VGG系列的网络,在网络深度上相比于其之前的网络有了提升,VGG16与VGG19是VGG系列的代表,本次基于Tensorflow2.0实现VGG16网络。
1.VGG16 网络简介
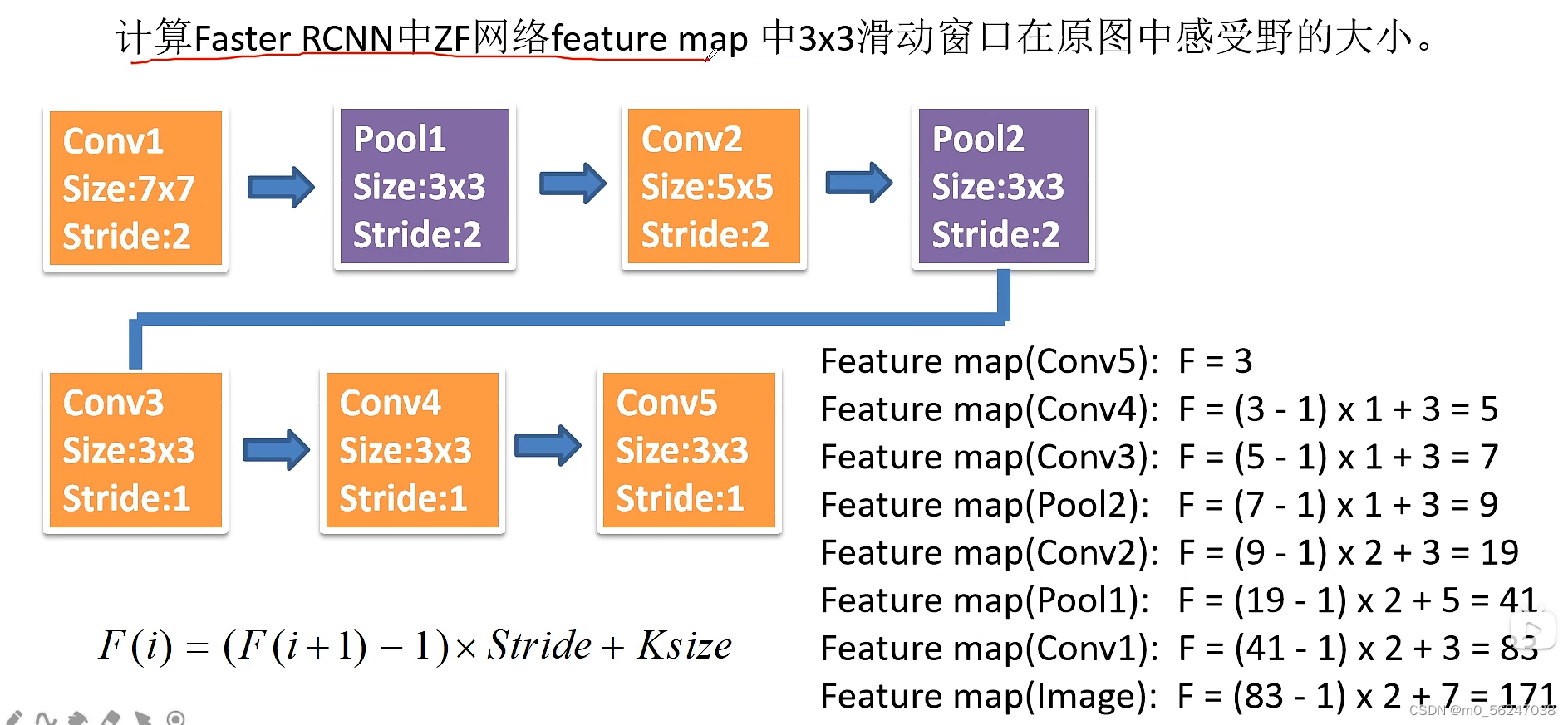
VGG16网络模型在2014年ImageNet比赛上脱颖而出,取得了在分类任务上排名第二,在定位任务上排名第一的好成绩。VGG16网络相比于之前的LexNet以及LeNet网络,在当时的网络层数上达到了空前的程度。
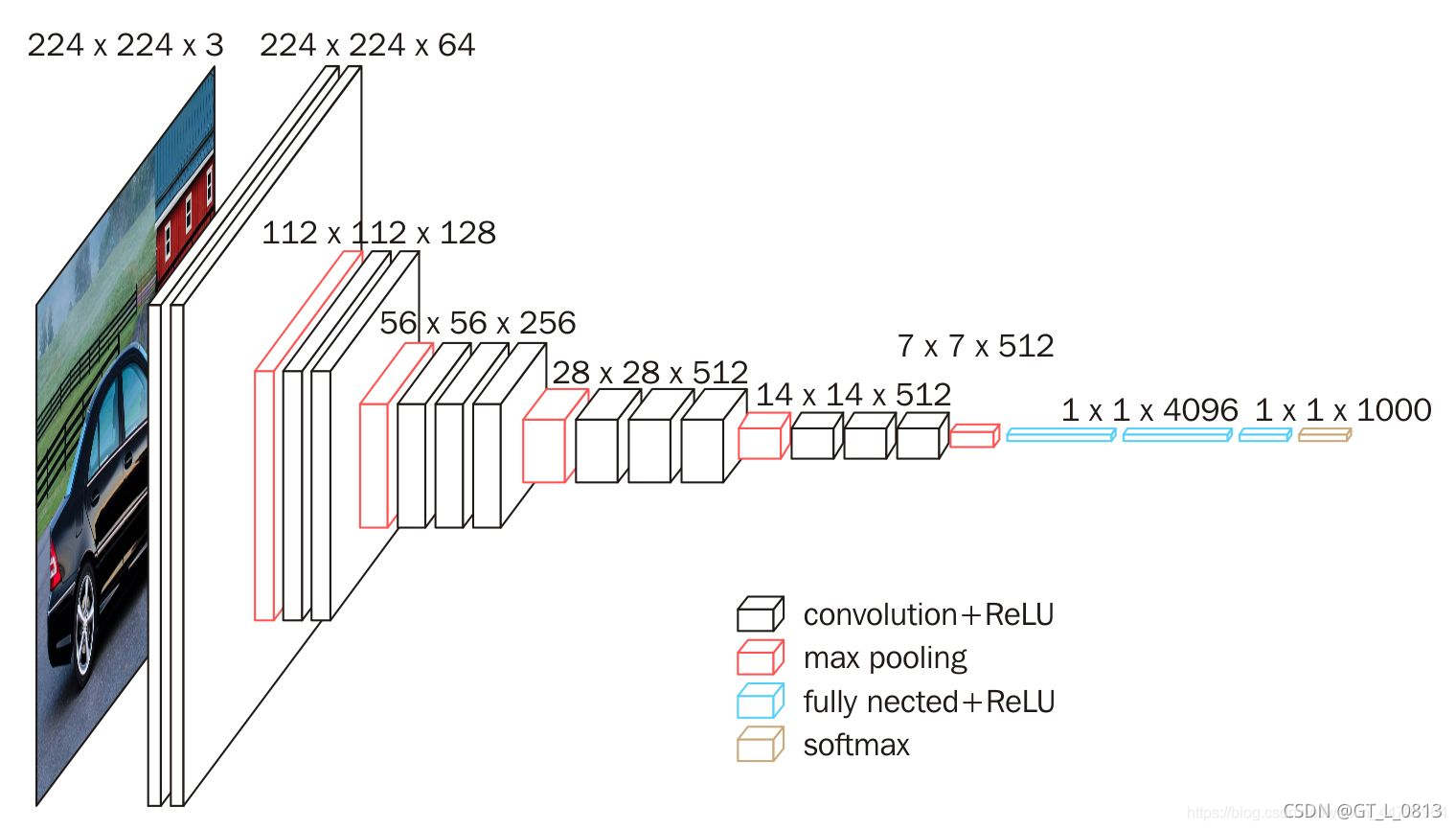
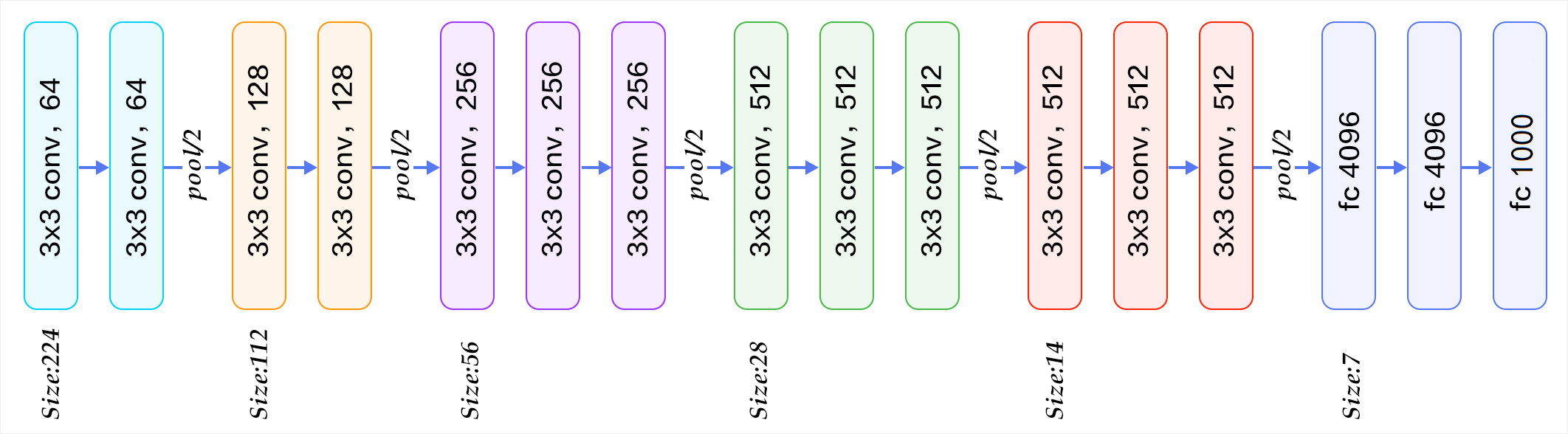
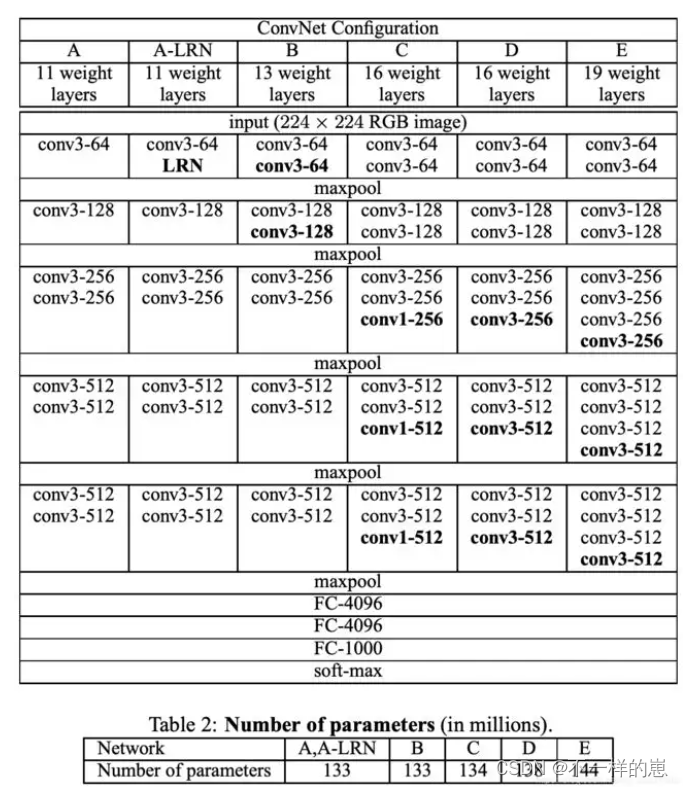
2.网络结构

3.创新点
① 使用3x3的卷积核代替7x7的卷积核。
3x3 卷积核是能够感受到上下、左右重点的最小的感受野尺寸。并且,2 个 3x3 的卷积核叠加,它们的感受野等同于 1 个 5x5 的卷积核,3 个叠加后,它们的感受野等同于 1 个 7x7 的效果。
由于感受野相同,3个3x3的卷积,使用了3个非线性激活函数,增加了非线性表达能力,使得分割平面更具有可分性。同时使用小卷积核,使得参数量大大减少。
使用3x3卷积核堆叠的形式,既增加了网络层数又减少了参数量。
② 通过不断增加通道数达到更深的网络,使用2x2池化核,使用Max-pooling方法。
使用2x2池化核,小的池化核能够带来更细节的信息捕获。当时也有average pooling,但是在图像任务上max-pooling的效果更好,max更加容易捕捉图像上的变化,带来更大的局部信息差异性,更好的描述边缘纹理等。
4.网络实现
def VGG16(nb_class,input_shape):input_ten = Input(shape=input_shape)#1x = tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same')(input_ten)x = tf.keras.layers.Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)#2x = tf.keras.layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.Conv2D(filters=128,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)#3x = tf.keras.layers.Conv2D(filters=256,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.Conv2D(filters=256,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.Conv2D(filters=256,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)#4x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)#5x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.Conv2D(filters=512,kernel_size=(3,3),activation='relu',padding='same')(x)x = tf.keras.layers.MaxPool2D(pool_size=(2,2),strides=(2,2))(x)#FCx = tf.keras.layers.Flatten()(x)x = Dense(4096,activation='relu')(x)x = Dense(4096,activation='relu')(x)output_ten = Dense(nb_class,activation='softmax')(x)model = Model(input_ten,output_ten)return model
model_VGG16 = VGG16(24,(img_height,img_width,3))
model_VGG16.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 56, 56, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
conv2d_6 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 28, 28, 256) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_8 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
conv2d_9 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 14, 14, 512) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv2d_11 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv2d_12 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
dense (Dense) (None, 4096) 102764544
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dense_2 (Dense) (None, 24) 98328
=================================================================
Total params: 134,358,872
Trainable params: 134,358,872
Non-trainable params: 0
_________________________________________________________________
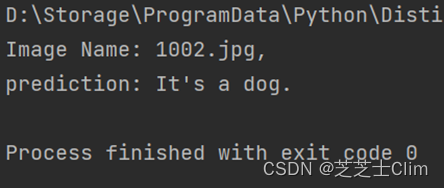
可以发现,VGG16的训练参数达到了134,358,872个,比AlexNet多了很多倍,但是VGG系列的网络性能还是比较好的。
努力加油a啊