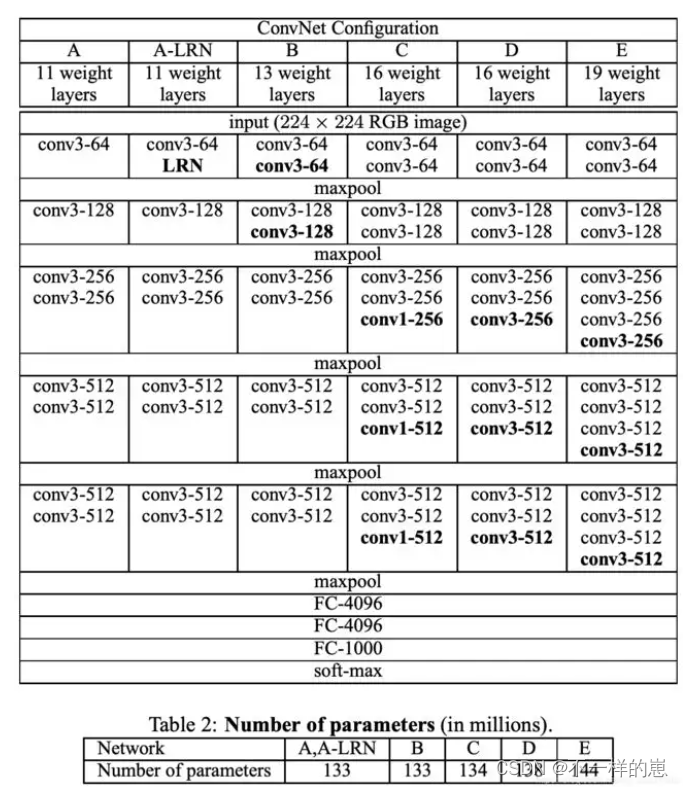
VGG16总共有16层(不包括池化层),13个卷积层和3个全连接层,第一次经过64个卷积核的两次卷积后,采用一次pooling,第二次经过两次128个卷积核卷积后,采用pooling;再经过3次256个卷积核卷积后,采用pooling;再经过3次512个卷积核卷积,采用pooling;再经过3次512个卷积核卷积,采用pooling,最后经过三次全连接。

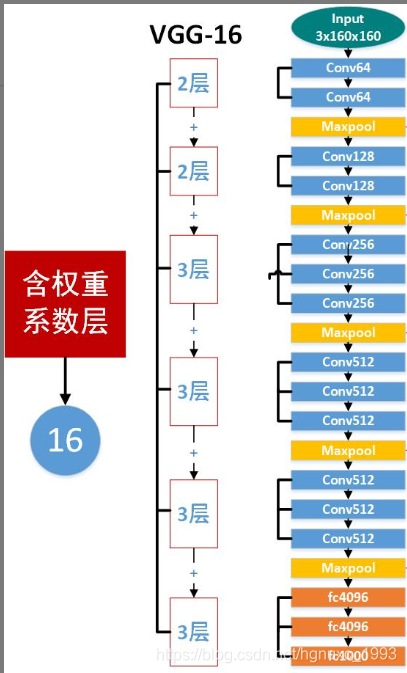
| 模块 | 各模块的涉及的层次 |
| 输入模块 | 224*224*3 |
| 第一个模块 | conv3-64 |
| conv3-64 | |
| maxpool | |
| 第二个模块 | conv3-128 |
| conv3-128 | |
| maxpool | |
| 第三个模块 | conv3-256 |
| conv3-256 | |
| conv3-256 | |
| maxpool | |
| 第四个模块 | conv3-512 |
| conv3-512 | |
| conv3-512 | |
| maxpool | |
| 第五个模块 | conv3-512 |
| conv3-512 | |
| conv3-512 | |
| maxpool | |
| 第六个模块(全连接层和输出层) | FC-4096 (实际上前面需要加一个Flatten层) |
| FC-4096 | |
| FC-1000 (负责分类,有几个类别输出就是几) | |
| softmax(输出层函数) |
步骤理解
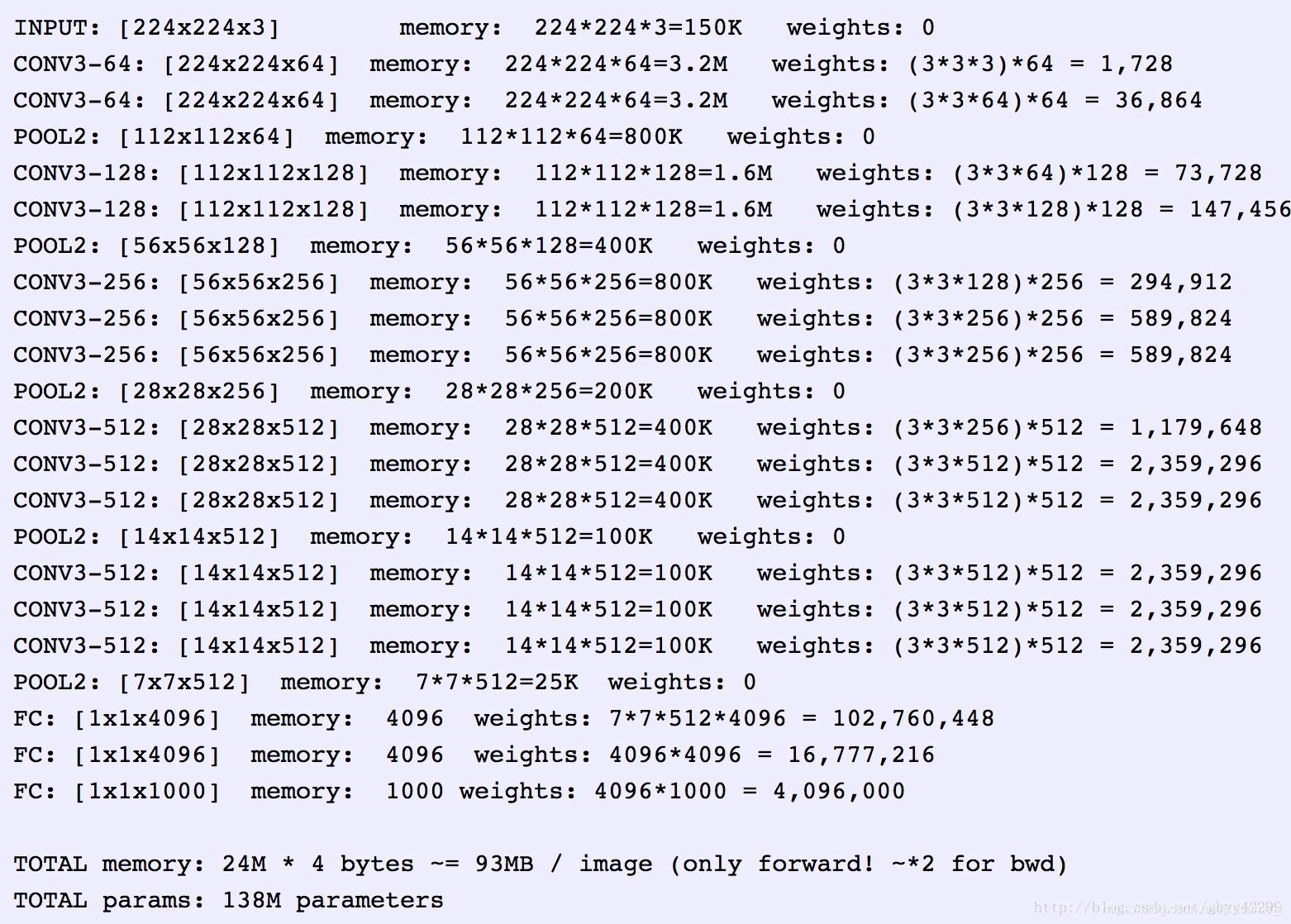
下面算一下每一层的像素值计算:
输入:224 * 224 * 3
conv3-64(卷积核的数量)----------------------------------------kernel size:3 stride:1 padding:1
像素:(224 + 2 * 1 – 1 * (3 - 1)- 1 )/ 1 + 1=224 ---------------------输出尺寸:224 * 224 * 64
参数: (3 * 3 * 3)* 64 =1728
conv3-64-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (224 + 2 * 1 – 2 - 1)/ 1 + 1=224 ---------------------输出尺寸:224 * 224 * 64
参数: (3 * 3 * 64) * 64 =36864
pool2 ----------------------------------------------------------------kernel size:2 stride:2 padding:0
像素: (224 - 2)/ 2 = 112 ----------------------------------输出尺寸:112 * 112 * 64
参数: 0
conv3-128(卷积核的数量)--------------------------------------------kernel size:3 stride:1 padding:1
像素: (112 + 2 * 1 - 2 - 1) / 1 + 1 = 112 -------------------输出尺寸:112 * 112 * 128
参数: (3 * 3 * 64) * 128 =73728
conv3-128------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (112 + 2 * 1 -2 - 1) / 1 + 1 = 112 ---------------------输出尺寸:112 * 112 * 128
参数: (3 * 3 * 128) * 128 =147456
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素: (112 - 2) / 2 + 1=56 ----------------------------------输出尺寸:56 * 56 * 128
参数:0
conv3-256(卷积核的数量)----------------------------------------------kernel size:3 stride:1 padding:1
像素: (56 + 2 * 1 - 2 - 1)/ 1+1=56 -----------------------------输出尺寸:56 * 56 * 256
参数:(3 * 3* 128)*256=294912
conv3-256-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素: (56 + 2 * 1 - 2 - 1) / 1 + 1=56 --------------------------输出尺寸:56 * 56 * 256
参数:(3 * 3 * 256) * 256=589824
conv3-256------------------------------------------------------------ kernel size:3 stride:1 padding:1
像素: (56 + 2 * 1 - 2 - 1) / 1 + 1=56 -----------------------------输出尺寸:56 * 56 * 256
参数:(3 * 3 * 256)*256=589824
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素:(56 - 2) / 2 + 1 = 28-------------------------------------输出尺寸: 28 * 28 * 256
参数:0
conv3-512(卷积核的数量)------------------------------------------kernel size:3 stride:1 padding:1
像素:(28 + 2 * 1 - 2 - 1) / 1 + 1=28 ----------------------------输出尺寸:28 * 28 * 512
参数:(3 * 3 * 256) * 512 = 1179648
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(28 + 2 * 1 - 2 - 1) / 1 + 1=28 ----------------------------输出尺寸:28 * 28 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(28 + 2 * 1 - 2 - 1) / 1 + 1=28 ----------------------------输出尺寸:28 * 28 * 512
参数:(3 * 3 * 512) * 512 = 2359296
pool2------------------------------------------------------------------ kernel size:2 stride:2 padding:0
像素:(28 - 2) / 2 + 1=14 -------------------------------------输出尺寸:14 * 14 * 512
参数: 0
conv3-512(卷积核的数量)----------------------------------------------kernel size:3 stride:1 padding:1
像素:(14 + 2 * 1 - 2 - 1) / 1 + 1=14 ---------------------------输出尺寸:14 * 14 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(14 + 2 * 1 - 2 - 1) / 1 + 1=14 ---------------------------输出尺寸:14 * 14 * 512
参数:(3 * 3 * 512) * 512 = 2359296
conv3-512-------------------------------------------------------------kernel size:3 stride:1 padding:1
像素:(14 + 2 * 1 - 2 - 1) / 1 + 1=14 ---------------------------输出尺寸:14 * 14 * 512
参数:(3 * 3 * 512) * 512 = 2359296
pool2------------------------------------------------------------------kernel size:2 stride:2 padding:0
像素:(14 - 2) / 2 + 1=7 ----------------------------------------输出尺寸:7 * 7 * 512
参数:0
FC------------------------------------------------------------------------ 4096 neurons
像素:1 * 1 * 4096
参数:7 * 7 * 512 * 4096 = 102760448
FC------------------------------------------------------------------------ 4096 neurons
像素:1 * 1 * 4096
参数:4096 * 4096 = 16777216
FC------------------------------------------------------------------------ 1000 neurons
像素:1 * 1 * 1000
参数:4096 * 1000=4096000

因为在pytorch中默认dilation是为1的,故上式也可以简化为
Hout = (Hin + 2padding - kernel_size ) / stride +1
参数 = kernel size * in_channels * out_channels
max pooling(kernel size:2 stride:2 padding:0)不改变通道数,只会让特征图尺寸减半
卷积时卷积核的数量就是输出的通道数
BatchNorm跟输出通道数保持一致
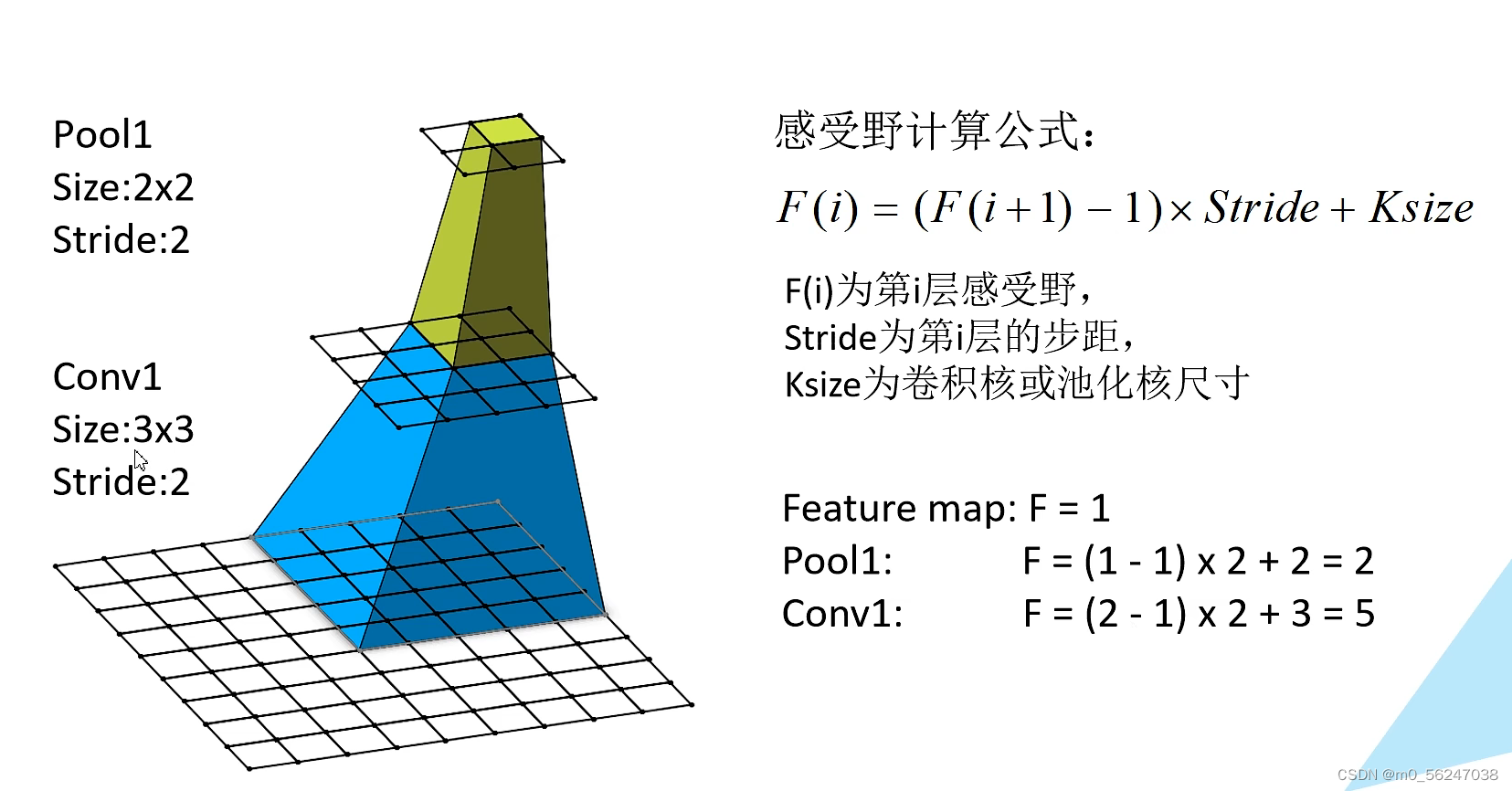
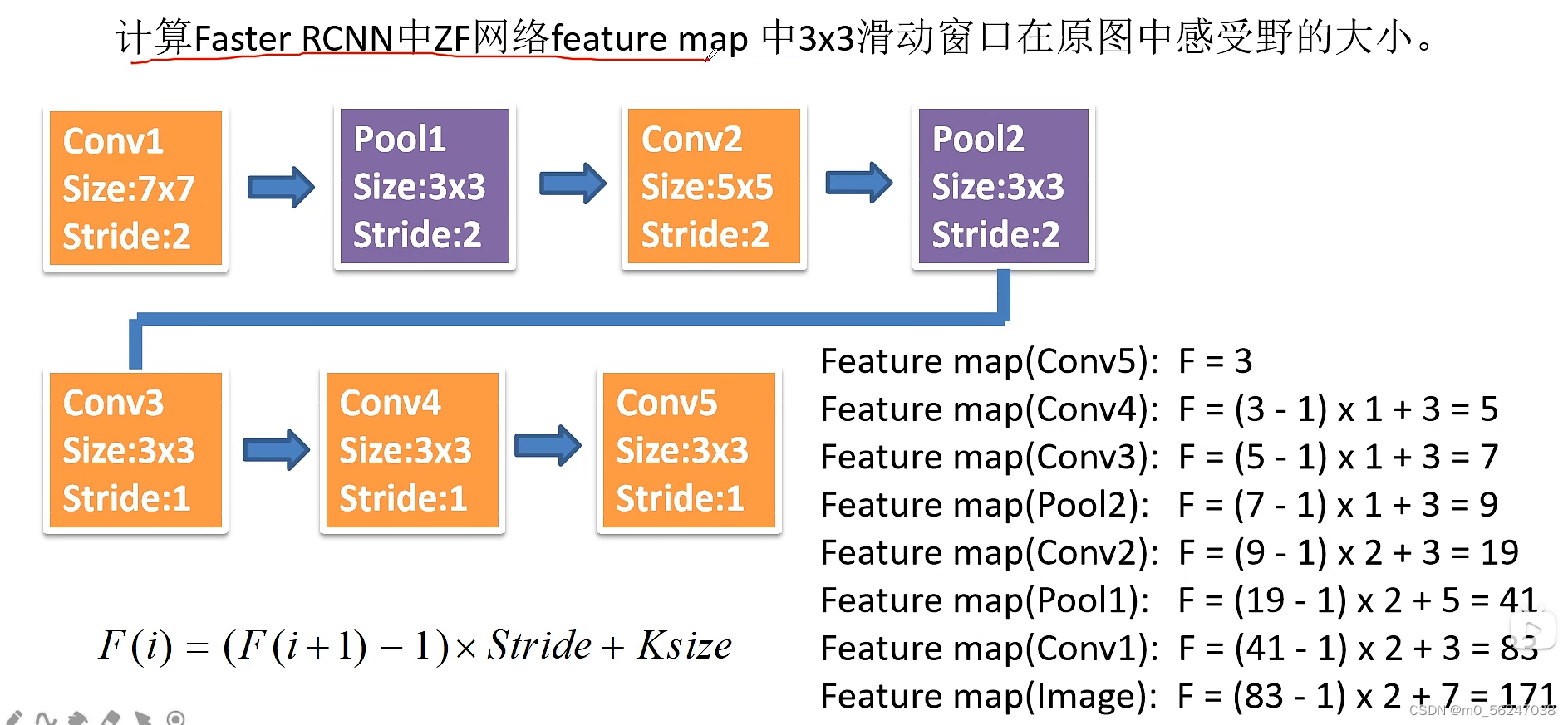
假设从下往上数为特征层1,2,3,第3个特征层的一个1×1的感受野(F(i+1)=1)对应上一个(第二个)特征层2×2大小的感受野,第2个特征层的一个2×2的感受野(F(i+1)=2)对应上一个(第一个)特征层5×5大小的感受野。
默认步距stride=1,两个3×3的卷积核和一个5×5的卷积核得到的特征图大小是一样的,三个3×3的卷积核和一个7×7的卷积核得到的特征图大小是一样的。

net.py如下:
import torch
from torch import nn
import torch.nn.functional as F# 224 * 224 * 3
class Vgg16_net(nn.Module):def __init__(self):super(Vgg16_net, self).__init__()self.layer1 = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1), # 224 * 224 * 64nn.BatchNorm2d(64), # Batch Normalization强行将数据拉回到均值为0,方差为1的正太分布上,一方面使得数据分布一致,另一方面避免梯度消失。nn.ReLU(inplace=True),nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1), # 224 * 224 * 64nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2) # 112 * 112 * 64)self.layer2 = nn.Sequential(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1), # 112 * 112 * 128nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1), # 112 * 112 * 128nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2) # 56 * 56 * 128)self.layer3 = nn.Sequential(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1), # 56 * 56 * 256nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), # 56 * 56 * 256nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1), # 56 * 56 * 256nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2) # 28 * 28 * 256)self.layer4 = nn.Sequential(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1), # 28 * 28 * 512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), # 28 * 28 * 512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), # 28 * 28 * 512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2) # 14 * 14 * 512)self.layer5 = nn.Sequential(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), # 14 * 14 * 512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), # 14 * 14 * 512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1), # 14 * 14 * 512nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2) # 7 * 7 * 512)self.conv = nn.Sequential(self.layer1,self.layer2,self.layer3,self.layer4,self.layer5)self.fc = nn.Sequential(nn.Linear(7*7*512, 512),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(512, 256),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(256, 10) # 十分类问题)def forward(self, x):x = self.conv(x)# 这里-1表示一个不确定的数,就是你如果不确定你想要reshape成几行,但是你很肯定要reshape成7*7*512列# 那不确定的地方就可以写成-1# 如果出现x.size(0)表示的是batchsize的值# x=x.view(x.size(0),-1)x = x.view(-1, 7*7*512)x = self.fc(x)return xtrain.py如下:
import json
import sysimport torch
import torchvision
from torch import nn, optim
from tqdm import tqdmfrom net import Vgg16_net
import numpy as np
from torch.optim import lr_scheduler
import osfrom torchvision import transforms
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoaderimport matplotlib.pyplot as plt
# import torchvision.models.vgg 可以在这里面下载预训练权重import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'ROOT_TRAIN = r'E:/cnn/AlexNet/data/train'
ROOT_TEST = r'E:/cnn/AlexNet/data/val'def main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {"train": transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])} # 数据预处理train_dataset = ImageFolder(ROOT_TRAIN, transform=data_transform["train"]) # 加载训练集train_num = len(train_dataset) # 打印训练集有多少张图片animal_list = train_dataset.class_to_idx # 获取类别名称以及对应的索引cla_dict = dict((val, key) for key, val in animal_list.items()) # 将上面的键值对位置对调一下json_str = json.dumps(cla_dict, indent=4) # 把类别和对应的索引写入根目录下class_indices.json文件中with open('class_indices.json', 'w') as json_file:json_file.write(json_str)batch_size = 32train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size, shuffle=True,num_workers=0)validate_dataset = ImageFolder(ROOT_TEST, transform=data_transform["val"]) # 载入测试集val_num = len(validate_dataset) # 打印测试集有多少张图片validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=16, shuffle=False,num_workers=0)print("using {} images for training, {} images for validation.".format(train_num, val_num)) # 用于打印总的训练集数量和验证集数量# 用于查看数据集,注意改一下上面validate_loader的batch_size,batch_size等几就是一次查看几张图片,shuffle=True顺序打乱一下# test_data_iter = iter(validate_loader)# test_image, test_label = test_data_iter.next()## def imshow(img):# img = img / 2 + 0.5 # unnormalize# npimg = img.numpy()# plt.imshow(np.transpose(npimg, (1, 2, 0)))# plt.show()## print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))# imshow(utils.make_grid(test_image))net = Vgg16_net(num_classes=2) # 实例化网络,num_classes代表有几个类别# 载入预训练模型参数(如果不想使用迁移学习的方法就把下面五行注释掉,然后在resnet34()里传入参数num_classes即可,如果使用迁移学习的方法就不需要在resnet34()里传入参数num_classes)# model_weight_path = "./vgg16-pre.pth" # 预训练权重# assert os.path.exists(model_weight_path), "file {} does not exist.".format(model_weight_path)# net.load_state_dict(torch.load(model_weight_path, map_location='cpu')) # 通过torch.load载入模型预训练权重# in_channel = net.fc.in_features# net.fc = nn.Linear(in_channel, 2) # 重新赋值全连接层,这里的2指代的是类别数,训练时需要改一下# VGG加载预训练权重没有成功net.to(device) # 将网络指认到GPU或CPU上loss_function = nn.CrossEntropyLoss()# pata = list(net.parameters())optimizer = optim.Adam(net.parameters(), lr=0.0002)epochs = 1save_path = './VGGNet.pth'best_acc = 0.0train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,epochs,loss)# validatenet.eval()acc = 0.0 # accumulate accurate number / epochwith torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar: # 遍历验证集val_images, val_labels = val_data # 数据分为图片和标签outputs = net(val_images.to(device)) # 将图片指认到设备上传入网络进行正向传播并得到输出predict_y = torch.max(outputs, dim=1)[1] # 求得输出预测中最有可得的类别(概率最大值)acc += torch.eq(predict_y, val_labels.to(device)).sum().item() # 将预测标签与真实标签进行比对,求得总的预测正确数量val_accurate = acc / val_num # 预测正确数量/测试集总数量print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %(epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()predict.py如下:
import os
import jsonimport torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as pltfrom net import Vgg16_netimport os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'def main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg_path = "./7.jpg"assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path)plt.imshow(img)# [N, C, H, W]img = data_transform(img)# expand batch dimensionimg = torch.unsqueeze(img, dim=0)# read class_indictjson_path = './class_indices.json'assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)with open(json_path, "r") as f:class_indict = json.load(f)# create modelmodel = Vgg16_net(num_classes=2).to(device)# load model weightsweights_path = "./VGGNet.pth"assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)model.load_state_dict(torch.load(weights_path, map_location=device))model.eval()with torch.no_grad():# predict classoutput = torch.squeeze(model(img.to(device))).cpu()predict = torch.softmax(output, dim=0)predict_cla = torch.argmax(predict).numpy()print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()
REFERENCE:
[深度学习]-从零开始手把手教你利用pytorch训练VGG16网络实现自定义数据集上的图像分类(含代码及详细注释)_orangezs的博客-CSDN博客_vgg16实现图片分类
经典卷积神经网络---VGG16详解_无尽的沉默的博客-CSDN博客_vgg16