首先我们来介绍一下HashMap,了解它的优缺点,然后再对比一下其他的数据结构以及为什么要替代它。
HashMap
HashMap是由数组+单向链表的方式组成的,初始大小是16(2的4次方),首次put的时候,才会真正初始化。
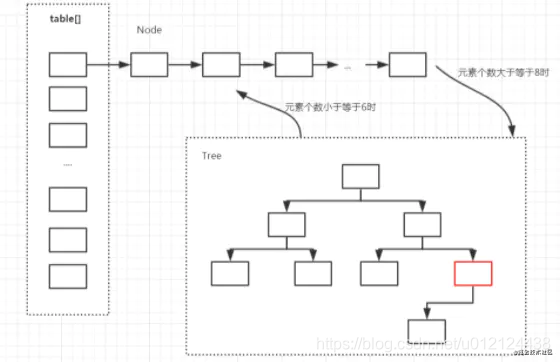
链表长度大于8时转化成红黑树,小于6时又转化成链表。
1.为什么要引入红黑树?
JDK 1.8以前是数组+链表,还未引入红黑树,这就导致了链表过长时查找的时间复杂度是O(n)
红黑树是一种自平衡的二叉查找树,不是一种绝对平衡的二叉树,它放弃了追求绝对平衡,追求大致平衡,在与平衡二叉树的时间复杂度相差不大的情况下,保证每次插入最多只需要三次旋转就能达到平衡,实现起来也更为简单。
2.为什么初始值大小为2的N次方,以后每次扩容后的结果也是2的N次方?
1.如果往hashmap中存放数据,我们首先得保证它能够尽量均匀分布,为了保证能够均匀分布,我们可能会想到用取模的方式去实现,如果用传统的‘%’方式来实现效率不高,当大小(length)总为2的n次方时,h&(length-1)运算等价于对length取模,也就是h%lenth,但是&比%具有更高的效率,同时也减少了hash碰撞。
2.和h&(length-1)相关,当容量大小(n)为2的n次方时,n**-1 的二进制的后几位全是1,在h为随机数的情况下,与(n-1)进行与操作时,会分布的更均匀**,想一想,如果n-1的二进制数是1110,当尾数为0时,与出来的值尾数永远为0,那么0001,1001,1101等尾数为1的位置就永远不可能被entry占用,就造成了空间浪费。
在hashmap源码中,put方法会调用indexFor方法,这个方法主要是根据key的hash值找到这个entry在table中的位置,最后 return 的是 h&(length-1)
3.HashMap和其他数据结构的关联
3.1与Hashtable的关系
Hashtable是线程安全的,比如put,get等很多使用了synchronized修饰,和ConcurrentHashMap相比,在Hashtable的大小增加到一定的时候,效率会急剧下降,因为迭代时需要被锁定很长的时间**(而ConcurrentHashMap引入了分割,仅仅需要锁定map的某个部分)**所以其实效率并不高
Hashtable的put方法
public synchronized V put(K key, V value) {// Make sure the value is not nullif (value == null) {throw new NullPointerException();}// Makes sure the key is not already in the hashtable.HashtableEntry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;@SuppressWarnings("unchecked")HashtableEntry<K,V> entry = (HashtableEntry<K,V>)tab[index];for(; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value;return old;}}addEntry(hash, key, value, index);return null;
}里面的index是用%的方式进行取下标,效率不行
3.2 与HashSet的关系
我们先来看HashSet的add方法
public boolean add(E e) {return map.put(e, PRESENT)==null;
**HashSet底层就是HashMap,**HashSet不允许放入重复元素,虽然说Set对于重复的元素不放入,倒不如直接说是底层的Map直接把原值替代了。HashSet没有提供get方法,原因同HashMap一样,Set内部是无序的,只能通过迭代的方式获取。

与LinkedHashMap的关系,LinkedHashMap是一个数组+双向链表与HashMap不同,可以保证元素的迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序(LRU原理)。
与LinkedHashSet的关系,LinkedHashSet是继承自HashSet,底层实现是LinkedHashMap。
TreeSet中存放的元素是有序的(不是插入时的顺序,是有按关键字大小排序的),且元素不能重复。
3.4 链表长度大于8一定会转化成红黑树吗?
就算链表长度超过8,进入了这个转化为红黑树的方法,还是要判断当前容量的大小是否小于64,如果小于这个值还是要进行扩容而不是转化为红黑树
HashMap并发的问题
HashMap不是线程安全的,在Java7 中,HashMap被多个线程操作可能造成形成环形链表,造成死循环。可以用ConcurrentHashMap来解决,Java7 中ConcurrentHashMap 是用分段锁的方式实现的,也就是二级哈希表。在Java8 中的实现方式是通过Unsafe类的CAS自旋赋值+synchronized同步+LockSupport阻塞等手段实现的高效并发,代码可读性稍差。最大的区别在于JDK8的锁粒度更细,理想情况下talbe数组元素的大小就是其支持并发的最大个数。
HashMap的缺点,扩容因子为0.75(数据论文表示0.6~0.75性能最好),同时默认每次扩容都是2倍进行扩容,有点浪费空间(如果只是超过了一个),其实是以空间换时间。
SparseArray
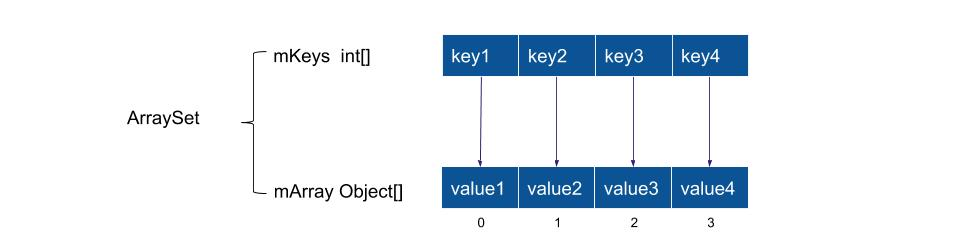
SparseArray中Key为int类型(避免了装箱和拆箱),Value是Object类型,Key和Value分别存放在一个数组内,Key数组int值是按顺序排列的,查找的时候采用的是二分查找,效率很高。而Value数组的位置和Key数组中的位置是一样的。
add的时候会进行位移,remove的时候不一定会进行位移,把某个值标记为delete,如果下次有符合的值直接放到该位置,就没有位移了。但是也有缺点,Key只能是int值。最后Android中还扩展了SparseLongArray。
ArrayMap
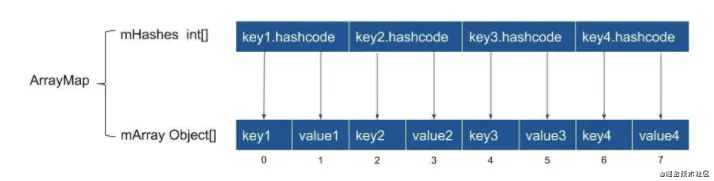
ArrayMap的Key和Value同HashMap一样都可以存放多种类型,ArrayMap对象的数据存储格式如下:
1.mHashes是一个记录所有key的hashcode值组成的数组,是从小到大的排序方式;采用二分查找法,从mHashes数组中查找值等于hash的key
2.mArray是一个记录着key-value键值对所组成的数组,是mHashes大小的2倍;
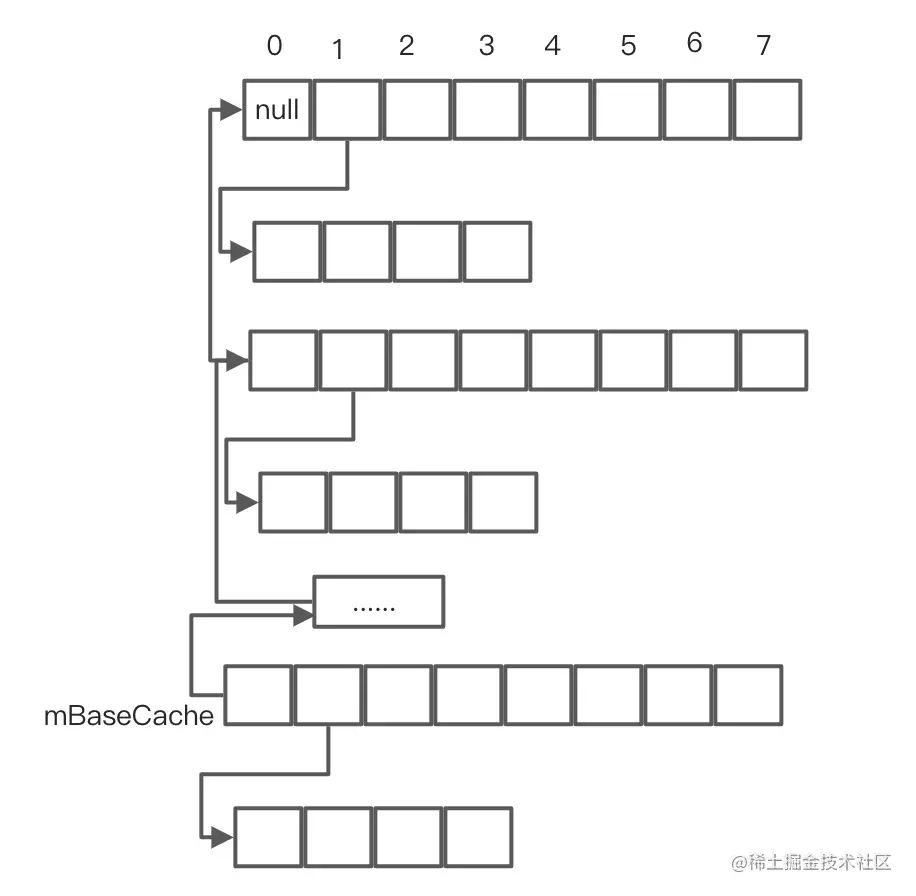
ArrayMap中有两个非常重要的静态成员变量mBaseCache和mTwiceBaseCacheSize,用于ArrayMap所在进程的全局缓存功能:
mBaseCache:用于缓存大小为4的ArrayMap,mBaseCacheSize记录着当前已缓存的数量,超过10个则不再缓存;
mTwiceBaseCacheSize:用于缓存大小为8的ArrayMap,mTwiceBaseCacheSize记录着当前已缓存的数量,超过10个则不再缓存。
很多场景可能起初都是数据很少,为了减少频繁地创建和回收Map对象,ArrayMap采用了两个大小为10的缓存队列来分别保存大小为4和8的Map对象。为了节省内存有更加保守的内存扩张以及内存收缩策略。
内存释放freeArrays()触发时机:
当执行removeAt()移除最后一个元素的情况
当执行clear()清理的情况
当执行ensureCapacity()在当前容量小于预期容量的情况下, 先执行allocArrays,再执行freeArrays
当执行put()在容量满的情况下, 先执行allocArrays, 再执行freeArrays
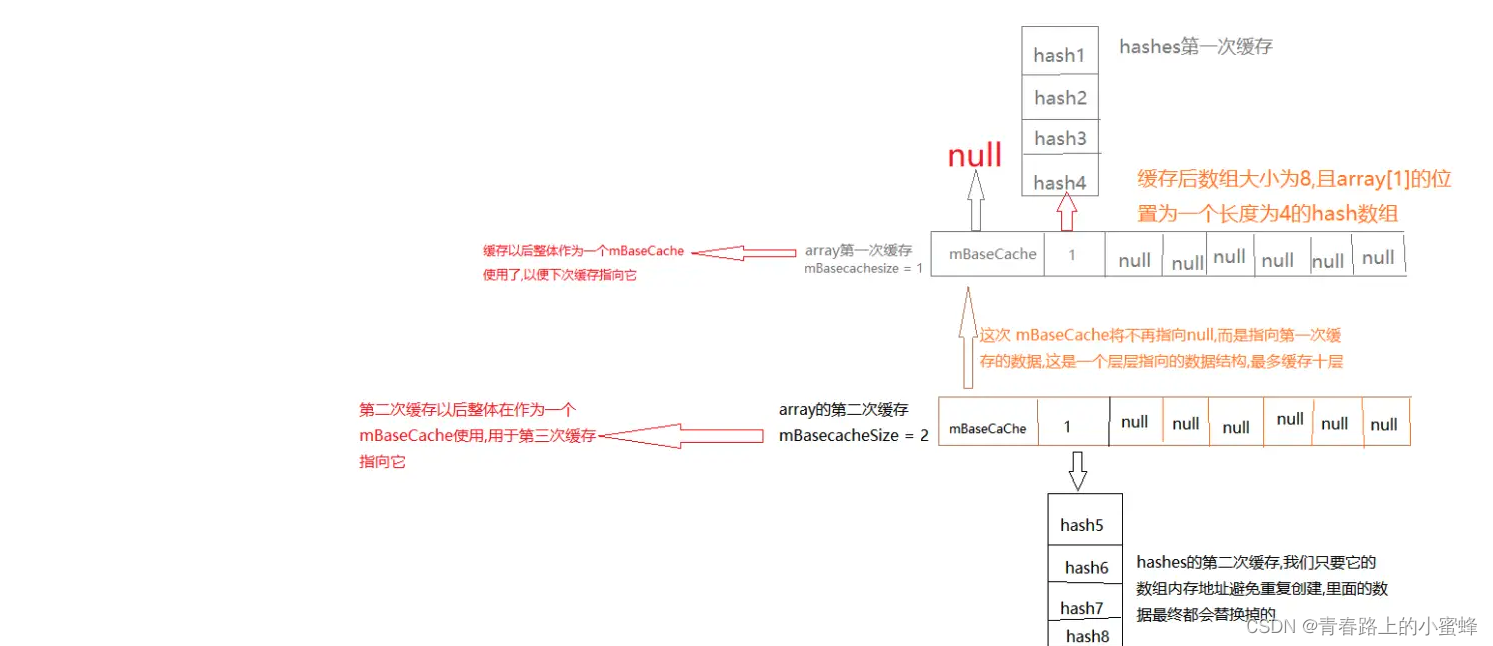
private static void freeArrays(final int[] hashes, final Object[] array, final int size) {if (hashes.length == (BASE_SIZE*2)) { //当释放的是大小为8的对象synchronized (ArrayMap.class) {// 当大小为8的缓存池的数量小于10个,则将其放入缓存池if (mTwiceBaseCacheSize < CACHE_SIZE) { array[0] = mTwiceBaseCache; //array[0]指向原来的缓存池array[1] = hashes;for (int i=(size<<1)-1; i>=2; i--) {array[i] = null; //清空其他数据}mTwiceBaseCache = array; //mTwiceBaseCache指向新加入缓存池的arraymTwiceBaseCacheSize++; }}} else if (hashes.length == BASE_SIZE) { //当释放的是大小为4的对象,原理同上synchronized (ArrayMap.class) {if (mBaseCacheSize < CACHE_SIZE) {array[0] = mBaseCache;array[1] = hashes;for (int i=(size<<1)-1; i>=2; i--) {array[i] = null;}mBaseCache = array;mBaseCacheSize++;}}}
}
最初mTwiceBaseCache和mBaseCache缓存池中都没有数据,在freeArrays释放内存时,如果同时满足释放的array大小等于4或者8,且相对应的缓冲池个数未达上限,则会把该arrya加入到缓存池中。**加入的方式是将数组array的第0个元素指向原有的缓存池,第1个元素指向hashes数组的地址,第2个元素以后的数据全部置为null。再把缓存池的头部指向最新的array的位置,并将该缓存池大小执行加1操作。**具体如下所示。
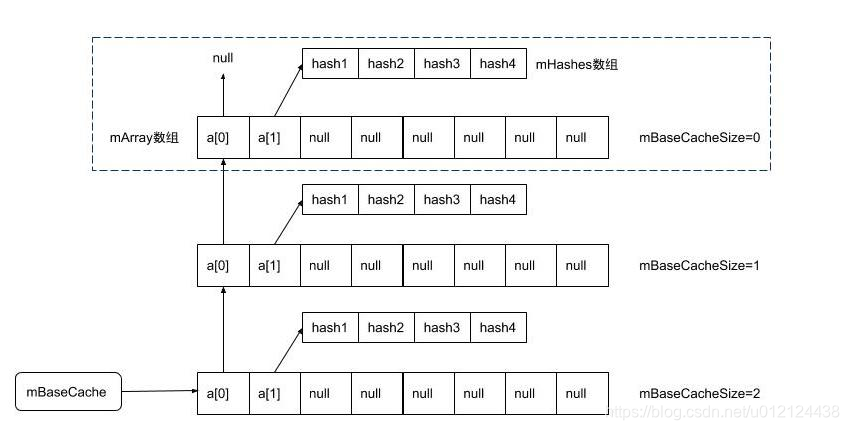
内存分配allocArrays触发时机:
当执行ArrayMap的构造函数的情况
当执行removeAt()在满足容量收紧机制的情况
当执行ensureCapacity()在当前容量小于预期容量的情况下, 先执行allocArrays,再执行freeArrays
当执行put()在容量满的情况下, 先执行allocArrays, 再执行freeArrays
当allocArrays分配内存时,如果所需要分配的大小等于4或者8,且相对应的缓冲池不为空,则会从相应缓存池中取出缓存的mArray和mHashes。从缓存池取出缓存的方式是将当前缓存池赋值给mArray,将缓存池指向上一条缓存地址,将缓存池的第1个元素赋值为mHashes,再把mArray的第0和第1个位置的数据置为null,并将该缓存池大小执行减1操作,具体如下所示。
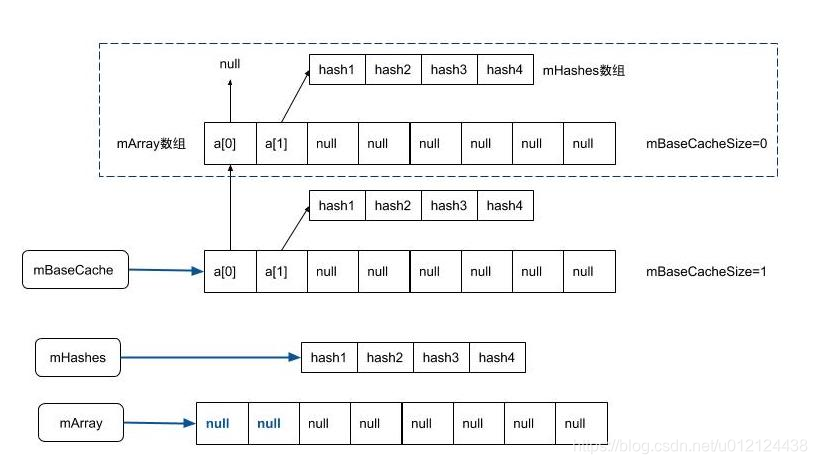
ArrayMap中解决Hash冲突的方式是追加的方式,比如两个key的hash(int)值一样,那就把数据全部后移一位,通过追加的方式解决Hash冲突。
ArrayMap的扩容
当mSize大于或等于mHashes数组长度时则扩容,完成扩容后需要将老的数组拷贝到新分配的数组,并释放老的内存。
当map个数满足条件 osize<4时,则扩容后的大小为4;
当map个数满足条件 4<= osize < 8时,则扩容后的大小为8;
当map个数满足条件 osize>=8时,则扩容后的大小为原来的1.5倍;
当数组内存的大小大于8,且已存储数据的个数mSize小于数组空间大小的1/3的情况下,需要收紧数据的内容容量,分配新的数组,老的内存靠虚拟机自动回收。
如果mSize<=8,则设置新大小为8;
如果mSize> 8,则设置新大小为mSize的1.5倍。
也就是说在数据较大的情况下,当内存使用量不足1/3的情况下,内存数组会收紧50%。