VGG16模型的学习以及源码分析
part one
主要学习参考
- pytorch 英文文档
- VGG16学习笔记
- VGG16网络原理分析与pytorch实现
- 【深度学习】全面理解VGG16模型
- VGG模型的pytorch代码实现
- VGG16源代码详解
- 【论文】 VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
part two
一、VGG网络
1、 VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写
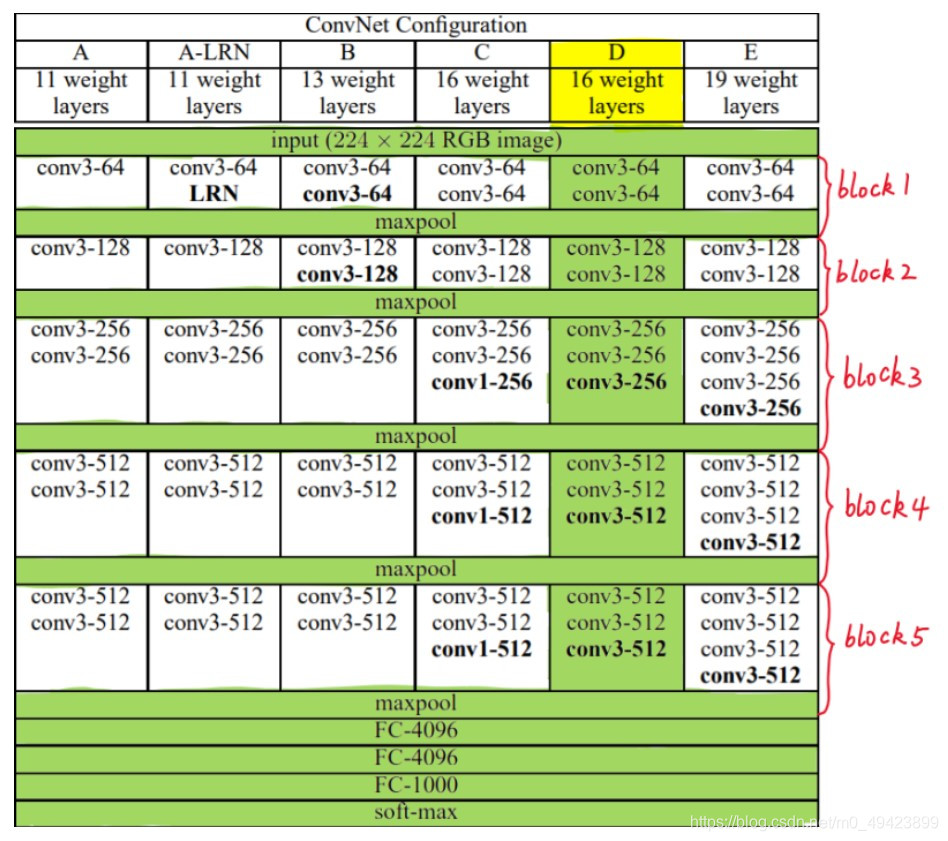
2、 VGG6种结构配置(根据卷积核大小和卷积层数目的不同)(绿色部分为VGG16采用的结构)
二、VGG16
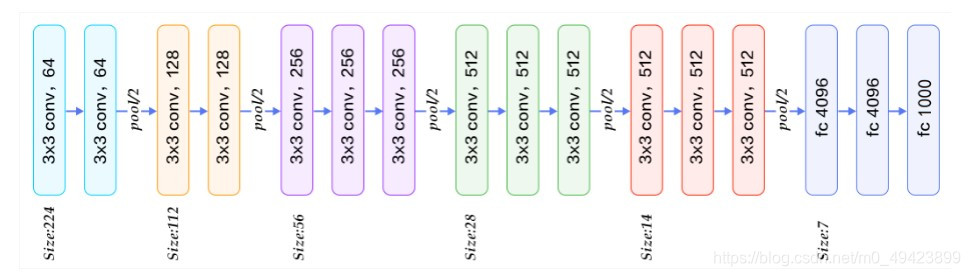
1)VGG16结构
包括:
-
13个卷积层(Convolutional Layer),分别用conv3-XXX表示
-
3个全连接层(Fully connected Layer),分别用FC-XXXX表示
-
5个池化层(Pool layer),分别用maxpool表示
注意:卷积层和全连接层具有权重系数,也被称为权重层,13+3=16(出处)
2)特点
1、卷积层:均采用相同的卷积核参数
conv3-xxx:conv3代表卷积核的尺寸(kernel size)是3 ,即宽(width)和高(height)均为3 ,卷积核尺寸是3×3;xxx代表卷积层通道数 \ 特征通道数
卷积核 也就是过滤器 filter
2、池化层:采用相同的池化层参数 2×2 ( kernel_size=2并且stride=2的pooling操作可以让长宽各降低一半 ,即特征图尺寸减半)
还有均值池化
3、 Small filters, Deeper networks
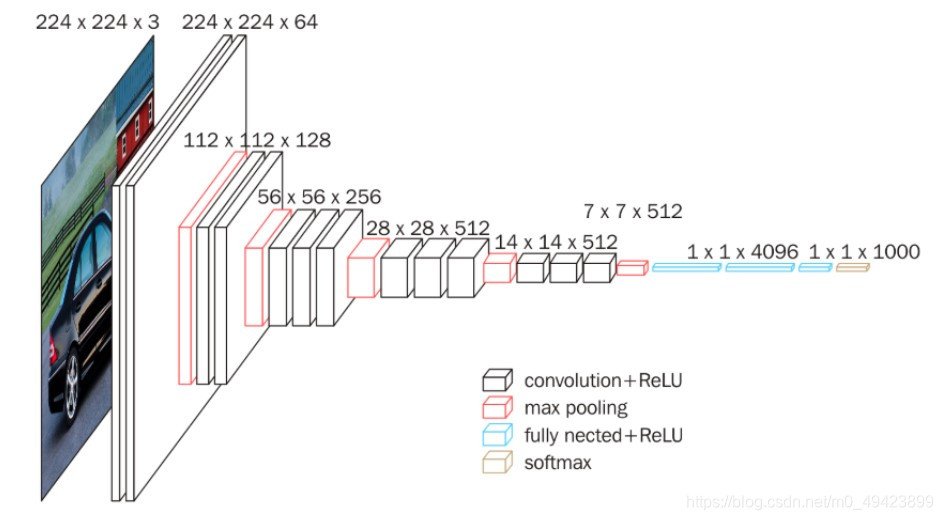
3) 块结构
1、Block1~block5 每一个块内包含若干卷积层和一个池化层
2、 同一块内,卷积层的通道(channel)数相同
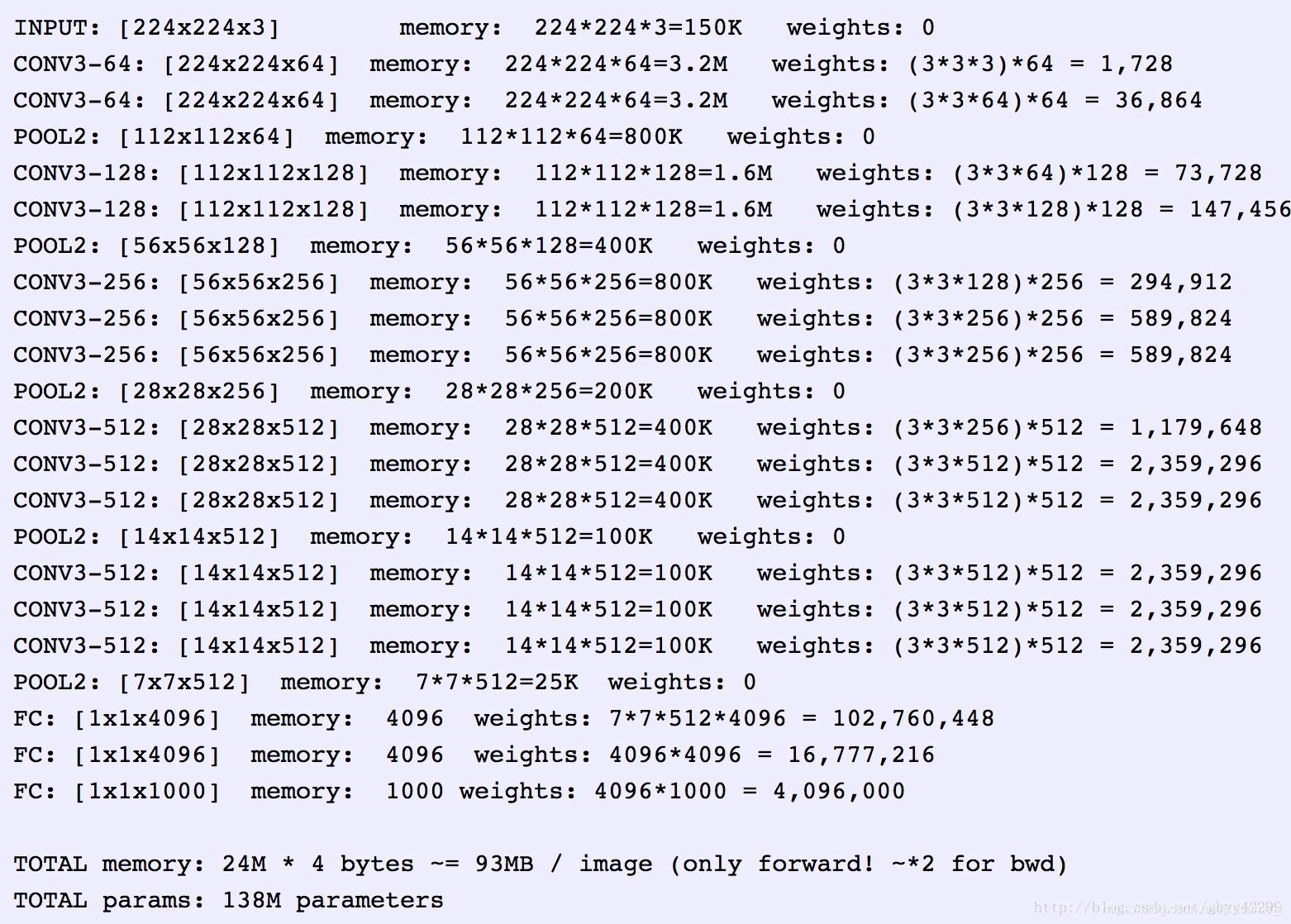
3、VGG的输入图像是 224x224x3 的图像张量(tensor),随着层数的增加,后一个块内的张量相比于前一个块内的张量:
- 通道数翻倍,由64依次增加到128,再到256,直至512保持不变,不再翻倍
- 高和宽变减半,由 224→112→56→28→14→7
4)权重参数
1、 这些参数包括卷积核权重和全连接层权重
-
例如,对于第一层卷积,由于输入图的通道数是3,网络必须学习大小为3x3,通道数为3的的卷积核,这样的卷积核有64个,因此总共有(3x3x3)x64 = 1728个参数
-
计算全连接层的权重参数数目的方法为:前一层节点数×本层的节点数前一层节点数×本层的节点数。因此,全连接层的参数分别为:
- 7×7×512×4096 = 1027,645,444
- 1×1×4096×4096 = 16,781,321
- 1×1×4096×1000 = 4096000
-
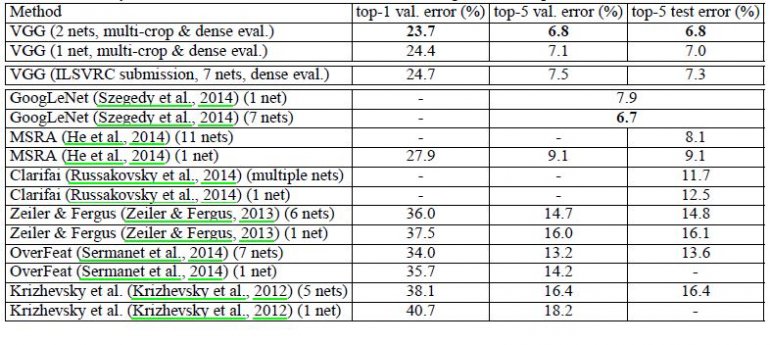
整个网络存储参数,(不考虑偏置), 蓝色是计算权重参数数量的部分;红色是计算所需存储容量的部分

三、VGG类的整体结构
1、 类初始化函数需要提供num_classes,表示需要进行多少分类
2、 init() 的 extract_feature 属性 负责卷积、激活和最大池化 ( net这个空list通过不断append新的操作实现特征提取 )
》》 reshape 操作 , forward()前进行,forward()负责前向传播
classifier 属性 提供最后的三个全连接操作
part three
源码
import torch
import torch.nn as nn__all__ = ['VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn','vgg19_bn', 'vgg19',
]from torch.hub import load_state_dict_from_urlmodel_urls = {'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth','vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth','vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth','vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth','vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth','vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth','vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth','vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}# VGG类,输入特征层和类别个数,得到类别向量
class VGG(nn.Module): # 定义了名为VGG的网络,继承了nn.Module的属性。def __init__(self, features, num_classes=1000, init_weights=True):super(VGG, self).__init__() #在实现自己的某层的时候借助了nn.Module,在构造函数中要调用Module的构造函数# 等价于nn.Module.__init__(self)self.features = features #features:输入参数,,features对应的是模型的卷积部分self.avgpool = nn.AdaptiveAvgPool2d((7, 7)) #nn.AdaptiveAvgPool2d:平均池化函数,尺寸:7*7# 利用nn.Sequential()方法定义了一个固定的全连接网络模块结构self.classifier = nn.Sequential( # 定义分类器 , #Sequential:组合形成一个子网络:分类网络nn.Linear(512 * 7 * 7, 4096), # Linear:接受固定的输入nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, num_classes),)# 初始化权重if init_weights:self._initialize_weights()# 利用forward函数来调用定义好的网络def forward(self, x): # 把输入图像通过feature计算得到特征层x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1) #连接全连接层和卷积层,要拉成一维向量x = self.classifier(x)return x# 权重初始化的方法def _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d): # isinstance 检查m是哪一个类型nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):nn.init.constant_(m.weight, 1)nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)'''
比较关键的一层,从cfg构建特征提取网络
'''# 根据不同的配置文件,定义不同的网络卷积层
def make_layers(cfg, batch_norm=False):layers = []in_channels = 3for v in cfg:# 如果是M,生成最大池化层if v == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]# 生成卷积层else:conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)# 如果是batch_norm,批次正交化,加入批次正交化,加速网络训练if batch_norm:layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]else:layers += [conv2d, nn.ReLU(inplace=True)]in_channels = v# Sequential:可以生成静态的网络,也可以生成动态的网络return nn.Sequential(*layers)# cfg 用字母作为字典索引,方便获得对应的列表 vgg16对应D 详见论文
cfgs = {'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}'''_vgg的含义 通过读取cfg构建输入参数对应的网络如果要构建vgg16,输入参数:arch = 'vgg16'cfg = 'D'batch_norm = False
'''# 对VGG再进行封装 ,,arch和cfg都是字典,指定哪种vgg结构进行后续步骤,,batch_norm 是bool类型,判断是否经过bn
def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs): # pretrained用不用预训练模型,也是boolif pretrained: # **kwargs 是字典参量,键值对 ,, 如果要预训练,那就不初始化权重了,而是有已知权重??kwargs['init_weights'] = Falsemodel = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs) # 建模,创建VGG类if pretrained:# load_state_dict_from_url:加载模型参数,progress:是否显示进度条state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)# 加载模型model.load_state_dict(state_dict)return model# bn 是 batch normalization 批标准化
def vgg11(pretrained=False, progress=True, **kwargs):return _vgg('vgg11', 'A', False, pretrained, progress, **kwargs)def vgg11_bn(pretrained=False, progress=True, **kwargs):return _vgg('vgg11_bn', 'A', True, pretrained, progress, **kwargs)def vgg13(pretrained=False, progress=True, **kwargs):return _vgg('vgg13', 'B', False, pretrained, progress, **kwargs)def vgg13_bn(pretrained=False, progress=True, **kwargs):return _vgg('vgg13_bn', 'B', True, pretrained, progress, **kwargs)# models.vgg16 跳转到这个函数,用_vgg 构造出vgg16
def vgg16(pretrained=False, progress=True, **kwargs):return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)def vgg16_bn(pretrained=False, progress=True, **kwargs):return _vgg('vgg16_bn', 'D', True, pretrained, progress, **kwargs)def vgg19(pretrained=False, progress=True, **kwargs):return _vgg('vgg19', 'E', False, pretrained, progress, **kwargs)def vgg19_bn(pretrained=False, progress=True, **kwargs):return _vgg('vgg19_bn', 'E', True, pretrained, progress, **kwargs)简单模型
# 知乎:VGG16网络原理分析与pytorch实现 https://zhuanlan.zhihu.com/p/87555358import torch
import torch.nn as nnclass NEW_VGG(nn.Module): # nn.Module作为基类 , NEW_VGG 是对其的继承def __init__(self, num_classes):super().__init__()self.num_classes = num_classes# define an empty for Conv_ReLU_MaxPoolnet = []# block 1net.append(nn.Conv2d(in_channels=3, out_channels=64, padding=1, kernel_size=3, stride=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=64, out_channels=64, padding=1, kernel_size=3, stride=1))net.append(nn.ReLU())net.append(nn.MaxPool2d(kernel_size=2, stride=2))# block 2net.append(nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1))net.append(nn.ReLU())net.append(nn.MaxPool2d(kernel_size=2, stride=2))# block 3net.append(nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.MaxPool2d(kernel_size=2, stride=2))# block 4net.append(nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.MaxPool2d(kernel_size=2, stride=2))# block 5net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1, stride=1))net.append(nn.ReLU())net.append(nn.MaxPool2d(kernel_size=2, stride=2))# add net into class propertyself.extract_feature = nn.Sequential(*net)# define an empty container for Linear operationsclassifier = []classifier.append(nn.Linear(in_features=512 * 7 * 7, out_features=4096))classifier.append(nn.ReLU())classifier.append(nn.Dropout(p=0.5))classifier.append(nn.Linear(in_features=4096, out_features=4096))classifier.append(nn.ReLU())classifier.append(nn.Dropout(p=0.5))classifier.append(nn.Linear(in_features=4096, out_features=self.num_classes))# add classifier into class propertyself.classifier = nn.Sequential(*classifier)def forward(self, x):feature = self.extract_feature(x)feature = feature.view(x.size(0), -1)classify_result = self.classifier(feature)return classify_resultif __name__ == "__main__":x = torch.rand(size=(8, 3, 224, 224))vgg = NEW_VGG(num_classes=1000)out = vgg(x)print(out.size())