1.VGG16 网络简介
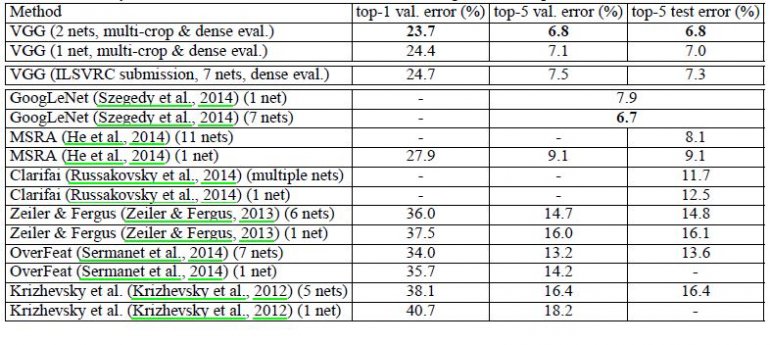
VGG16网络模型在2014年ImageNet比赛上脱颖而出,取得了在分类任务上排名第二,在定位任务上排名第一的好成绩。VGG16网络相比于之前的LexNet以及LeNet网络,在当时的网络层数上达到了空前的程度。
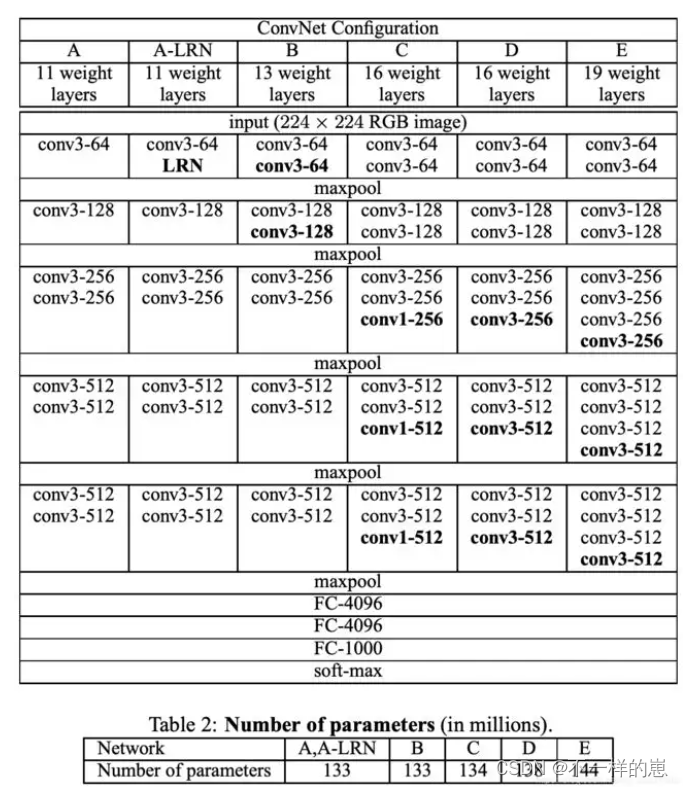
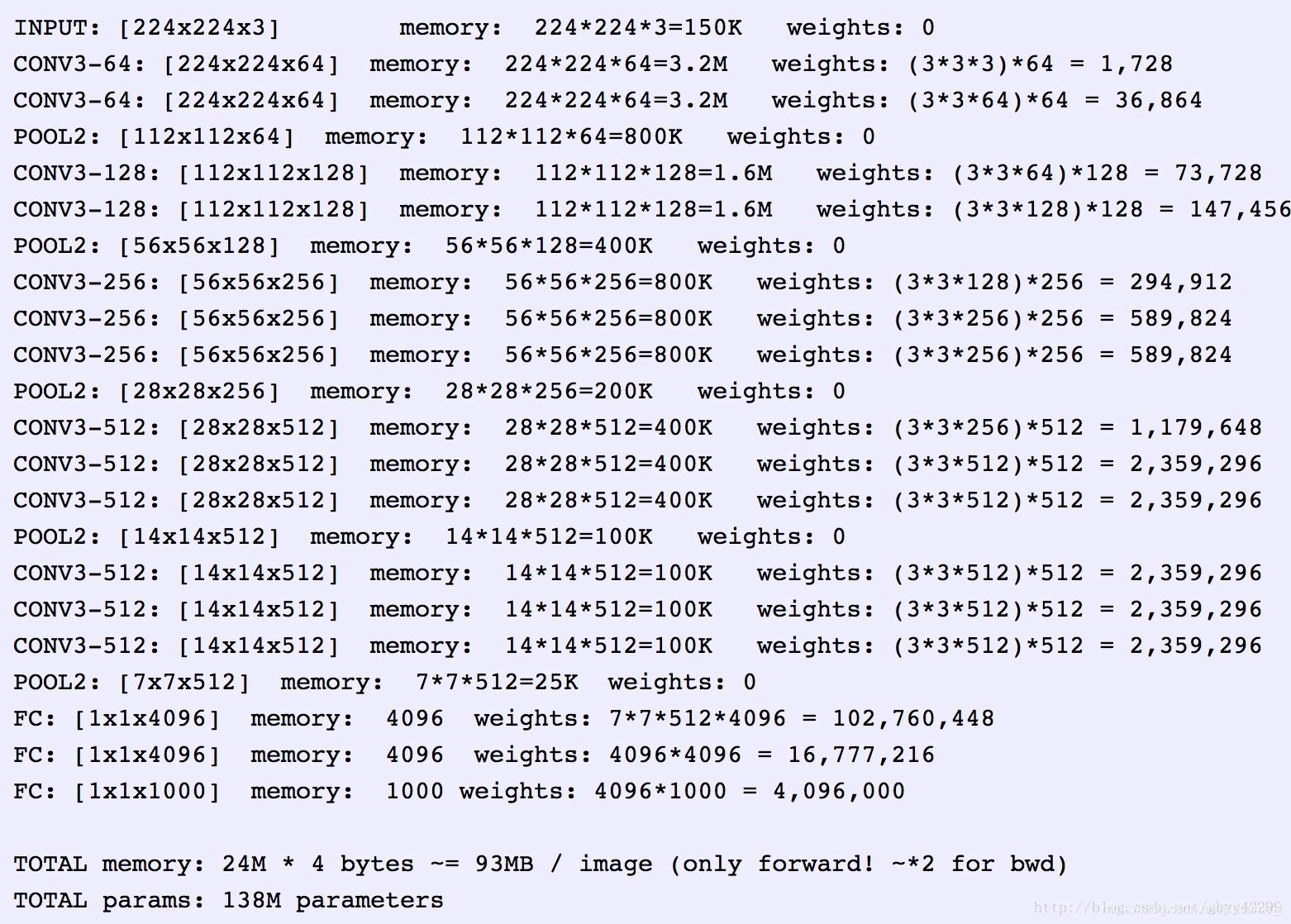
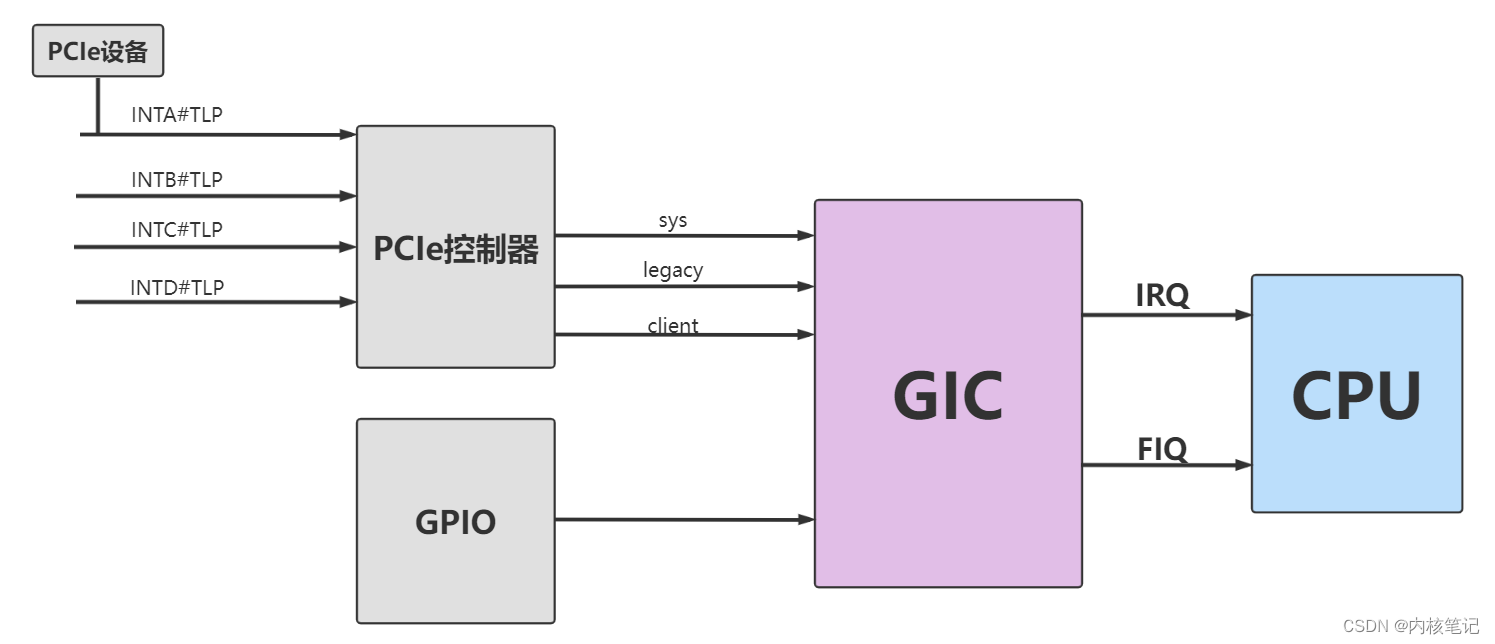
2.网络结构

3.创新点
① 使用3x3的卷积核代替7x7的卷积核。
3x3 卷积核是能够感受到上下、左右重点的最小的感受野尺寸。并且,2 个 3x3 的卷积核叠加,它们的感受野等同于 1 个 5x5 的卷积核,3 个叠加后,它们的感受野等同于 1 个 7x7 的效果。
由于感受野相同,3个3x3的卷积,使用了3个非线性激活函数,增加了非线性表达能力,使得分割平面更具有可分性。同时使用小卷积核,使得参数量大大减少。
使用3x3卷积核堆叠的形式,既增加了网络层数又减少了参数量。
② 通过不断增加通道数达到更深的网络,使用2x2池化核,使用Max-pooling方法。
使用2x2池化核,小的池化核能够带来更细节的信息捕获。当时也有average pooling,但是在图像任务上max-pooling的效果更好,max更加容易捕捉图像上的变化,带来更大的局部信息差异性,更好的描述边缘纹理等。
4.网络实现
import torch
import torch.nn as nn
import torch.nn.functional as Fclass VGG16(nn.Module):def __init__(self):super(VGG16, self).__init__()# 3 * 224 * 224self.conv1_1 = nn.Conv2d(3, 64, 3) # 64 * 222 * 222self.conv1_2 = nn.Conv2d(64, 64, 3, padding=(1, 1)) # 64 * 222* 222self.maxpool1 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 64 * 112 * 112self.conv2_1 = nn.Conv2d(64, 128, 3) # 128 * 110 * 110self.conv2_2 = nn.Conv2d(128, 128, 3, padding=(1, 1)) # 128 * 110 * 110self.maxpool2 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 128 * 56 * 56self.conv3_1 = nn.Conv2d(128, 256, 3) # 256 * 54 * 54self.conv3_2 = nn.Conv2d(256, 256, 3, padding=(1, 1)) # 256 * 54 * 54self.conv3_3 = nn.Conv2d(256, 256, 3, padding=(1, 1)) # 256 * 54 * 54self.maxpool3 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 256 * 28 * 28self.conv4_1 = nn.Conv2d(256, 512, 3) # 512 * 26 * 26self.conv4_2 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 26 * 26self.conv4_3 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 26 * 26self.maxpool4 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 512 * 14 * 14self.conv5_1 = nn.Conv2d(512, 512, 3) # 512 * 12 * 12self.conv5_2 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 12 * 12self.conv5_3 = nn.Conv2d(512, 512, 3, padding=(1, 1)) # 512 * 12 * 12self.maxpool5 = nn.MaxPool2d((2, 2), padding=(1, 1)) # pooling 512 * 7 * 7# viewself.fc1 = nn.Linear(512 * 7 * 7, 4096)self.fc2 = nn.Linear(4096, 4096)self.fc3 = nn.Linear(4096, 1000)# softmax 1 * 1 * 1000def forward(self, x):# x.size(0)即为batch_sizein_size = x.size(0)out = self.conv1_1(x) # 222out = F.relu(out)out = self.conv1_2(out) # 222out = F.relu(out)out = self.maxpool1(out) # 112out = self.conv2_1(out) # 110out = F.relu(out)out = self.conv2_2(out) # 110out = F.relu(out)out = self.maxpool2(out) # 56out = self.conv3_1(out) # 54out = F.relu(out)out = self.conv3_2(out) # 54out = F.relu(out)out = self.conv3_3(out) # 54out = F.relu(out)out = self.maxpool3(out) # 28out = self.conv4_1(out) # 26out = F.relu(out)out = self.conv4_2(out) # 26out = F.relu(out)out = self.conv4_3(out) # 26out = F.relu(out)out = self.maxpool4(out) # 14out = self.conv5_1(out) # 12out = F.relu(out)out = self.conv5_2(out) # 12out = F.relu(out)out = self.conv5_3(out) # 12out = F.relu(out)out = self.maxpool5(out) # 7# 展平out = out.view(in_size, -1)out = self.fc1(out)out = F.relu(out)out = self.fc2(out)out = F.relu(out)out = self.fc3(out)out = F.log_softmax(out, dim=1)return outvgg=VGG16()
print(vgg)
VGG16((conv1_1): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1))(conv1_2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool1): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), dilation=1, ceil_mode=False)(conv2_1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1))(conv2_2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool2): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), dilation=1, ceil_mode=False)(conv3_1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1))(conv3_2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(conv3_3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool3): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), dilation=1, ceil_mode=False)(conv4_1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1))(conv4_2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(conv4_3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool4): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), dilation=1, ceil_mode=False)(conv5_1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1))(conv5_2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(conv5_3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(maxpool5): MaxPool2d(kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), dilation=1, ceil_mode=False)(fc1): Linear(in_features=25088, out_features=4096, bias=True)(fc2): Linear(in_features=4096, out_features=4096, bias=True)(fc3): Linear(in_features=4096, out_features=1000, bias=True)
)