前言:
CNN系列总结自己学习主流模型的笔记,从手写体的LeNet-5到VGG16再到历年的ImageNet大赛的冠军ResNet50,Inception V3,DenseNet等。重点总结每个网络的设计思想(为了解决什么问题),改进点(是怎么解决这些问题的),并使用keras的两种定义模型的方式Sequential()和Functional式模型实现一遍(加深对模型理解的同时熟悉keras的使用)。
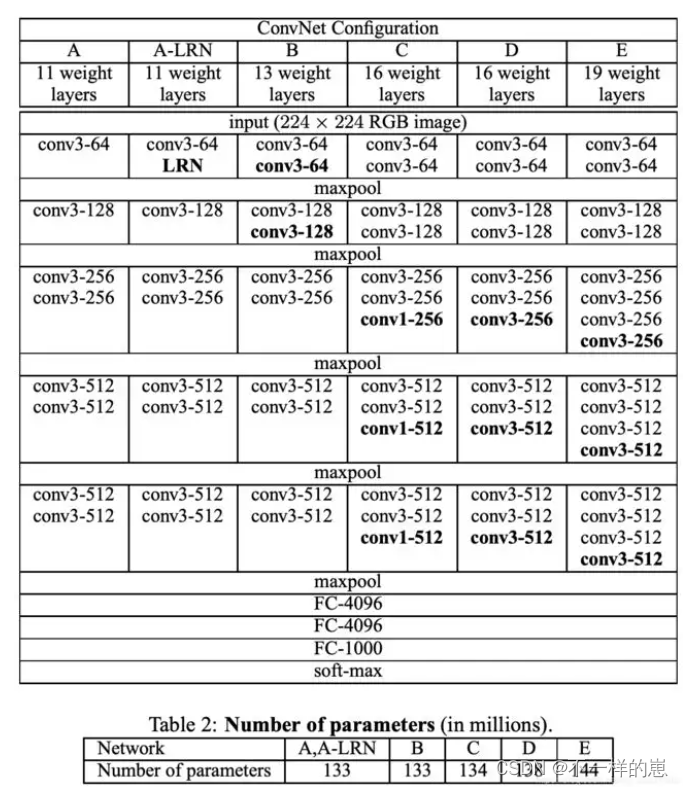
一、VGG16的设计思想
DenseNet论文中有介绍VGG网络遵循以下两个规则:
1)特征图尺寸相同的网络层,这些层产生特征图的通道数也相同。VGG中每个block的特征图尺寸相同,所以每个block中每层的卷积核个数相同
2)如果特征图尺寸减半,则增加一倍的通道数来保证每层的复杂度相同。也就是每下采样一次则卷积核的个数增加一倍。
结构如下图:

VGG网络的具体配置:
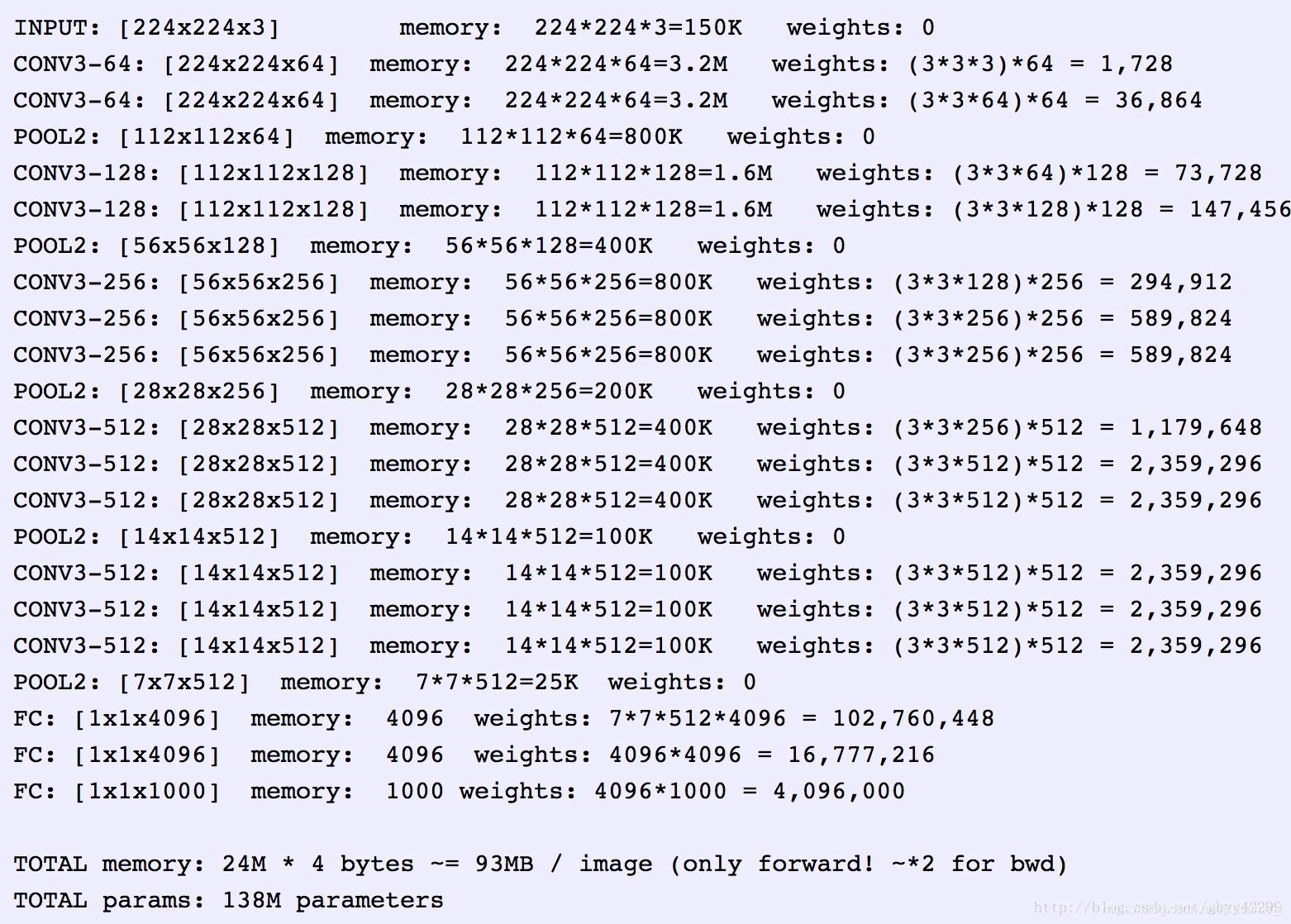
- 输入图像尺寸224x224x3
- 卷积核(滤波器)大小3x3,步长为1,卷积的padding为2(3-1),左右各padding1个像素来确保卷积后特征图大小不变
- 池化层大小2x2,步长为2
- 有两个全连接层,每层4096个神经元(想起来面试的一个问题,为什么CNN后接的全连接层大多是2层,而不是1层,3层?理论上2层的神经网络可以拟合任意函数,1层只能拟合线性函数,多加一层3层参数量会大大提升,会增强4096**2+4096个参数,综合考虑模型性能和参数量,所以一般设置为2层全连接)
- 最后输出层包含1000个神经元的softmax层(代表imagenet数据集的1000个类别)
- 激活函数全部使用ReLU
二、VGG16使用Keras的两种实现方式
1、Sequential()序列式模型实现
-*- coding -*-
'''
created on 2019-7-31 19:35:50@author:fangsh
'''
#%%
import kerasfrom keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Dense,Flatten
from keras.applications import vgg16
'''
序列式模型第一层一定要记得定义input_shape1、
'''
model = Sequential()
#block1
model.add(Conv2D(filters=64,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block1_conv1',input_shape=(224,224,3)))#input_shape只需写图像的shape。不需要加batch的N
model.add(Conv2D(filters=64,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block1_conv2'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2),name='block1_pool'))
#block2
model.add(Conv2D(filters=128,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block2_conv1'))
model.add(Conv2D(filters=128,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block2_conv2'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2),name='block2_pool'))
#block3
model.add(Conv2D(filters=256,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block3_conv1'))
model.add(Conv2D(filters=256,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block3_conv2'))
model.add(Conv2D(filters=256,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block3_conv3'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2),name='block3/pool'))
#block4
model.add(Conv2D(filters=512,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block4_conv1'))
model.add(Conv2D(filters=512,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block4_conv2'))
model.add(Conv2D(filters=512,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block4_conv3'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2),name='block4/pool'))
#block5
model.add(Conv2D(filters=512,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block5_conv1'))
model.add(Conv2D(filters=512,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block5_conv2'))
model.add(Conv2D(filters=512,kernel_size=(3,3),strides=(1,1),padding='same',activation='relu',name='block5_conv3'))
model.add(MaxPool2D(pool_size=(2,2),strides=(2,2),name='block5/pool'))
#fully
model.add(Flatten())
model.add(Dense(units=4096,activation='relu',name='fc1'))
model.add(Dense(units=4096,activation='relu',name='fc2'))
model.add(Dense(units=1000,activation='softmax',name='prediction'))model.summary()
#%%
#读取imageNet的预训练模型参数,来验证定义的是否正确
modelPath = '/data/sfang/vgg16_weights_tf_dim_ordering_tf_kernels.h5'
model.load_weights(modelPath)
2、Functional函数式模型实现
'''
Keras函数式模型使用1、支持定义多输出,多输入模型/Sequential()模型只能定义单个输入单个输出模型2、像连接火车一样
Functional Model三步走:1、定义输入层2、由输出层开始连接其他网络层,上一次的输出是下一次的输入(正常情况下)。3、指定输入tensor和输出tensor定义一个函数式模型
'''
import kerasfrom keras.models import Model
from keras.layers import Dense,Conv2D,MaxPool2D,Flatten,Input
#1、定义输入层
imgInput = Input(shape=(224,224,3),name='input')
#2、依次连接其他层,上一次输出作为下一次输入
#block1
x = Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu',name='block1_conv1')(imgInput)
x = Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu',name='block1_conv2')(x)
x = MaxPool2D(pool_size=(2,2),strides=(2,2),name='block1_pool')(x)
#block2
x = Conv2D(filters=128,kernel_size=(3,3),padding='same',activation='relu',name='block2_conv1')(x)
x = Conv2D(filters=128,kernel_size=(3,3),padding='same',activation='relu',name='block2_conv2')(x)
x = MaxPool2D(pool_size=(2,2),strides=(2,2),name='block2_pool')(x)
#block3
x = Conv2D(filters=256,kernel_size=(3,3),padding='same',activation='relu',name='block3_conv1')(x)
x = Conv2D(filters=256,kernel_size=(3,3),padding='same',activation='relu',name='block3_conv2')(x)
x = Conv2D(filters=256,kernel_size=(3,3),padding='same',activation='relu',name='block3_conv3')(x)
x = MaxPool2D(pool_size=(2,2),strides=(2,2),name='block3_pool')(x)
#block4
x = Conv2D(filters=512,kernel_size=(3,3),padding='same',activation='relu',name='block4_conv1')(x)
x = Conv2D(filters=512,kernel_size=(3,3),padding='same',activation='relu',name='block4_conv2')(x)
x = Conv2D(filters=512,kernel_size=(3,3),padding='same',activation='relu',name='block4_conv3')(x)
x = MaxPool2D(pool_size=(2,2),strides=(2,2),name='block4_pool')(x)
#block5
x = Conv2D(filters=512,kernel_size=(3,3),padding='same',activation='relu',name='block5_conv1')(x)
x = Conv2D(filters=512,kernel_size=(3,3),padding='same',activation='relu',name='block5_conv2')(x)
x = Conv2D(filters=512,kernel_size=(3,3),padding='same',activation='relu',name='block5_conv3')(x)
x = MaxPool2D(pool_size=(2,2),strides=(2,2),name='block5_pool')(x)
#fully conv
x = Flatten()(x)
x = Dense(units=4096,activation='relu',name='fc1')(x)
x = Dense(units=4096,activation='relu',name='fc2')(x)
pred = Dense(units=1000,activation='relu',name='prediction')
functionalModel = Model(inputs=imgInput,outputs=pred)functionalModel.summary()#%%
#读取imageNet的预训练模型参数,来验证定义的是否正确
modelPath = '/data/sfang/vgg16_weights_tf_dim_ordering_tf_kernels.h5'
model.load_weights(modelPath)