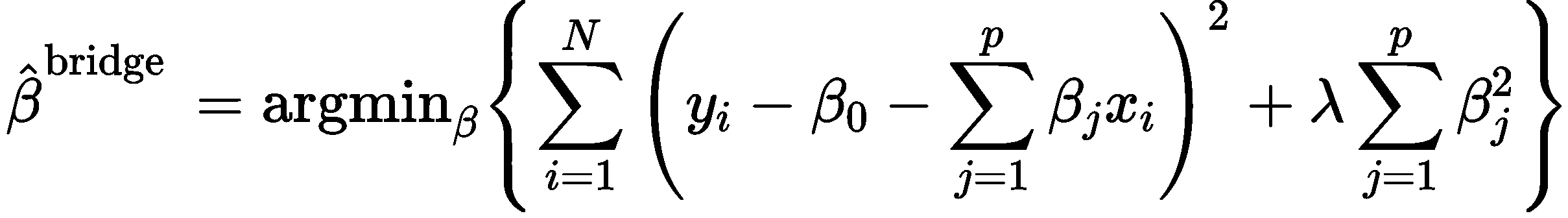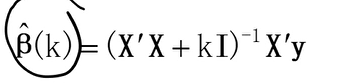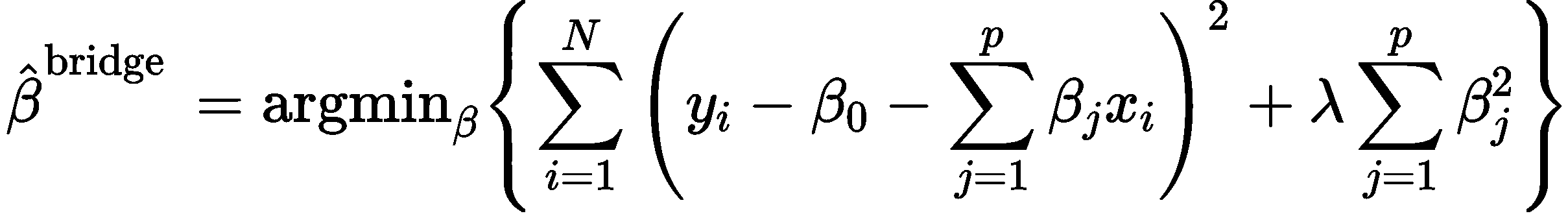在某些场景下,线性回归无法给出一个效果好的预测模型,那么就需要使用线性回归的升级版,去面对更复杂的应用场景,本文所记录的岭回归便是线性回归的一个升级版。
目录
强势样本对模型的影响
实例
岭回归定义
岭回归的实现
岭回归代码实例
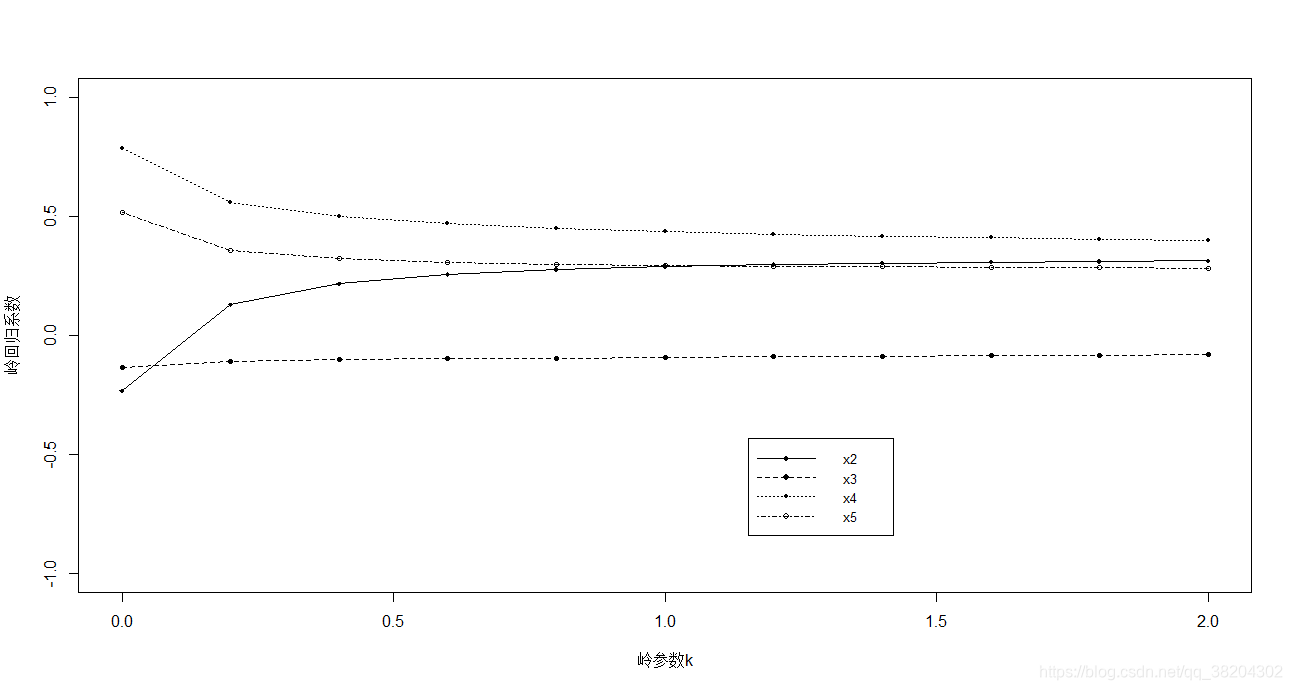
调整岭回归的参数
强势样本对模型的影响
如下图的例子,每个样本点是员工的工作年限对应的一个薪资水平,通过线性回归拟合了一条直线,可以看到有6个点是正常的样本,但最上面有一个强势样本。
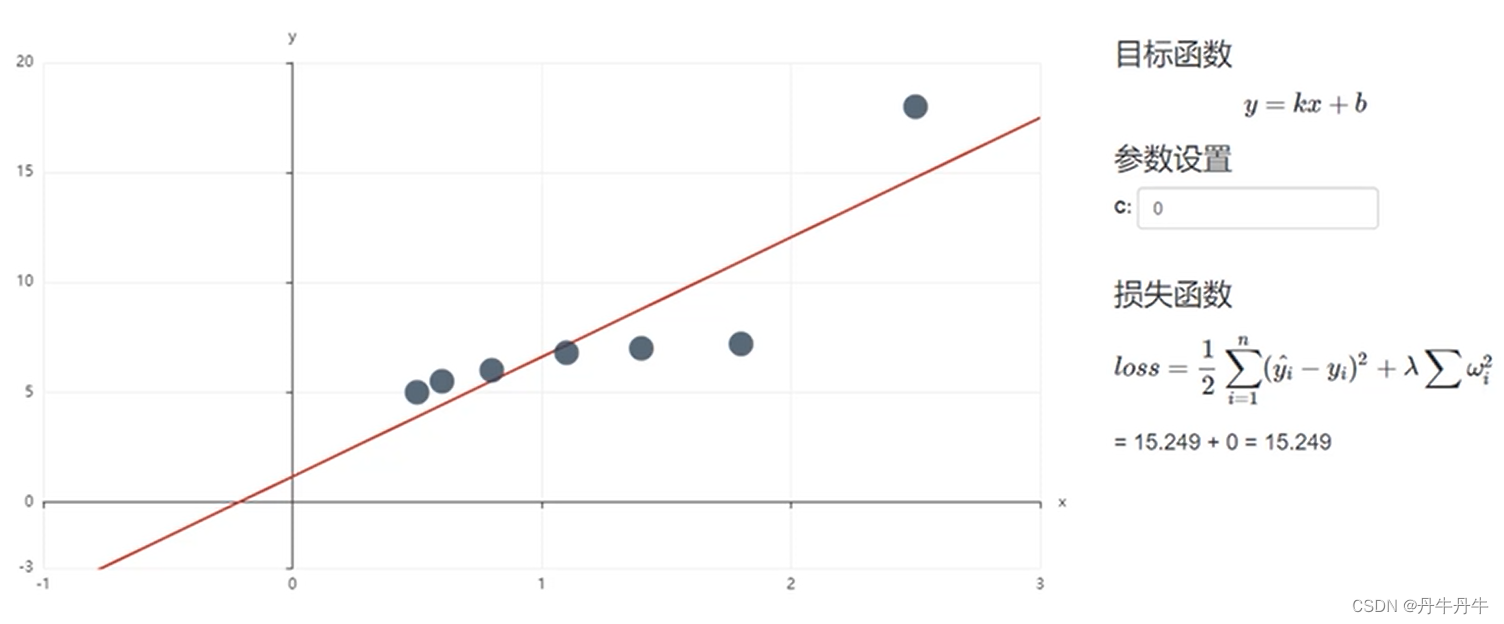
在实际看来这并非是不合理的情况,但在线性回归中,这个强势样本对模型的影响很大。如果我们只拟合前6个样本,会得到如图下面那条直线。因此可见强势样本产生的影响造成了这个模型发生了改变,那么很有可能在之后对大部分正常数据样本预测时,就会变得不准确。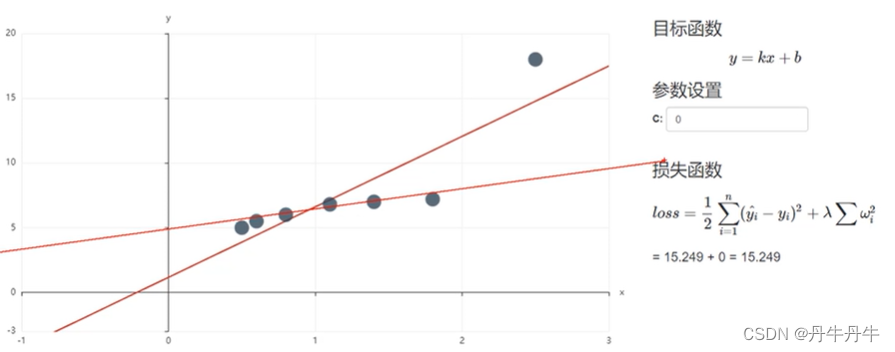
因此,这种情况下,不如抛弃强势样本,防止其对整个模型的预测效果产生较大的影响。
实例
仍以员工工作年限和对应薪资水平的数据集进行举例,但是前30个都是正常的样本数据,因此在最后32-34行,添加了3个强势样本,很明显与之前的数据有差别。
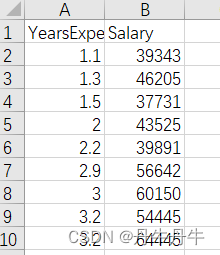
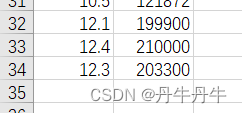
在python中对上述数据进行线性回归的模型拟合
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn.linear_model as lm # 加载数据集
data=pd.read_csv("Salary_Data2.csv")
x,y=data['YearsExperience'],data['Salary']
plt.grid(linestyle=':')
plt.scatter(x,y,s=60,color='dodgerblue',label='Samples')train_x,train_y=pd.DataFrame(x),y
# 基于sklearn提供ApI,训练线性回归模型
model=lm.LinearRegression()
model.fit(train_x,train_y)# 进行预测
pred_train_y=model.predict(train_x)#可视化
plt.grid(linestyle=':')
plt.scatter(x,y,s=60,color='dodgerblue',label='Samples')
plt.plot(x,pred_train_y,color='orangered',label='Regression Line')
plt.legend()可以看到图中训练的数据中3个强势样本,对比不带有强势样本的回归模型,其提高了模型的斜率,也因为受强势样本影响,导致模型对其他正常数据的拟合效果不是很好。

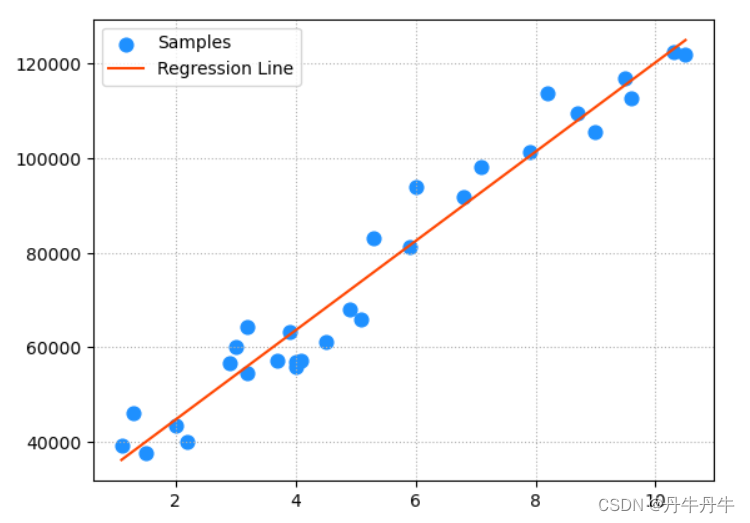
那么如何解决这个问题?就需要使用岭回归。
岭回归定义
普通线性回归模型使用基于梯度下降的最小二乘法,在最小化损失函数的前提下,寻找最优模型参数,于此过程中,包括少数异常样本在内的全部训练数据都会对最终模型参数造成程度相等的影响,异常值对模型所带来影响无法在训练过程中被识别出来。为此,岭回归在模型迭代过程所依据的损失函数中增加了正则项,以限制模型参数对异常样本的匹配程度,进而提高模型面对多数正常样本的拟合精度。
也就是说,有着强势样本的情况下,如果模型对样本数据拟合的太精确,那么反而会受到强势样本很大的影响,因此我们考虑稍微欠拟合一点,反而会使得强势样本的影响变小。那么岭回归的损失函数定义式为:
公式前半部分同原本的线性回归模型一样是样本误差,后半部分就是正则项,除了系数λ,后面是模型参数的平方再求和,参数λ是对后面的参数平方和进行一个范围的限制或规约,使用其控制这个数值是小还是大。整个损失函数就由原本的损失函数+这个正则项,如果正则项为0,那与原本的线性回归没区别。
所以loss函数要取最小值,还要与这个正则项有关,如果λ值调大一些,那么正则项对loss函数的影响就大一些,同理,λ值如果调小,那么正则项对总的loss函数影响就减小。并且正则项求导也是非常好求的。因此loss会考虑正则项,那么自然对模型的拟合度就会降低。
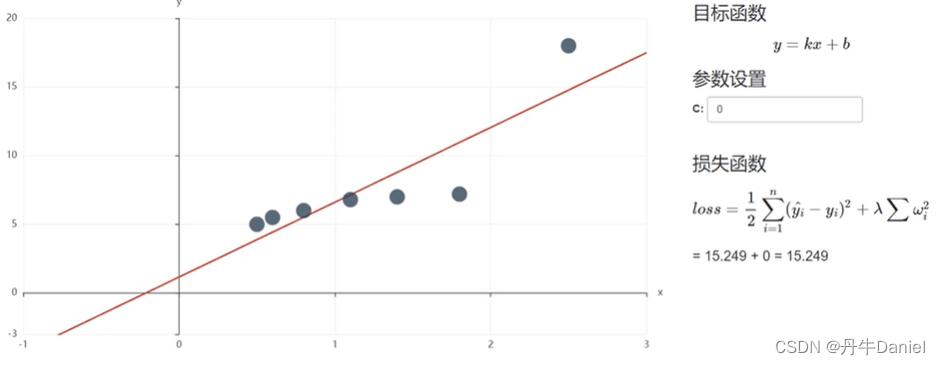
上图λ=0,相当于普通的线性回归模型,而下图将λ调整为0.5,所以模型loss就要考虑正则项,可以看到总样本误差为90.691,而其中原本的loss值为22.582,对比上图15.249确实有升高,也说明了对模型的拟合程度降低了。

虽然加上正则项,模型的总样本误差loss值增加了,但很明显从图中可以看到,对除了强势样本之外的普通样本的值反而拟合效果更好了。
那么如何选择合适的参数λ?自然还是要利用到上文中所学的模型的评估指标,那个参数对应的得分高就用哪个参数。
岭回归的实现
岭回归同样可以用python的sklearn库,下面展示相关的API调用。要说明的是lm.Ridge()中的参数:第一个是可以调整正则强度; 第二个fit_intercept默认情况下为true,因为如果不训练截距只训练斜率肯定会导致模型的拟合都不够; 第三个max_iter默认为-1,意思是迭代到不能再迭代为止。当然也可以选择1000,意为迭代1000次。
import sklearn.linear_model as lm# 创建模型
model=lm.Ridge(正则强度,fit_intercept=是否训练截距,max_iter=最大迭代次数)# 训练模型
# 输入为一个二维数组表示的样本矩阵
# 输出为每个样本最终的结果
model.fit(输入,输出)#预测输出
#输入array是一个二维数组,每一行是一个样本,每一列是一个特征。
result=model.predict(array)岭回归代码实例
以上面提到的薪资预测的例子来进行岭回归的一个示例,首先看一下如果正则项设为0,这其实就是普通的线性回归模型了
# 训练一个岭回归模型
model=lm.Ridge(0)
model.fit(train_x,train_y)# 进行预测
pred_train_y=model.predict(train_x)#可视化
plt.grid(linestyle=':')
plt.scatter(x,y,s=60,color='dodgerblue',label='Samples')
plt.plot(x,pred_train_y,color='orangered',label='Regression Line')
plt.legend()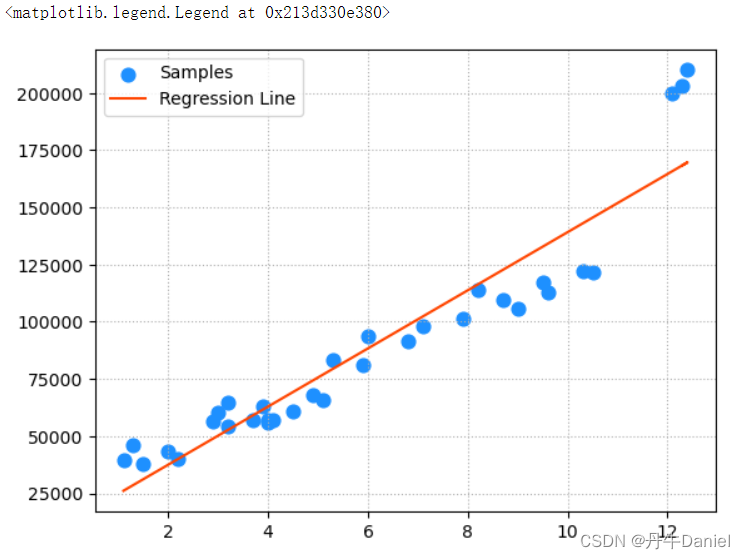
如果调整正则系数为100,可以看到模型的变化,对正常数据拟合效果变得好了。
model=lm.Ridge(100)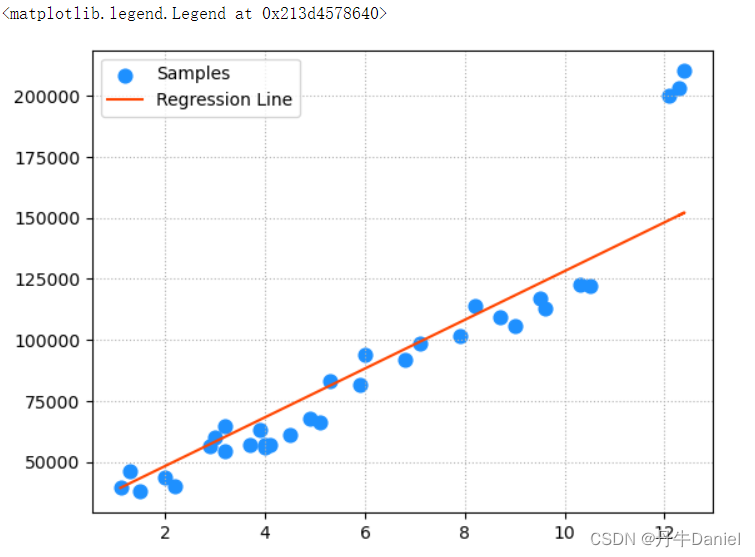
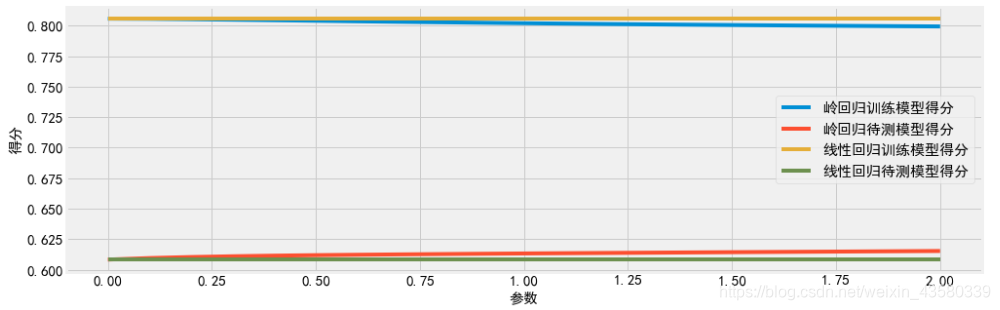
那么到底参数设置为多少比较好?
便需要利用上节课讲的,利用未被训练过的测试样本,能使得模型的一系列指标比如得到最高的分值的参数便是最好的。
https://blog.csdn.net/danielxinhj/article/details/127632062
调整岭回归的参数
可以写一个for循环,比如下面代码中从60-300,每隔5个选择1个作为超参数,并利用超参数训练岭回归模型,最后输出其得分
# 调整岭回归的参数
import sklearn.metrics as sm
params=np.arange(60,300,5)
for param in params:# 训练一个岭回归模型model=lm.Ridge(param)model.fit(train_x,train_y)# 找到一组测试样本数据,输出评估指标结果# 取测试集样本,从头至尾每4个切出1个数据test_x,test_y=train_x.iloc[:30:4],train_y.iloc[:30:4] # 进行预测pred_test_y=model.predict(test_x)# 评估误差print(param,'->',sm.r2_score(test_y,pred_test_y))输出结果为不同超参数对应的 得分,很明显发现当λ=100时,模型的性能是最好的。所以最终我们要选择的正则项参数λ=100。