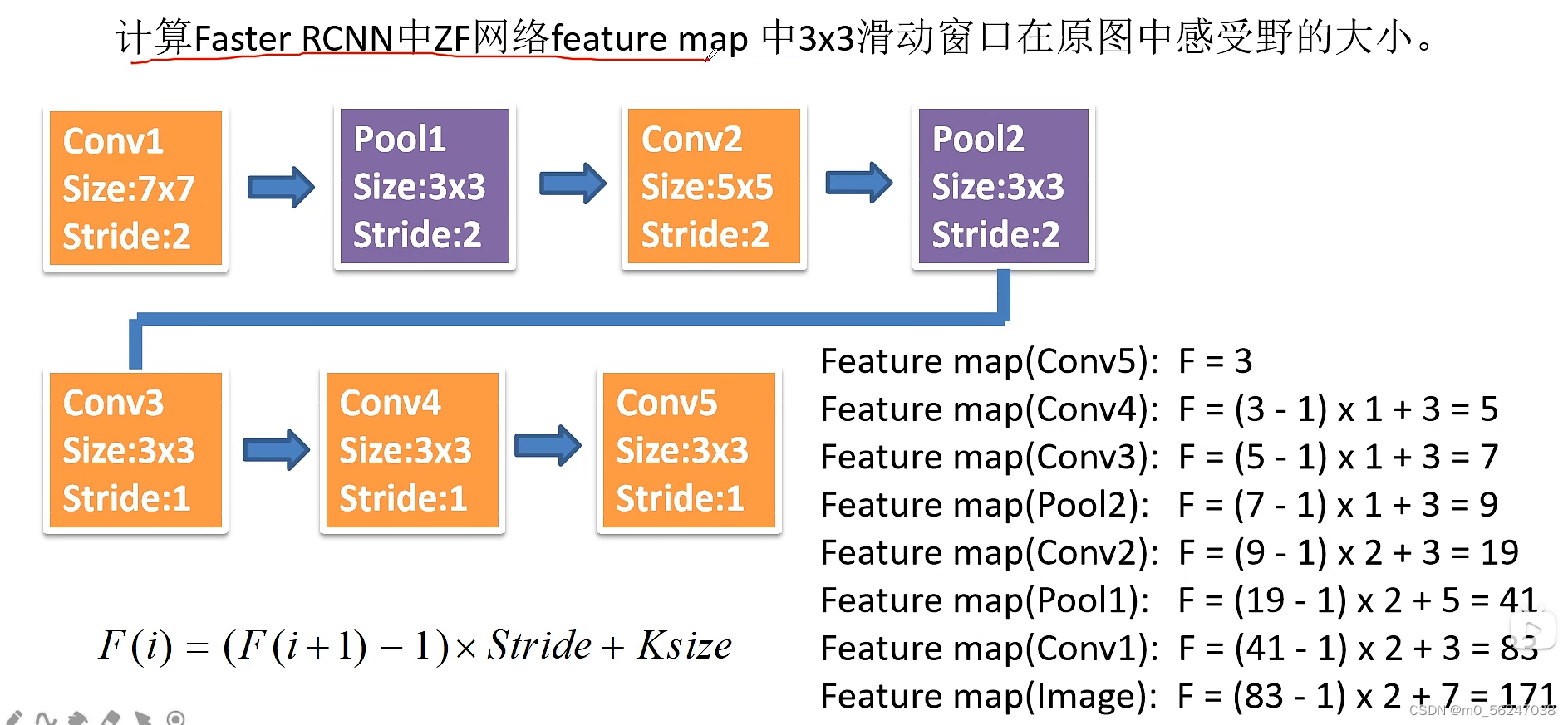
一张图片如何作为输入?
如下图,彩色图像有RGB三个色值通道,分别表示红、绿、蓝,每个通道内的像素可以用一个二维数组表示,数值代表0-255之间的像素值。假设一张900*600的彩色的图片,计算机里面可以用 (900*600*3)的数组表示。
什么是卷积
卷积过程是基于一个小矩阵,也就是卷积核,在上面所说的每层像素矩阵上不断按步长扫过去的,扫到数与卷积核对应位置的数相乘,然后求总和,每扫一次,得到一个值,全部扫完则生成一个新的矩阵。如下图
一般取(3,3)的小矩阵,卷积核里面每个值就是我们需要寻找(训练)的神经元参数(权重),开始会随机有个初始值,当训练网络时,网络会通过后向传播不断更新这些参数值,直到寻找到最佳的参数值。如何知道是“最佳”?是通过损失函数去评估。
卷积核的步长是指卷积核每次移动几个格子,有横行和纵向两个方向。
卷积操作相当于特征提取,卷积核相当于一个过滤器,提取我们需要的特征。
如下图,左边小红色框是卷积核,从左上角扫到右下角,最终得到右边的特征图谱。
什么是Padding(填充)
卷积操作之后维度变少,得到的矩阵比原来矩阵小,这样不好计算,而我们只是希望作卷积,所以我们需要Padding,在每次卷积操作之前,在原矩阵外边补包一层0,可以只在横向补,或只在纵向补,或者四周都补0,从而使得卷积后输出的图像跟输入图像在尺寸上一致。
比如:我们需要做一个300*300的原始矩阵的卷积,用一个3*3卷积核来扫,扫出来结果的矩阵应该是:298*298的矩阵,变小了。
卷积前加Padding 操作补一圈0,即300*300矩阵外面周围加一圈“0”,这样的300*300就变成了302*302的矩阵,再进行卷积出来就是300*300 ,尺寸和原图一样。
什么是池化(pooling)
卷积操作后我们提取了很多特征信息,相邻区域有相似特征信息,可以相互替代的,如果全部保留这些特征信息就会有信息冗余,增加了计算难度,这时候池化就相当于降维操作。池化是在一个小矩阵区域内,取该区域的最大值或平均值来代替该区域,该小矩阵的大小可以在搭建网络的时候自己设置。小矩阵也是从左上角扫到右下角。如下图
什么是Flatten
Flatten 是指将多维的矩阵拉开,变成一维向量来表示。
什么是全连接层
对n-1层和n层而言,n-1层的任意一个节点,都和第n层所有节点有连接。即第n层的每个节点在进行计算的时候,激活函数的输入是n-1层所有节点的加权。
什么是Dropout
dropout是指在网络的训练过程中,按照一定的概率将网络中的神经元丢弃,这样有效防止过拟合。
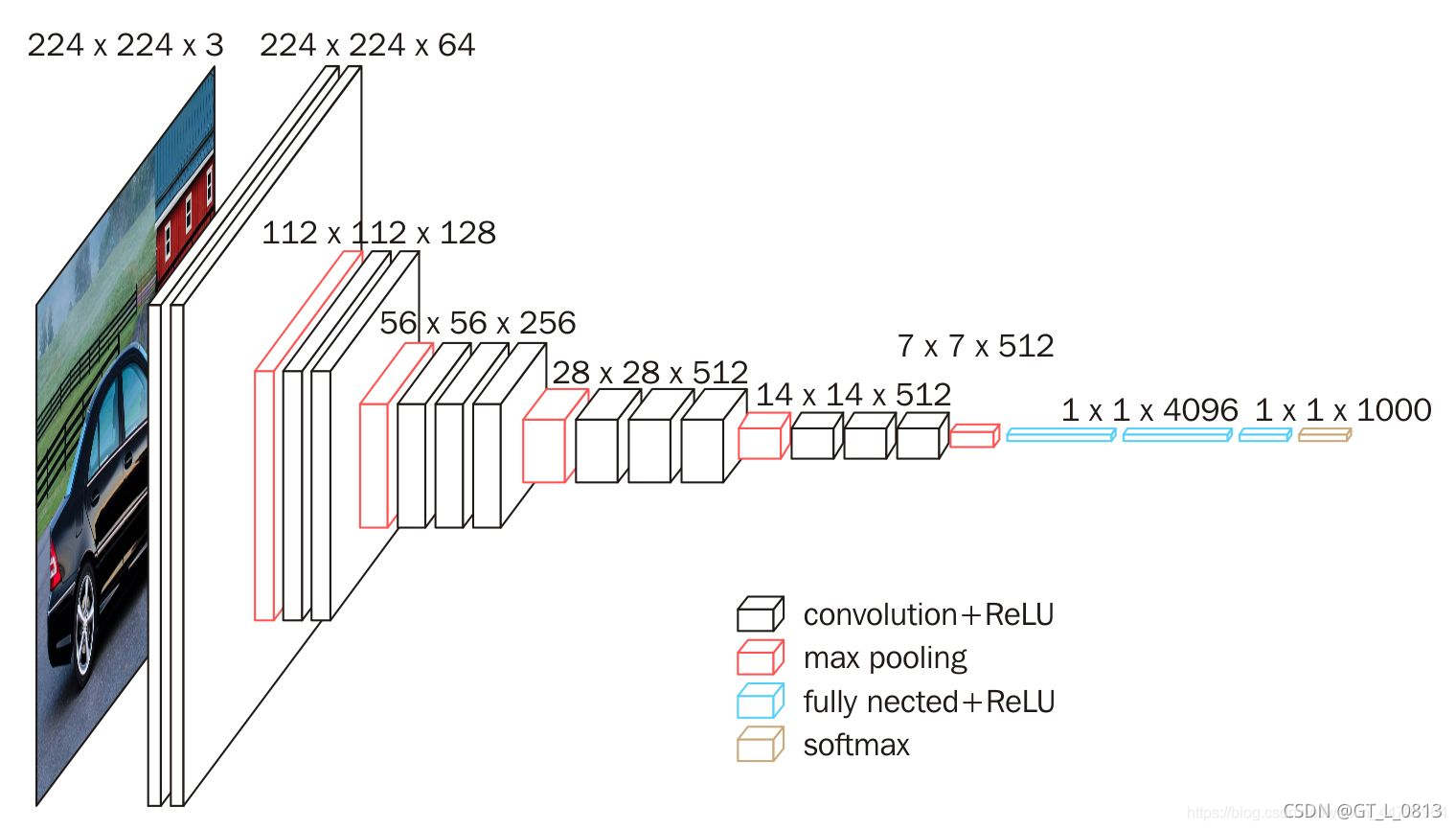
从左至右,一张彩色图片输入到网络,白色框是卷积层,红色是池化,蓝色是全连接层,棕色框是预测层。预测层的作用是将全连接层输出的信息转化为相应的类别概率,而起到分类作用。
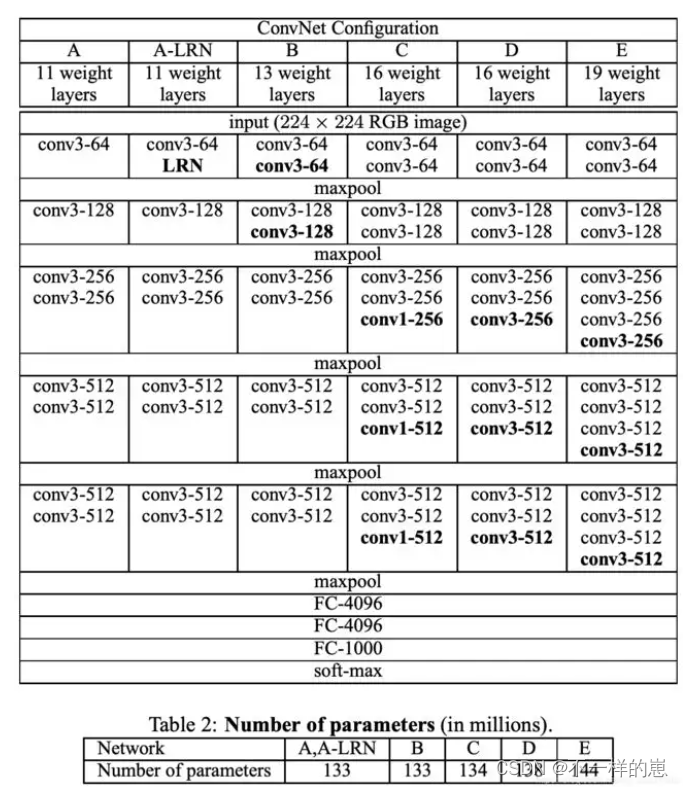
可以看到 VGG16 是13个卷积层+3个全连接层叠加而成。
from keras.models import Sequential
from keras.layers.core import Flatten, Dense, Dropout
from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D
from keras.optimizers import SGD
import cv2, numpy as np#使用keras建立vgg16模型
def VGG_16(weights_path=None):model = Sequential()model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))model.add(Convolution2D(64, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(64, 3, 3, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(128, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(128, 3, 3, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(256, 3, 3, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, 3, 3, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, 3, 3, activation='relu'))model.add(ZeroPadding2D((1,1)))model.add(Convolution2D(512, 3, 3, activation='relu'))model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(Flatten())model.add(Dense(4096, activation='relu'))model.add(Dropout(0.5))model.add(Dense(4096, activation='relu'))model.add(Dropout(0.5))model.add(Dense(1000, activation='softmax'))if weights_path:model.load_weights(weights_path)return modelmodel = VGG_16('vgg16_weights.h5')sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy')#开始来预测
def load_image(imageurl):im = cv2.resize(cv2.imread(imageurl),(224,224)).astype(np.float32)im[:,:,0] -= 103.939im[:,:,1] -= 116.779im[:,:,2] -= 123.68im = im.transpose((2,0,1))im = np.expand_dims(im,axis=0)return im#读取vgg16的类别文件
f = open('synset_words.txt','r')
lines = f.readlines()
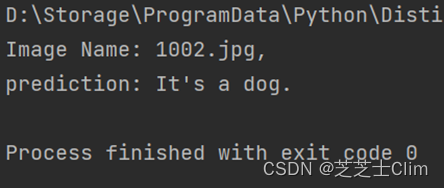
f.close()def predict(url):im = load_image(url)pre = np.argmax(model.predict(im))print lines[pre]
详细解释一下代码
网络开始输入(3,224,224)的图像数据,即一张宽224,高244的彩色RGB图片,同时补了一圈0
ZeroPadding2D((1,1)
这个函数是指在横向和纵向,即四周都补0
接着是卷积层。有64个(3,3)的卷积核,激活函数是relu ,
model.add(Convolution2D(64, 3, 3, activation='relu'))
一个卷积核扫完图片,生成一个新的矩阵,64个就生成64 层。
接着是补0,接着再来一次卷积。此时图像数据是64*224*224
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
接着是池化,小矩阵是(2,2) ,步长(2,2),指的是横向每次移动2格,纵向每次移动2格。
model.add(MaxPooling2D((2,2), strides=(2,2)))
按照这样池化之后,数据变成了64*112*112,矩阵的宽高由原来的224减半,变成了112
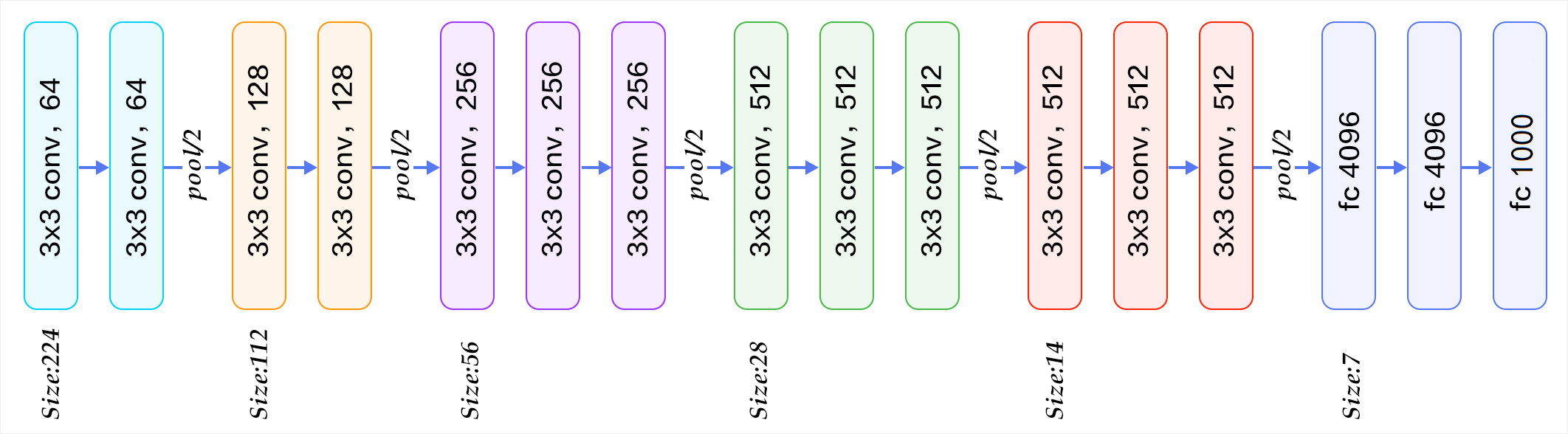
再往下,同理,只不过是卷积核个数依次变成128,256,512,而每次按照这样池化之后,矩阵都要缩小一半。
13层卷积和池化之后,数据变成了 512*7*7
然后Flatten(),将数据拉平成向量,变成一维512*7*7=25088
接着是3个全连接层
这里很少有人解释为什么全连接层里有4096 个神经元,其他数行不行?
其实这里4096只是个经验值,其他数当然可以,试试效果,只要不要小于要预测的类别数,这里要预测的类别有1000种,所以最后预测的全连接有1000个神经元。如果你想用VGG16 给自己的数据作分类任务,这里就需要改成你预测的类别数。
至此VGG16整个网络架构以及数据变化都清楚了。
如果要设计其他类型的CNN网络,就是将这些基本单元比如卷积层个数、全连接个数按自己需要搭配变换,是不是很简单?
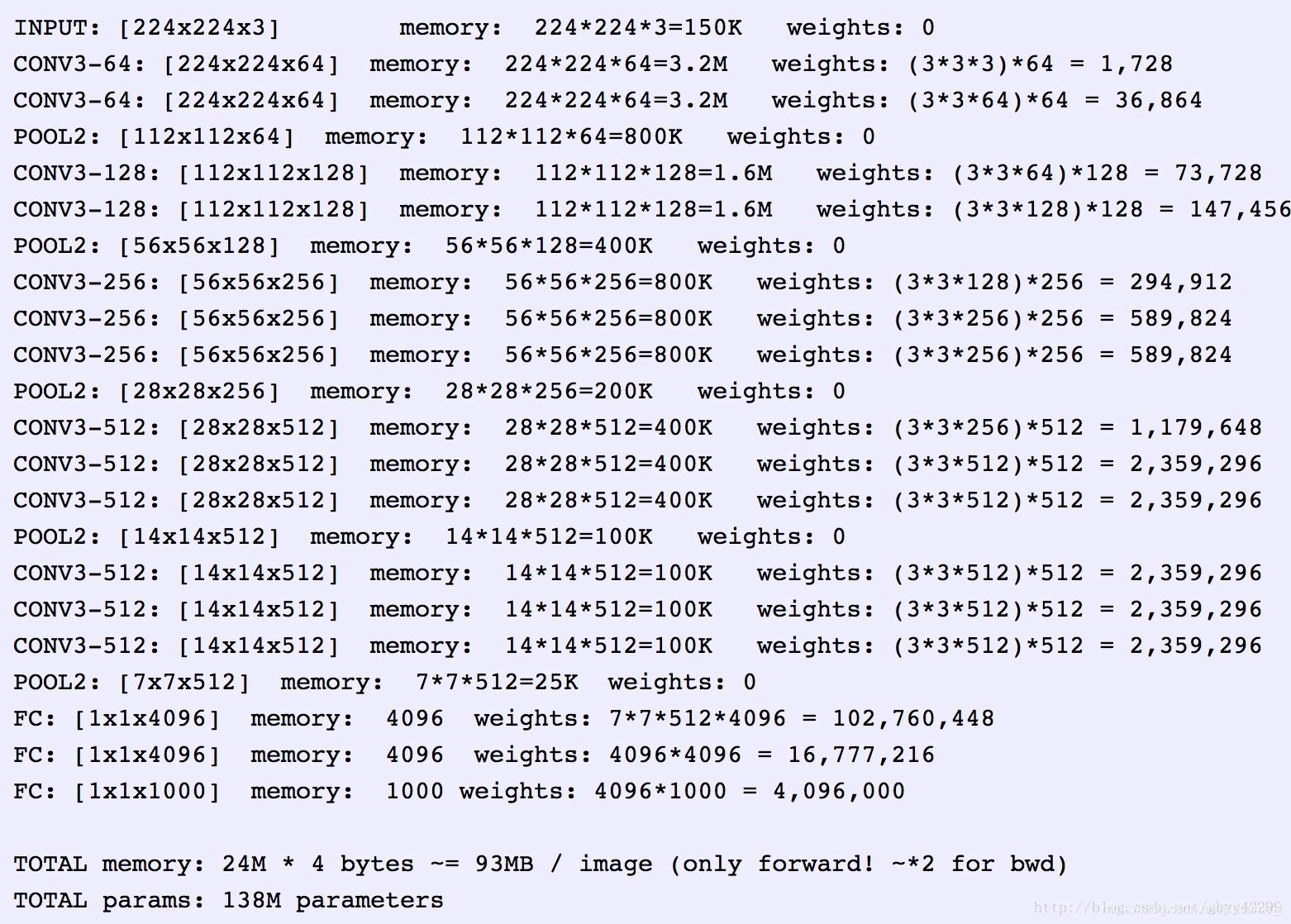
下面我们再来解释一下VGG16里面参数个数如何变化
这里主要看两列数据,一个是memory , 表示的是数据流变化。
一个是weights 表示的是参数变化。作卷积的时候才有参数,即卷积核内的值。全连接的神经元也有参数,一个神经元包含一个权重值。
刚开始是彩色图像3层色值通道,每层64个 (3,3) 的卷积核,所以参数个数是3*64*3*3
第一次卷积之后,数据变成64* 224*224,即有64层宽224,高224的矩阵数据,再次卷积时,还是每层64个 (3,3) 的卷积核,参数个数变成64*64*3*3,往下都是以此类推。
我们看到参数个数最多时达到1600万个,要是更大的图片参数会更多,普通计算机要训练这么庞大的参数会很卡,所以很多人做深度学习的就要求配置GPU 来提高训练速度。
完整代码地址:
关注微信公众号datayx 然后回复“VGG”即可获取。
VGG16 是基于大量真实图像的 ImageNet 图像库预训练的网络
vgg16对应的供keras使用的模型人家已经帮我们训练好,我们将学习好的 VGG16 的权重迁移(transfer)到自己的卷积神经网络上作为网络的初始权重,这样我们自己的网络不用从头开始从大量的数据里面训练,从而提高训练速度。这里的迁移就是平时所说的迁移学习。
对应的模型已经下载好来,可以通过上面的方式获取。
参考链接:https://www.jianshu.com/p/1fdf986dfc21
来源:简书