1.ArrayMap是什么
一个通用的key-value映射数据结构
相比HashMap会占用更少的内存空间
android.util和android.support.v4.util都包含对应的ArrayMap类
2.为什么要使用ArrayMap
ArrayMap是一个普通的键值映射的数据结构,这种数据结构比传统的HashMap有着更好的内存管理效率。传统HashMap非常的好用,但是它对内存的占用非常的大。为了解决HashMap更占内存的弊端,Android提供了内存效率更高的ArrayMap。
3.ArrayMap的实现原理
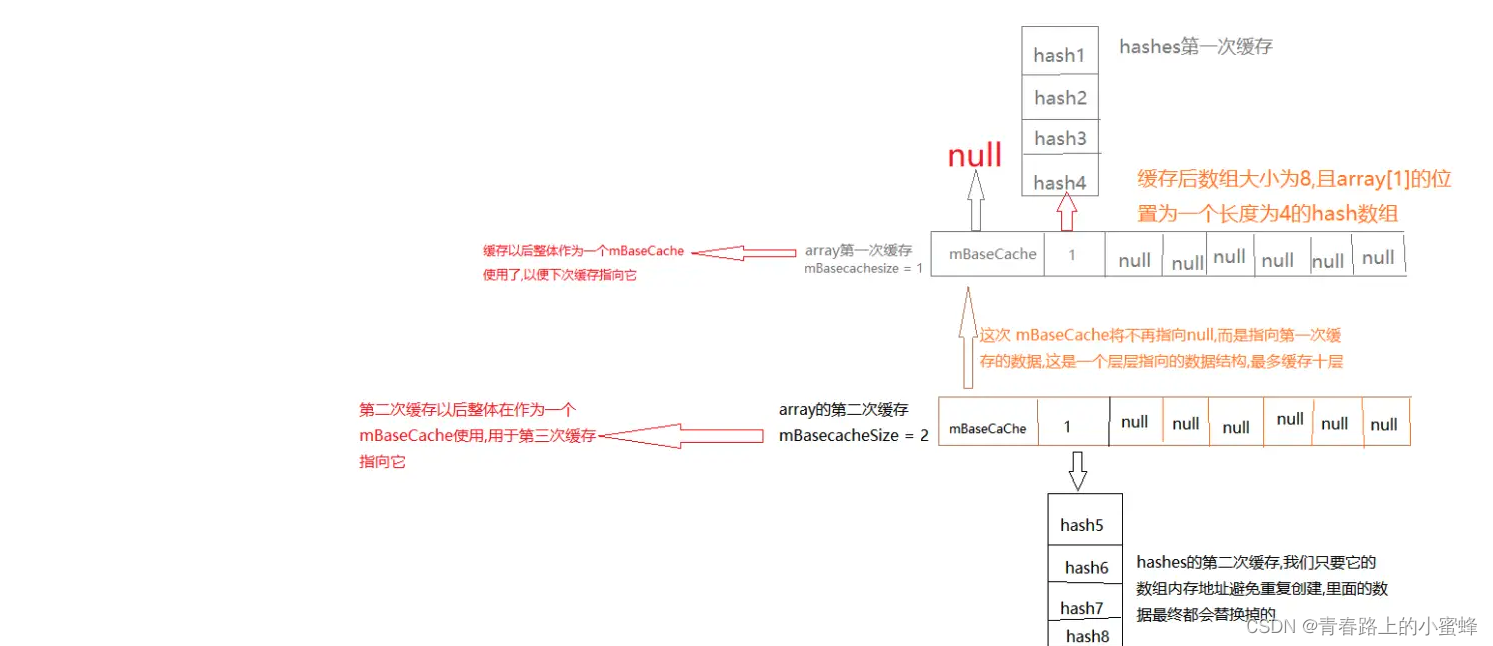
它内部使用两个数组进行工作,其中一个数组记录key hash过后的顺序列表,另外一个数组按key的顺序记录Key-Value值,如下图所示:
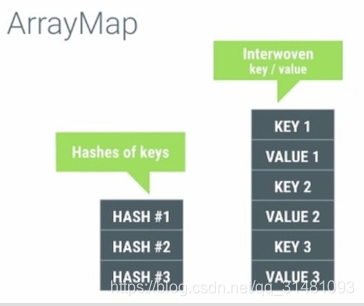
这样做的好处就是它避免了为每个加入到map的实体构造额外的对象。在ArrayMap大小增长的时候,我们也只需要复制两个数组的实体,而不需要重新构建一个hash map。
我们需要注意的是这种数据结构不适合包含大量数据项的数据结构,因为它内部使用的是数组,对数组进行插入和删除操作效率比较低。
4.ArrayMap源码解析
类结构
public final class ArrayMap<K, V> implements Map<K, V> {private static final boolean CONCURRENT_MODIFICATION_EXCEPTIONS = true;private static final int BASE_SIZE = 4; // 容量增量的最小值private static final int CACHE_SIZE = 10; // 缓存数组的上限static Object[] mBaseCache; //用于缓存大小为4的ArrayMapstatic int mBaseCacheSize;static Object[] mTwiceBaseCache; //用于缓存大小为8的ArrayMapstatic int mTwiceBaseCacheSize;final boolean mIdentityHashCode;int[] mHashes; //存储出的是每个key的hash值,并且在这些key的hash值在数组当中是从小到大排序的。
Object[] mArray; //由key-value对所组成的数组,长度是mHashs的两倍,每两个元素分别是key和value,这两元素对应mHashs中的hash值。int mSize; //成员变量的个数
}mHashes,int 数组,用来保存 key 的 hashCode。
mArray,Object 数组,用来保存 key-value,长度时 mHashes 的 2 倍。
mBaseCache,Object 数组,用来缓存大小为 4 的 ArrayMap,mBaseCacheSize 记录当前已缓存的数量,超过 10 个即不再缓存。
mTwiceBaseCacheSize,Object 数组,用来缓存大小为 8 的 ArrayMap,mTwiceBaseCacheSize 记录当前已缓存的数量,超过 10 个则不再缓存。
ArrayMap 的内部数据结构可用下图来表示:
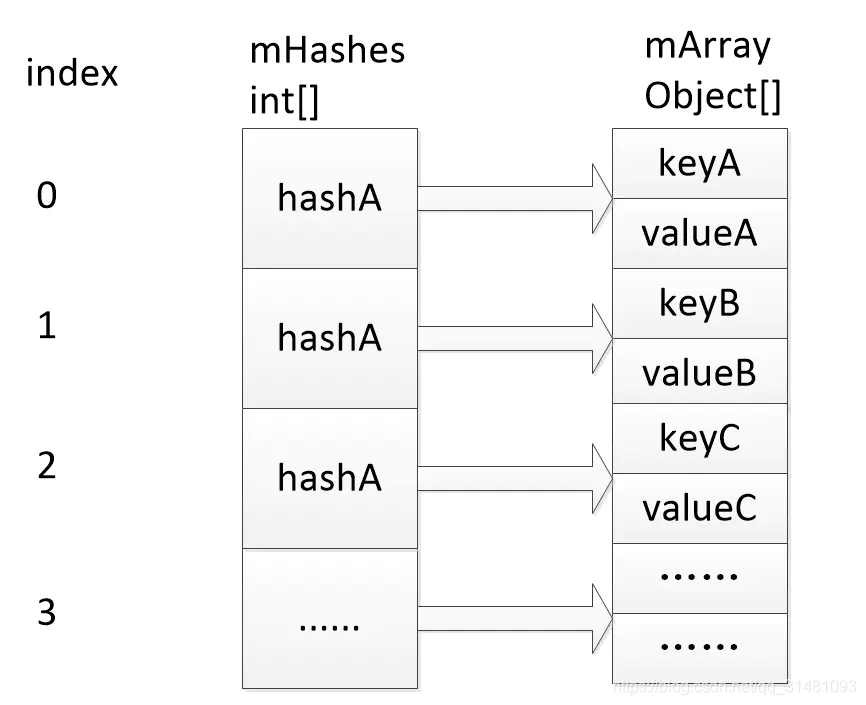
如上图所示,在ArrayMap内部有两个比较重要的数组,一个是mHashes,另一个是mArray。
1.mHashes用来存放key的hashcode值
2.mArray用来存储key与value的值,它是一个Object数组。
查找数据
查找数据是容器常用的操作,在Map中,通常是根据key找到对应的value的值。
ArrayMap中的查找分为如下两步:
1.key的hashcode找到在mHashes数组中的索引值;
2.根据上一步的索引值去查找key所对应的value值。
其中占据时间复杂度最多的属于第一步:确定key的hashCode在mHahses中的索引值。
而这一步对mHashes查找使用的是二分查找,即Binary Search。所以ArrayMap的查询时间复杂度为 O(log n)。
确定key的hashcode在mHashes中的索引的代码的逻辑:
int indexOf(Object key, int hash) {final int N = mSize;// 使用二分查找算法搜索元素位置int index = binarySearchHashes(mHashes, N, hash);// 1. 不存在相关该hash if (index < 0) {return index;}// 2. 存在该hash,且对应位置上有对应keyif (key.equals(mArray[index<<1])) {return index;} // 3. 存在该hash,但是对应位置上无对应key, 也就是说冲突了// 那么先搜索后半部分,之所以分成两半来查找是为了缩小查询范围,提升搜索速度// 这实际实在赌博,赌目标值在数组后半段 ,最终能否提升速度就看是不是在数组后半段了int end;for (end = index + 1; end < N && mHashes[end] == hash; end++) {if (key.equals(mArray[end << 1])) return end;}// 再搜索前半部分for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) {if (key.equals(mArray[i << 1])) return i;} // 对应key实在没找到,说明确实是冲突了,那么返回个mHashes数组大小的取反值(负数)return ~end;}既然对mHashes进行二分查找,则mHashes必须为有序数组。
put 方法
put 方法的逻辑主要分为以下几个部分:
1.key 为 null 时的插入
2.key 不为 null 时的插入
3.如有需要进行扩容处理
源码如下:
public V put(K key, V value) {//当前数组的长度final int osize = mSize;final int hash;int index;//判断key是否为空 为空的话hash赋值为0,寻找为空的下标。if (key == null) {hash = 0;index = indexOfNull();} else {//不为空的话选择hashcode的计算方式,一般为false 也就是key.hashCode就是自己的hash方法hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode();//寻找hash在数组的下标index = indexOf(key, hash);}//判断下标是否大于0,如果大于表示这个值在已经存在过了。然后把当前下标位置替换新的值。if (index >= 0) {index = (index << 1) + 1;final V old = (V) mArray[index];mArray[index] = value; //新的value值进行替换return old;}index = ~index;//判断当前长度是否大于保存hash值数组的长度,进行数组扩容if (osize >= mHashes.length) {//BaseSize是4//如果当前长度大于8 则增长2倍//否则容量大于4,则扩容到8.//否则扩容到4final int n = osize >= (BASE_SIZE * 2) ? (osize + (osize >> 1)): (osize >= BASE_SIZE ? (BASE_SIZE * 2) : BASE_SIZE);if (DEBUG) Log.d(TAG, "put: grow from " + mHashes.length + " to " + n);final int[] ohashes = mHashes; //临时hash数组final Object[] oarray = mArray;//临时保存value的数组//扩容到算出大小allocArrays(n);//判断两个长度是否一样,否则抛出concurrentModification异常if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}//把临时数组中的值移动到新数组if (mHashes.length > 0) {if (DEBUG) Log.d(TAG, "put: copy 0-" + osize + " to 0");System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length);System.arraycopy(oarray, 0, mArray, 0, oarray.length);}//释放数组空间,里面的方法看到把数组元素致空/* array[0] = mBaseCache;array[1] = hashes;for (int i = (size << 1) - 1; i >= 2; i--) {array[i] = null;}*/freeArrays(ohashes, oarray, osize);}//当前位置下标在当前数组中则添加到数组中,其他值往后移动if (index < osize) {if (DEBUG) Log.d(TAG, "put: move " + index + "-" + (osize - index)+ " to " + (index + 1));System.arraycopy(mHashes, index, mHashes, index + 1, osize - index);System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1);}if (CONCURRENT_MODIFICATION_EXCEPTIONS) {if (osize != mSize || index >= mHashes.length) {throw new ConcurrentModificationException();}}//按照存入顺序添加hash 数组mHashes[index] = hash;//在value数组 index*2下标存入key值 index*2+1的位置存入value值mArray[index << 1] = key;mArray[(index << 1) + 1] = value;mSize++;return null;}太长了没有截图全,我把代码贴在上面,主要是put值的操作。主要是:
1.判断是否传入的key值为空,hash值为0,寻找为空的下标。不为空的话找到在hash数组中hash的下标。
2.判断下标是否在数组中是否存在过,替换新的值。
3.判断长度是否需要进行扩容, 当前长度大于8则增长2倍,大于4则扩容到8,小于4则扩容到4。创建临时变量,进行数组拷贝
进行扩容。
4.释放数组。
append 方法
append 方法的过程与 put() 很相似,append 的差异在于该方法不会去做扩容处理,是一个轻量级的操作,适合于提前知道会插入队尾的情况下,这样会比 put() 方法性能更好。put() 方法上来先做 binarySearchHashes 二分查找,时间复杂度为 O(logN),而 append() 的时间复杂读为 O(1),append 方法如下:
public void append(K key, V value) {int index = mSize;final int hash = key == null ? 0: (mIdentityHashCode ? System.identityHashCode(key) : key.hashCode());//当 index 大于等于 mHashes.length 时抛出异常if (index >= mHashes.length) {throw new IllegalStateException("Array is full");}//当数据插入到数组的中间,会调用put来完成if (index > 0 && mHashes[index-1] > hash) {put(key, value); return;}//数据直接添加到队尾mSize = index+1;mHashes[index] = hash;index <<= 1;mArray[index] = key;mArray[index+1] = value;}remove() 方法
调用 remove() 方法可以删除 ArrayMap 的一项数据,主要逻辑如下:
1.如果当前 ArrayMap 只有一项数据,则会置空 mHashes、mArray,将 mSize 置为 0 。
2.如果当前 ArrayMap 容量过大(大于 8)并且持有数据量过小(不足 1/3)则降低 ArrayMap 的容量,减少内存占用。
3.上述情况都不满足时,则从 mHashes 删除相应的值,将 mArray 中对应的索引置为 null。
源码如下:
public V remove(Object key) {final int index = indexOfKey(key); // 二分法查找key的indexif (index >= 0) {return removeAt(index); // 移除相应位置的数据}return null;}public V removeAt(int index) {final Object old = mArray[(index << 1) + 1];final int osize = mSize;final int nsize;if (osize <= 1) { // 如果被移除的是ArrayMap的最后一个元素,则释放该内存freeArrays(mHashes, mArray, osize);mHashes = EmptyArray.INT;mArray = EmptyArray.OBJECT;nsize = 0;} else {nsize = osize - 1;// 容量过大时收紧容量 if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {final int n = osize > (BASE_SIZE*2) ? (osize + (osize>>1)) : (BASE_SIZE*2);final int[] ohashes = mHashes;final Object[] oarray = mArray;allocArrays(n);// 并发时抛出异常if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}if (index > 0) {System.arraycopy(ohashes, 0, mHashes, 0, index);System.arraycopy(oarray, 0, mArray, 0, index << 1);}if (index < nsize) {System.arraycopy(ohashes, index + 1, mHashes, index, nsize - index);System.arraycopy(oarray, (index + 1) << 1, mArray, index << 1,(nsize - index) << 1);}} else {//当被移除的元素不是数组最末尾的元素时,则需要将后面的数组往前移动if (index < nsize) { System.arraycopy(mHashes, index + 1, mHashes, index, nsize - index);System.arraycopy(mArray, (index + 1) << 1, mArray, index << 1,(nsize - index) << 1);}//再将最后一个位置设置为nullmArray[nsize << 1] = null;mArray[(nsize << 1) + 1] = null;}}if (CONCURRENT_MODIFICATION_EXCEPTIONS && osize != mSize) {throw new ConcurrentModificationException();}mSize = nsize; //大小减1return (V)old;}clear() 方法与 earse() 方法
clear() 方法会通过 freeArrays() 方法来回收内存,而 earse()则会清空数组的数据,不会回收内存,它们的源码如下:
/*** Make the array map empty. All storage is released.*/@Overridepublic void clear() {if (mSize > 0) {final int[] ohashes = mHashes;final Object[] oarray = mArray;final int osize = mSize;mHashes = EmptyArray.INT;mArray = EmptyArray.OBJECT;mSize = 0;freeArrays(ohashes, oarray, osize);}if (CONCURRENT_MODIFICATION_EXCEPTIONS && mSize > 0) {throw new ConcurrentModificationException();}}/*** @hide* Like {@link #clear}, but doesn't reduce the capacity of the ArrayMap.*/public void erase() {if (mSize > 0) {final int N = mSize<<1;final Object[] array = mArray;for (int i=0; i<N; i++) {array[i] = null;}mSize = 0;}}缓存机制
如上所述,put() 方法增加数据,会扩大容量;remove() 方法会删除数据,减少容量。这会频繁低出现多个 4 和 8 的 int 数组和 Object 数组,所以为了减少内存回收的压力,ArrayMap 引入了缓存机制,主要涉及到了以下两个方法:
freeArrays
freeArrays 在释放内存时,如果释放的 array 大小等于 4 或者 8 时,且相应的缓冲池未达上限时(10),则会把 array 加入到缓冲池中,源码如下:
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {if (hashes.length == (BASE_SIZE*2)) { //当释放的是大小为8的对象synchronized (ArrayMap.class) {// 当大小为8的缓存池的数量小于10个,则将其放入缓存池if (mTwiceBaseCacheSize < CACHE_SIZE) { array[0] = mTwiceBaseCache; //array[0]指向原来的缓存池array[1] = hashes;for (int i=(size<<1)-1; i>=2; i--) {array[i] = null; //清空其他数据}mTwiceBaseCache = array; //mTwiceBaseCache指向新加入缓存池的arraymTwiceBaseCacheSize++; }}} else if (hashes.length == BASE_SIZE) { //当释放的是大小为4的对象,原理同上synchronized (ArrayMap.class) {if (mBaseCacheSize < CACHE_SIZE) {array[0] = mBaseCache;array[1] = hashes;for (int i=(size<<1)-1; i>=2; i--) {array[i] = null;}mBaseCache = array;mBaseCacheSize++;}}}}allocArrays
分配内存时,如果所需要分配的大小等于 4 或者 8,且对应的缓冲池不为空,则会从相应的缓存池取出 mHashes 和 mArray。源码如下:
private void allocArrays(final int size) {if (size == (BASE_SIZE*2)) { //当分配大小为8的对象,先查看缓存池synchronized (ArrayMap.class) {if (mTwiceBaseCache != null) { // 当缓存池不为空时final Object[] array = mTwiceBaseCache; mArray = array; //从缓存池中取出mArraymTwiceBaseCache = (Object[])array[0]; //将缓存池指向上一条缓存地址mHashes = (int[])array[1]; //从缓存中mHashesarray[0] = array[1] = null;mTwiceBaseCacheSize--; //缓存池大小减1return;}}} else if (size == BASE_SIZE) { //当分配大小为4的对象,原理同上synchronized (ArrayMap.class) {if (mBaseCache != null) {final Object[] array = mBaseCache;mArray = array;mBaseCache = (Object[])array[0];mHashes = (int[])array[1];array[0] = array[1] = null;mBaseCacheSize--;return;}}}// 分配大小除了4和8之外的情况,则直接创建新的数组mHashes = new int[size];mArray = new Object[size<<1];}很多场景可能起初都是数据很少,为了减少频繁地创建和回收Map对象,ArrayMap采用了两个大小为10的缓存队列来分别保存大小为4和8的Map对象。为了节省内存有更加保守的内存扩张以及内存收缩策略。
freeArrays()触发时机:
当执行removeAt()移除最后一个元素的情况
当执行clear()清理的情况
当执行ensureCapacity()在当前容量小于预期容量的情况下, 先执行allocArrays,再执行freeArrays
当执行put()在容量满的情况下, 先执行allocArrays, 再执行freeArrays
allocArrays触发时机:
当执行ArrayMap的构造函数的情况
当执行removeAt()在满足容量收紧机制的情况
当执行ensureCapacity()在当前容量小于预期容量的情况下, 先执行allocArrays,再执行freeArrays
当执行put()在容量满的情况下, 先执行allocArrays, 再执行freeArrays
ArrayMap中解决Hash冲突的方式是追加的方式,比如两个key的hash(int)值一样,那就把数据全部后移一位,通过追加的方式解决Hash冲突。
ArrayMap的扩容机制
容量扩张
当mSize大于或等于mHashes数组长度时则扩容,完成扩容后需要将老的数组拷贝到新分配的数组,并释放老的内存。
当map个数满足条件 osize<4时,则扩容后的大小为4;
当map个数满足条件 4<= osize < 8时,则扩容后的大小为8;
当map个数满足条件 osize>=8时,则扩容后的大小为原来的1.5倍;
源码如下:
public V put(K key, V value) {...final int osize = mSize;if (osize >= mHashes.length) { //当mSize大于或等于mHashes数组长度时需要扩容final int n = osize >= (BASE_SIZE*2) ? (osize+(osize>>1)): (osize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE);allocArrays(n); //分配更大的内存【小节2.2.2】}...}容量收紧
当数组内存的大小大于8,且已存储数据的个数mSize小于数组空间大小的1/3的情况下,需要收紧数据的内容容量,分配新的数组,老的内存靠虚拟机自动回收。
如果mSize<=8,则设置新大小为8;
如果mSize> 8,则设置新大小为mSize的1.5倍。
也就是说在数据较大的情况下,当内存使用量不足1/3的情况下,内存数组会收紧50%。
源码如下:
public V removeAt(int index) {final int osize = mSize;final int nsize;if (osize > 1) { //当mSize大于1的情况,需要根据情况来决定是否要收紧nsize = osize - 1;if (mHashes.length > (BASE_SIZE*2) && mSize < mHashes.length/3) {final int n = osize > (BASE_SIZE*2) ? (osize + (osize>>1)) : (BASE_SIZE*2);allocArrays(n); // 分配更小的内存} }}5.ArrayMap 综述
特点
1.实现了Map接口,并使用int[]数来存储key的hash值,数组的索引用作index,而使用Object[]数组来存储key<->value ,这还是比较新颖的 。
2.使用二分查找查找hash值在key数组中的位置,然后根据这个位置得到value数组中对应位置的元素。
3.和SparseArray类似,当数据有几百条时,性能会比HashMap低50%,因此ArrayMap适用于数据量很小的场景
ArrayMap和HashMap的区别?
1.ArrayMap的存在是为了解决HashMap占用内存大的问题,它内部使用了一个int数组用来存储元素的hashcode,使用了一个Object数组用来存储元素,两者根据索引对应形成key-value结构,这样就不用像HashMap那样需要额外的创建Entry对象来存储,减少了内存占用。但是在数据量比较大时,ArrayMap的性能就会远低于HashMap,因为 ArrayMap基于二分查找算法来查找元素的,并且数组的插入操作如果不是末尾的话需要挪动数组元素,效率较低。
2.而HashMap内部基于数组+单向链表+红黑树实现,也是key-value结构, 正如刚才提到的,HashMap每put一个元素都需要创建一个Entry来存放元素,导致它的内存占用会比较大,但是在大数据量的时候,因为HashMap中当出现冲突时,冲突的数据量大于8,就会从单向链表转换成红黑树,而红黑树的插入、删除、查找的时间复杂度为O(logn),相对于ArrayMap的数组而言在插入和删除操作上要快不少,所以数据量上百的情况下,使用HashMap会有更高的效率。
如何解决冲突问题?
在ArrayMap中,假设存在冲突的话,并不会像HashMap那样使用单向链表或红黑树来保留这些冲突的元素,而是全部key、value都存储到一个数组当中,然后查找的话通过二分查找进行,这也就是当数据量大时不宜用ArrayMap的原因了。
具备这些能力,能够让自己形成一个新的高度,让自己走上一个新的台阶,感谢各位关注我。