快速傅里叶变换光声断层图像重建
前言
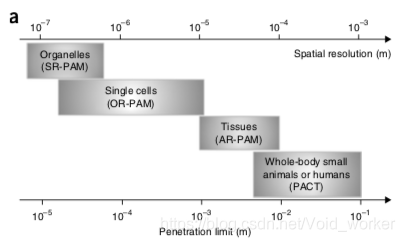
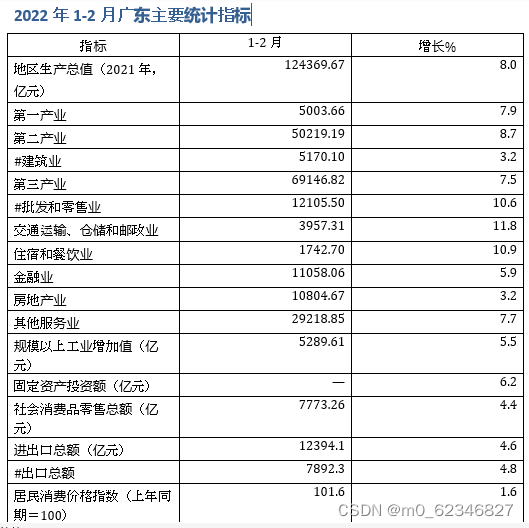
光声成像的基本原理是利用短脉宽的脉冲激光器激发组织中的吸收体产生光声信号,再结合相应的图像重建算法例如MIP,FBP和FFT(最大值投影算法,滤波反投影重建算法,傅里叶变换),本文仅针对FFT光声断层图像重建进行记录,方便以后学习,大家共同交流。
一、傅里叶断层图像重建方法
该方法基于一个重要的定理:中心切片定理。
该定理简单地理解就是:通过角度为θ扫描得到的投影,该投影的一维傅里叶变换,与对整个图像二维傅里叶变换后,二维频域中对应θ角度的一个切片信号是相同的,下面两个图理解起来更直观。
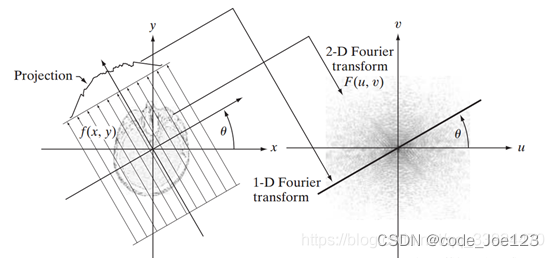
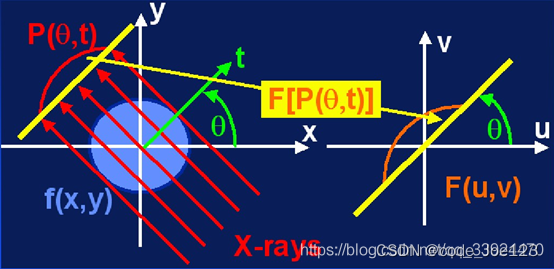
二、算法步骤
图2
根据该理论,傅里叶逆变换法可以简单分成以下步骤:
① 假设每旋转1°就扫描一次,当对物体扫描了180°之后,我们就能得到180个投影信号(就是180根投影线)→在临床上,若使用平行扫描CT,我们拿到手的数据就是这个(在数学上,就是对图像进行拉冬变换)
② 对180个投影信号进行一维傅里叶变换
③ 对②得到的180个一维频域信号,根据相对应的扫描角度,在空间中旋转排列,拼成一个二维频域空间(如图3)
④ 由于数据是离散的,直接按照角度进行排列难以铺满整个二维空间,因此还需要对空缺的地方进行插值(一般三次样条插值效果最好),但插值会带来一定误差。另外,由于中心的信号密集,周围的信号稀疏,显然会损失一部分高频数据,造成高频信号失真,这就是采用傅里叶逆变换法重构图像时会使得图像边缘模糊的原因。
⑤ 对④中拼接而成的二维图像进行二维傅里叶逆变换,就可重构原图

图3 傅里叶逆变换法
该方法的缺点有:
a/高频信号有所失真
b/在插值时还涉及到极坐标和直角坐标的变换,计算量大
c/需要用到二维傅里叶逆变换,总体耗费时间长
由于计算机处理二维傅里叶逆变换的计算量太大,因此很少直接使用该方法实现拉东逆变换。
重点参考
https://blog.csdn.net/sinolover/article/details/121375677