i];values[o] = val;values[i] = null;}o++;}}mGarbage = false;mSize = o;
}
SparseArray总结:
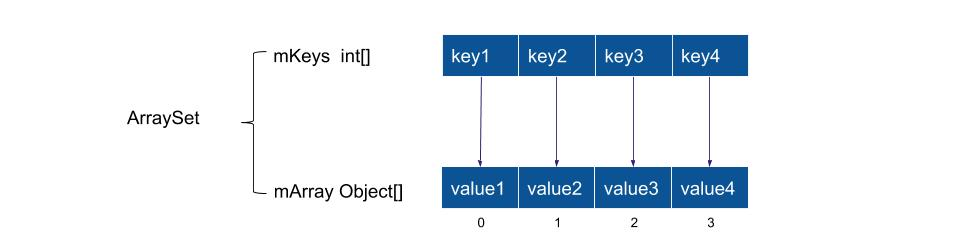
- 其内部主要通过 2 个数组来存储 key 和 value,分别是 int[] 和 Object[]。这也限定了其 key 只能为 int 类型,且 key 不能重复,否则会发生覆盖。
- 一切操作都是基于二分查找算法,将 key 以升序的方法 “紧凑” 的排列在一起,从而提高内存的利用率以及访问的效率。相比较 HashMap 而言,这是典型的时间换空间的策略。
- 删除操作并不是真的删除,而只是标记为 DELETE,以便下次能够直接复用。
ArrayMap核心代码
构造函数
public ArrayMap() {this(0, false);
}
public ArrayMap(int capacity) {this(capacity, false);
}
/**
默认容量大小就是 0,需要等待到插入元素时才会进行扩容的动作。
构造方法中的另一个参数 identityHashCode 控制 hashCode 是由 System 类产生还是由 Object.hashCode() 返回。
这两者之间的实现其实没太大区别,因为 System 类最终也是通过 Object.hashCode() 来实现的。
其主要就是对 null 进行了特殊处理,比如一律为 0。而在 ArrayMap 的 put() 方法中,如果 key 为 null 也将其 hashCode 视为 0 了。所
以这里 identityHashCode 为 true 或者 false 都是一样的。
*/
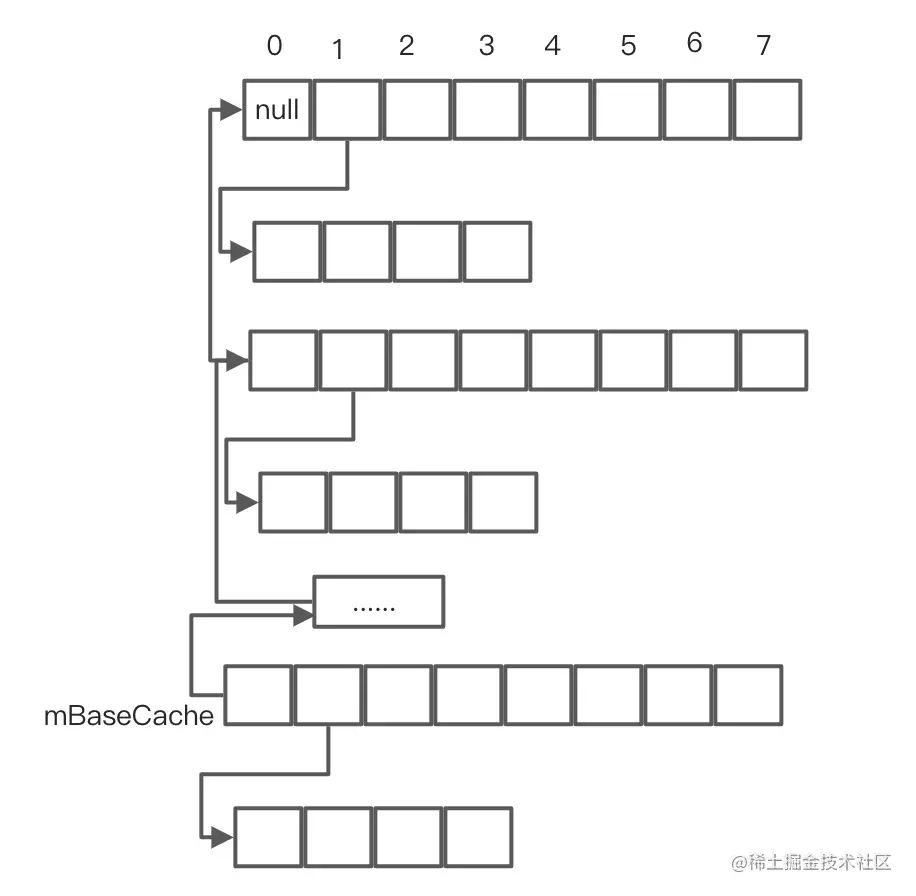
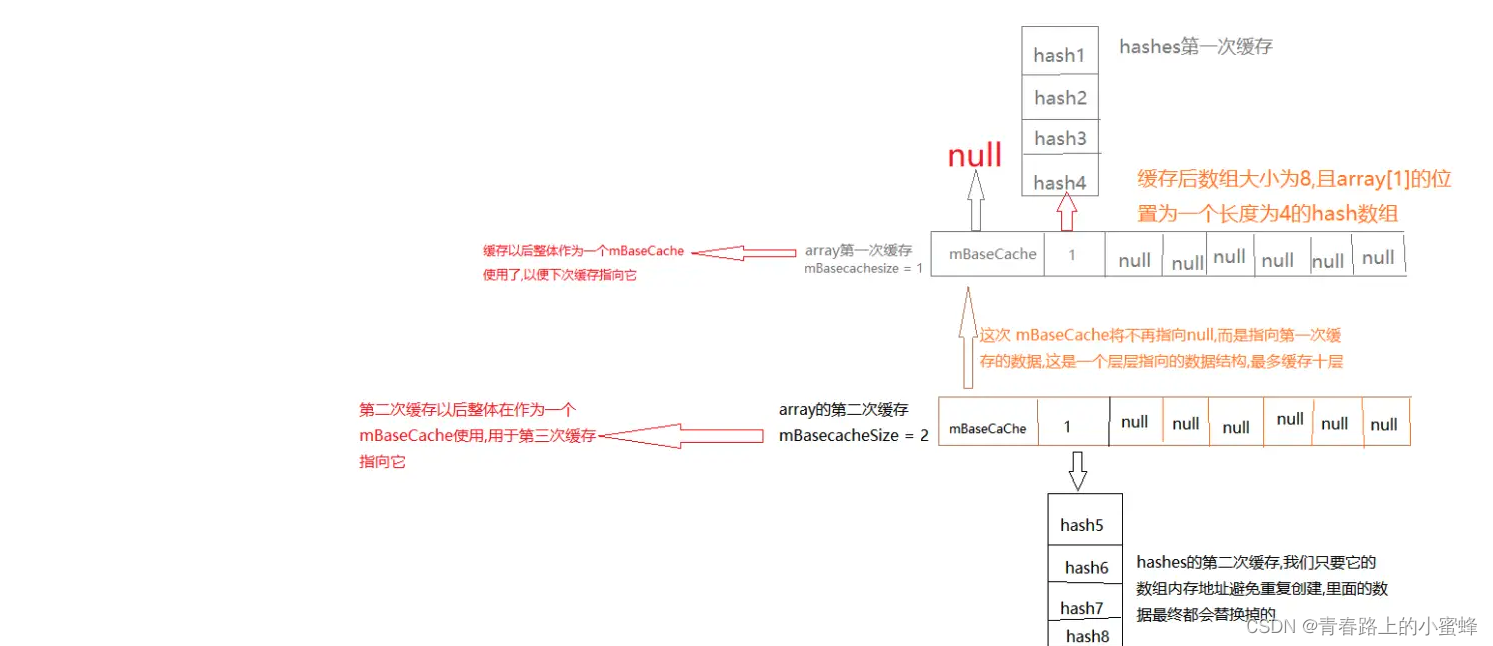
public ArrayMap(int capacity, boolean identityHashCode) {mIdentityHashCode = identityHashCode;if (capacity < 0) {mHashes = EMPTY_IMMUTABLE_INTS;mArray = EmptyArray.OBJECT;} else if (capacity == 0) {mHashes = EmptyArray.INT;mArray = EmptyArray.OBJECT;} else {allocArrays(capacity);}mSize = 0;
}插入元素
public V put(K key, V value) {final int osize = mSize;// 1.计算 hash code 并获取 indexfinal int hash;int index;if (key == null) {// 为空直接取 0hash = 0;index = indexOfNull();} else {// 否则取 Object.hashCode()hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();index = indexOf(key, hash);}// 2.如果 index 大于等于 0 ,说明之前存在相同的 hash code 且 key 也相同,则直接覆盖if (index >= 0) {index = (index<<1) + 1;final V old = (V)mArray[index];mArray[index] = value;return old;}// 3.如果没有找到则上面的 indexOf() 或者 indexOfNull() 就会返回一个负数,而这个负数就是由将要插入的位置 index 取反得到的,所以这里再次取反就变成了将进行插入的位置index = ~index;// 4.判断是否需要扩容if (osize >= mHashes.length) {final int n = osize >= (BASE_SIZE*2) ? (osize+(osize>>1)): (osize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);final int[] ohashes = mHashes;final Object[] oarray = mArray;// 5.申请新的空间allocArrays(n);if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}if (mHashes.length > 0) {if (DEBUG) Log.d(TAG, "put: copy 0-" + osize + " to 0");// 将数据复制到新的数组中System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);System.arraycopy(oarray, 0, mArray, 0, oarray.length);}// 6.释放旧的数组freeArrays(ohashes, oarray, osize);}if (index < osize) {// 7.如果 index 在当前 size 之内,则需要将 index 开始的数据移到 index + 1 处,以腾出 index 的位置System.arraycopy(mHashes, index, mHashes, index + 1, osize - index);System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);}if (CONCURRENT_MODIFICATION_EXCEPTIONS) {if (osize != mSize || index >= mHashes.length) {throw new ConcurrentModificationException();}}// 8.然后根据计算得到的 index 分别插入 hash,key,key和value存在同一个数组上mHashes[index] = hash;mArray[index<<1] = key;mArray[(index<<1)+1] = value;mSize++;return null;}
}int indexOf(Object key, int hash) {final int N = mSize;// 如果当前为空表,则直接返回 ~0,注意不是 0 ,而是最大的负数。if (N == 0) {return ~0;}//在 mHashs 数组中进行二分查找,找到 hash 的 index。int index = binarySearchHashes(mHashes, N, hash);//如果 index < 0,说明没有找到。if (index < 0) {return index;}//如果 index >= 0,且在 mArray 中对应的 index<<1 处的 key 与要找的 key 又相同,则认为是同一个 key,说明找到了。if (key.equals(mArray[index<<1])) {return index;}// 如果 key 不相同,说明只是 hash code 相同,那么分别向后和向前进行搜索,如果找到了就返回。如果没找到,那么对 end 取反就是当前需要插入的 index 位置int end;for (end = index + 1; end < N && mHashes[end] == hash; end++) {if (key.equals(mArray[end << 1])) return end;}for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {if (key.equals(mArray[i << 1])) return i;}return ~end;
}public V removeAt(int index) {final Object old = mArray[(index << 1) + 1];final int osize = mSize;final int nsize;// 如果 size 小于等于1 ,移除后数组长度将为 0。为了压缩内存,这里直接将mHashs 以及 mArray 置为了空数组if (osize <= 1) {// Now empty.if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to 0");final int[] ohashes = mHashes;final Object[] oarray = mArray;mHashes = EmptyArray.INT;mArray = EmptyArray.OBJECT;freeArrays(ohashes, oarray, osize);nsize = 0;} else {// size > 1 的情况,则先将 size - 1nsize = osize - 1;if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {// 如果上面的条件符合,那么就要进行数据的压缩。 // Shrunk enough to reduce size of arrays. We don't allow it to// shrink smaller than (BASE_SIZE*2) to avoid flapping between// that and BASE_SIZE.final int n = osize > (BASE_SIZE*2) ? (osize + (osize>>1)) : (BASE_SIZE*2);if (DEBUG) Log.d(TAG, "remove: shrink from " + mHashes.length + " to " + n);final int[] ohashes = mHashes;final Object[] oarray = mArray;allocArrays(n);if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}if (index > 0) {if (DEBUG) Log.d(TAG, "remove: copy from 0-" + index + " to 0");System.arraycopy(ohashes, 0, mHashes, 0, index);System.arraycopy(oarray, 0, mArray, 0, index << 1);}if (index < nsize) {if (DEBUG) Log.d(TAG, "remove: copy from " + (index+1) + "-" + nsize+ " to " + index);System.arraycopy(ohashes, index + 1, mHashes, index, nsize - index);System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,(nsize - index) << 1);}} else {if (index < nsize) {// 如果 index 在 size 内,则将数据往前移一位if (DEBUG) Log.d(TAG, "remove: move " + (index+1) + "-" + nsize+ " to " + index);System.arraycopy(mHashes, index + 1, mHashes, index, nsize - index);System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,(nsize - index) << 1);}// 然后将最后一位数据置 nullmArray[nsize << 1] = null;mArray[(nsize << 1) + 1] = null;}}if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}mSize = nsize;return (V)old;
}ArrayMap.put()总结
- (1) mHashs 数组以升序的方式保存了所有的 hash code。
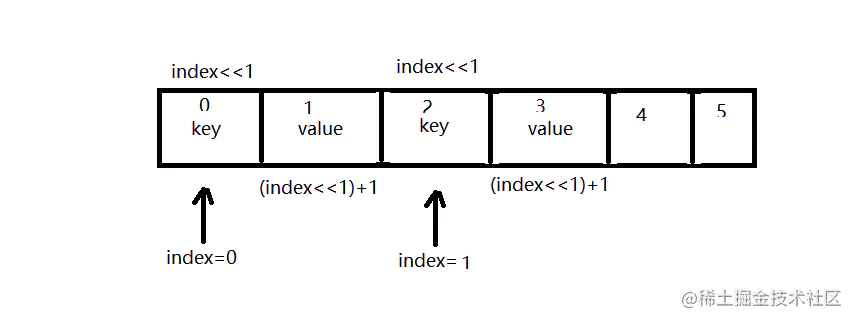
- (2) 通过 hash code 在 mHashs 数组里的 index 值来确定 key 以及 value 在 mArrays 数组中的存储位置。一般来说分别就是 index << 1 以及 index << 1 + 1。再简单点说就是 index * 2 以及 index * 2 + 1。
- (3) hashCode 必然可能存在冲突,这里是怎么解决的呢?这个是由上面的第 3 步和第 7 步所决定。第 3 步是得出应该插入的 index 的位置,而第 7 步则是如果 index < osize ,则说明原来 mArrays 中必然已经存在相同 hashCode 的值了,那么就把数据全部往后移一位,从而在 mHashs 中插入多个相同的 hash code 并且一定是连接在一起的,而在 mArrays 中插入新的 key 和 value,最终得以解决 hash 冲突。
ArrayMap.indexOf()总结 - (1) 如果当前为空表,则直接返回 ~0,注意不是 0 ,而是最大的负数。
- (2) 在 mHashs 数组中进行二分查找,找到 hash 的 index。
- (3) 如果 index < 0,说明没有找到。
- (4) 如果 index >= 0,且在 mArray 中对应的 index<<1 处的 key 与要找的 key 又相同,则认为是同一个 key,说明找到了。
- (5) 如果 key 不相同,说明只是 hash code 相同,那么分别向后和向前进行搜索,如果找到了就返回。如果没找到,那么对 end 取反就是当前需要插入的 index 位置。

ArrayMap.removeAt()总结
一般情况下删除一个数据,只需要将 index 后面的数据都往 index 方向移一位,然后删除末位数即可。而如果当前的数组中的条件达到 mHashs 的长度大于 BASE_SIZE2 且实际大小又小于其长度的 1/3,那么就要进行数据的压缩。而压缩后的空间至少也是 BASE_SIZE2 的大小。
对比总结
SparseArray相对于HashMap
- 使用int数组作为map的key容器,Object数组作为value容器,使用索引对应的形式组成key-value这使得SparseArray可以不按照像数组索引那样的顺序来添加元素。可看成增强型的数组或者ArrayList。
- 使用二分查找法查找key在数组中的位置,然后根据这个数组位置得到对应value数组中的value值。
- 相对于HashMap,合理使用SparseArray可以节省大量创建Entry节点时产生的内存,不需要拆箱装箱操作,提高性能,但是因为基于数组,插入和删除操作需要挪动数组,已经使用了时间复杂度为O(logN)的二分查找算法,相对HashMap来说,非常消耗性能,当数据有几百条时,性能会比HashMap低近50%,因此SparseArray适用于数据量很小的场景。
ArrayMap和HashMap的区别?
- ArrayMap的存在是为了解决HashMap占用内存大的问题,它内部使用了一个int数组用来存储元素的hashcode,使用了一个Object数组用来存储元素,两者根据索引对应形成key-value结构,这样就不用像HashMap那样需要额外的创建Entry对象来存储,减少了内存占用。但是在数据量比较大时,ArrayMap的性能就会远低于HashMap,因为 ArrayMap基于二分查找算法来查找元素的,并且数组的插入操作如果不是末尾的话需要挪动数组元素,效率较低。
- 而HashMap内部基于数组+单向链表+红黑树实现,也是key-value结构, 正如刚才提到的,HashMap每put一个元素都需要创建一个Entry来存放元素,导致它的内存占用会比较大,但是在大数据量的时候,因为HashMap中当出现冲突时,冲突的数据量大于8,就会从单向链表转换成红黑树,而红黑树的插入、删除、查找的时间复杂度为O(logn),相对于ArrayMap的数组而言在插入和删除操作上要快不少,所以数据量上百的情况下,使用HashMap会有更高的效率。
如何解决冲突问题? - 在ArrayMap中,假设存在冲突的话,并不会像HashMap那样使用单向链表或红黑树来保留这些冲突的元素,而是全部key、value都存储到一个数组当中,然后查找的话通过二分查找进行,这也就是当数据量大时不宜用ArrayMap的原因了。
性能对比统计参考:https://bbs.huaweicloud.com/blogs/detail/249692
参考:https://juejin.cn/post/6844903762470060045