目录
一. VGG 网络模型
二. 代码复现
1. 网络搭建
2.数据集制作(pkl)
3.源码地址
一. VGG 网络模型
Alexnet是卷积神经网络的开山之作,但是由于卷积核太大,移动步长大,无填充,所以14年提出的VGG网络解决了这一问题。而且VGG网络结构简单,以 基础卷积和池化组成,非常适合用作CNN的入门学习。 通过卷积,池化 不断将图片 的尺寸减小, 维度升高, 提取特征。
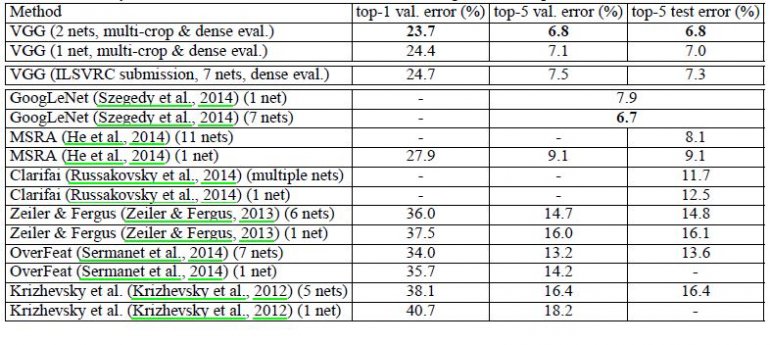
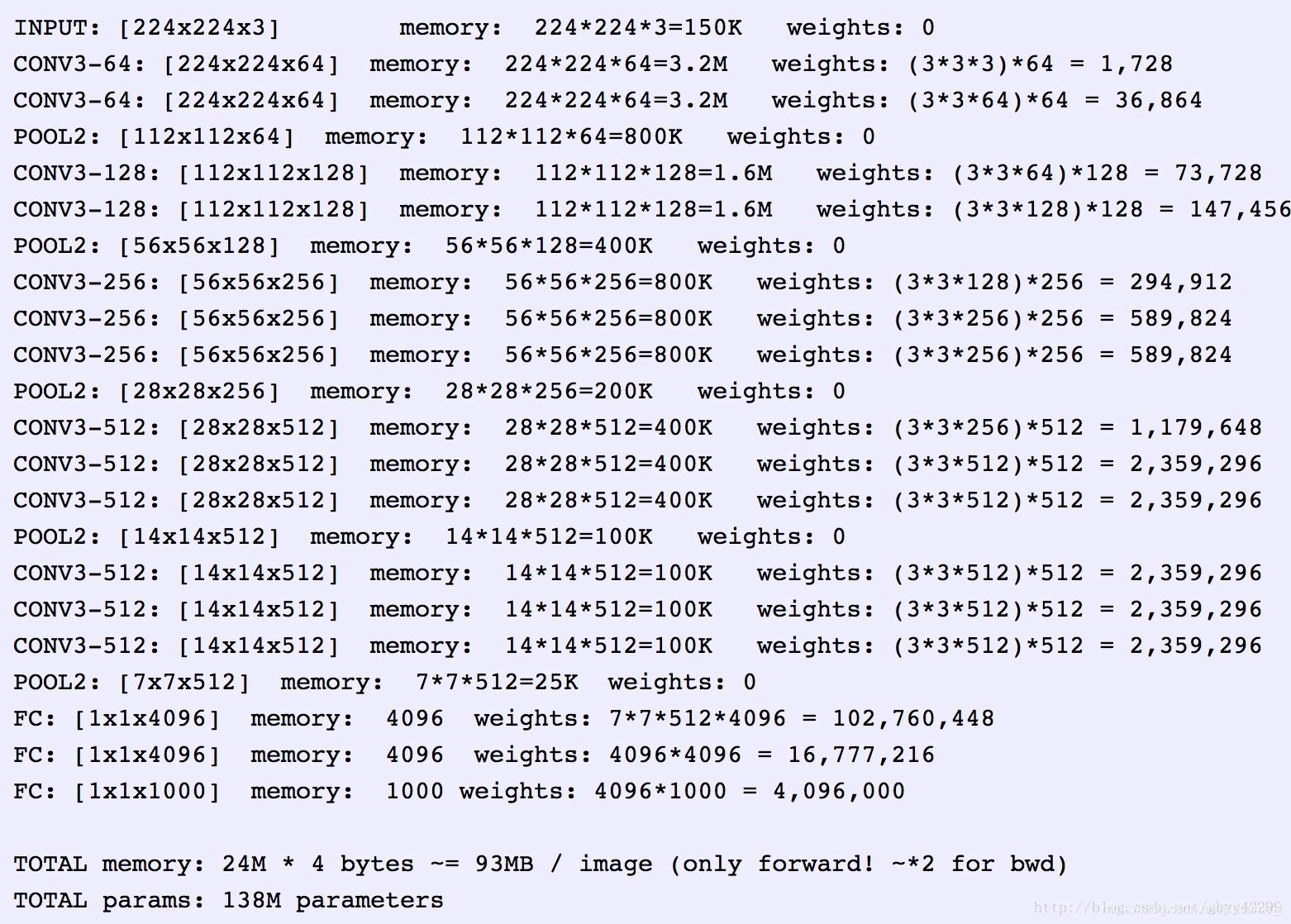
VGG的主要贡献是全面评估网络的深度,使用3*3卷积滤波器来提取特征。解决了Alexnet容易忽略小部分的特征。目前常用的有VGG13\VGG16网络,本文实例部分以VGG16为例。VGG模型如下:
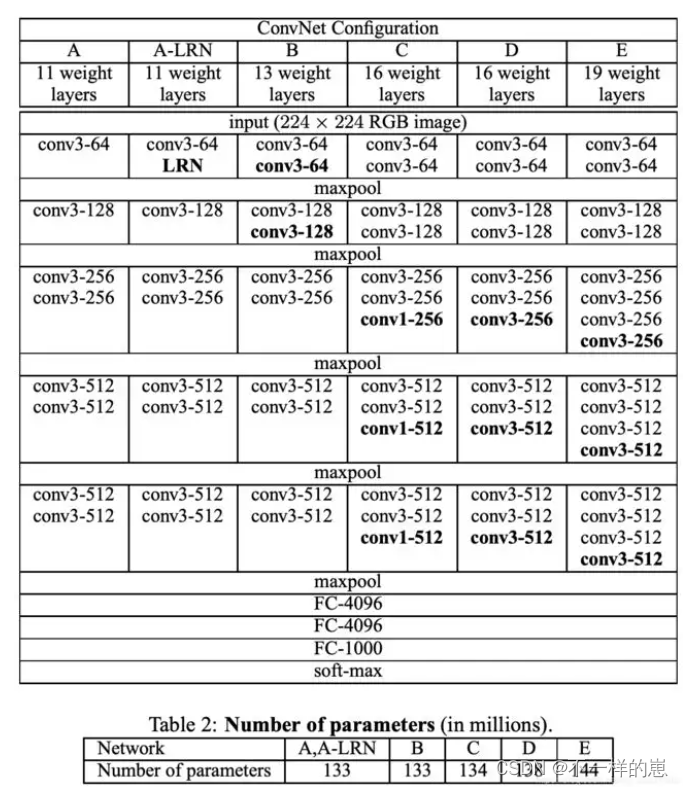
如图所示,一共列出了VGG11、VGG13、VGG16、VGG19等6种VGG模型, 以VGG16为例, 因为其具有16个网络层,主要注意的是这其中不包括pooling(池化层)如maxpool,avgpool等,本文以上图中的VGG16(第D列)为例进行讲解。
二. 代码复现
1. 网络搭建
以上图中的(D列)VGG16为例, 构建模型, train.py训练代码如下,其中模型搭建如network = Sequential所示。
import tensorflow as tf
import numpy as np
import os
import cv2
from tensorflow.keras import layers, optimizers, datasets, Sequential
import sys
from six.moves import cPickle# 调用 GPU
gpu = tf.config.experimental.list_physical_devices('GPU')
if len(gpu) > 0:tf.config.experimental.set_memory_growth(gpu[0], True)def main():######第一步,train, test # 加载数据# batchsize 指每次 用作训练样本数, 比如训练样本总数为10000, 其中 训练集 8000张 验证集2000# Train_batchsize = 80 ,则说明将所有数据训练一轮需要 8000/80 = 100 步 (step = 100) 也称一轮训练迭代100次# 训练时 还有一个参数 epoch, 表示整个训练 需要轮几次, 如epoch = 100 , 则表示 需要将整个 数据集训练100轮# 则整个训练 需要 迭代 epoch * (8000/Train_batchsize) = 10000 次Train_batchsize = 80val_batchsize = 50# 加载 训练集 和 验证集, # x -> 训练用图片数据 x_val -> 验证用图片数据 # y -> 训练用图片标签 y_val -> 验证用图片标签(x, y), (x_val, y_val) = Cap_load_data()# 将标签 进行维度 调整 [n, 1] => [n]y = tf.squeeze(y, axis=1) # [n, 1] => [n]y_val = tf.squeeze(y_val, axis=1) # [n, 1] => [n]# 将数据进行打乱,并进行切片train_db = tf.data.Dataset.from_tensor_slices((x, y))train_db = train_db.shuffle(1000).map(preprocess).batch(Train_batchsize).repeat()val_db = tf.data.Dataset.from_tensor_slices((x_val, y_val))val_db = val_db.shuffle(500).map(preprocess).batch(val_batchsize).repeat()# 验证存储的pkl数据是否和 实际图片的一致# print(x.shape,y.shape,x_val.shape,y_val.shape)# print(x[0,0,0,:])## src = cv2.imread(r"XXX.jpg")# src = cv2.resize(src, (64, 64))# src = cv2.cvtColor(src, cv2.COLOR_BGR2RGB) # 因为cv2.imread opencv中默认颜色通道为BGR# print(src[0,0,:])######第二步,创建模型# 卷积层取特征# maxpool层强化特征并且把图片尺寸减小一半# 这里如果还是两层conv2d就会无法收敛network = Sequential([ # 64x64layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.MaxPool2D([2, 2]), #layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.MaxPool2D([2, 2]), #32x32,# layers.MaxPool2D([2, 2]),#16x16,layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.MaxPool2D([2, 2]),layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.MaxPool2D([2, 2]),layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.Conv2D(512, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),layers.MaxPool2D([2, 2]),# 转换形状# layers.Reshape((-1, 512), input_shape=(-1, 1, 1, 512)), # 这里加一个 Reshape层就好啦layers.Flatten(),layers.Dense(256, activation=tf.nn.relu),layers.Dense(128, activation=tf.nn.relu),layers.Dense(1, activation=tf.nn.sigmoid),])network.build(input_shape=[None, 64, 64, 3])network.summary()#####第三步,训练参数配置# 用 keras 的高层API直接训练# network.compile(# optimizer=optimizers.Adam(lr=1e-4),# loss=tf.losses.categorical_crossentropy, # MSE 是个对象, CategoricalCrossentropy 是个类# metrics=['accuracy']# )# network.compile(optimizer='adam',# loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),# metrics=['accuracy'])network.compile(optimizer='rmsprop',loss=tf.losses.binary_crossentropy,metrics=['accuracy'])#####第四步,训练network.fit(train_db, epochs=20, verbose=2, steps_per_epoch=x.shape[0]//Train_batchsize, validation_steps=x_val.shape[0]//val_batchsize, validation_data=val_db, validation_freq=1)# .fit的verbose 输出日志模式network.save('XXX.h5')def preprocess(x, y): # 数据集处理 把data 和 label 都设置为float型x = tf.cast(x, dtype=tf.float32) / 255.y = tf.cast(y, dtype=tf.int32)return x, ydef Cap_load_data():# path = r'XXXXX'path = r'XXXXXX' # Data1 在Data基础上加了更多的小电容fpath = os.path.join(path, 'train.pkl')x_train, y_train = load_batch(fpath)fpath = os.path.join(path, 'test.pkl')x_val, y_val = load_batch(fpath)y_train = np.reshape(y_train, (len(y_train), 1)) #标签y_val = np.reshape(y_val, (len(y_val), 1))# if K.image_data_format() == 'channels_last':# x_train = x_train.transpose(0, 2, 3, 1)# x_val = x_val.transpose(0, 2, 3, 1)return (x_train, y_train), (x_val, y_val)def load_batch(fpath): # 使用cpick 读取文件# with open(fpath, 'rb') as f:# if sys.version_info < (3,):# d = cPickle.load(f)# else:# d = cPickle.load(f, encoding='bytes')# # decode utf8# d_decoded = {}# for k, v in d.items():# d_decoded[k.decode('utf8')] = v# d = d_decodedwith open(fpath, 'rb') as f:d = cPickle.load(f, encoding='bytes')data = d['data']labels = d['labels']data = data.reshape(data.shape[0], 64, 64, 3)return data, labelsif __name__ == "__main__":main()2.数据集制作(pkl)
import tensorflow as tf
import numpy as np
import cv2
import os
import sys
from six.moves import cPickledef main():pklPath = r"XXX.pkl"input_size = (64, 64)data_oneDim = input_size[0] * input_size[1] * 3# 测试集图片的张数num_trainImage = 4000data = np.array([[0 for x in range(data_oneDim)] for y in range(num_trainImage)])# 就本数据集而言,二分类,正反样例各占50% , 所以每种类设置数量为 num_trainImage/2 标签label1 = [0 for x in range(int(num_trainImage/2))]label2 = [1 for x in range(int(num_trainImage/2))]label = np.array(label1 + label2)# 上下各2000张 每张64*64 3通道# 64*64*3 = 12288 4000*12288 的 numpy的uint8s数组ImageFile1 = r"XXX" + "\\"ImageNames1 = os.listdir(ImageFile1)i = 0for Name1 in ImageNames1:imagePath = ImageFile1 + Name1src = cv2.imread(imagePath)src = cv2.resize(src, (64, 64))src = cv2.cvtColor(src,cv2.COLOR_BGR2RGB) # 因为cv2.imread opencv中默认颜色通道为BGR# src_data = np.array([src[:,:,0],src[:,:,1],src[:,:,2]])src_data = np.array(src)src_data = src_data.reshape(12288)data[i] = src_datai = i + 1# print(src[0,:,0]) 测试输出 转化后的src_data 第一行的 r 分量是否 和src一致# print(src_data[:64])# print(src.shape)# print(src_data.shape)ImageFile2 = r"XXX" + "\\"ImageNames2 = os.listdir(ImageFile2)for Name2 in ImageNames2:imagePath = ImageFile2 + Name2src = cv2.imread(imagePath)src = cv2.resize(src, input_size)src = cv2.cvtColor(src,cv2.COLOR_BGR2RGB) # 因为cv2.imread opencv中默认颜色通道为BGR# src_data = np.array([src[:,:,0],src[:,:,1],src[:,:,2]])src_data = np.array(src)src_data = src_data.reshape(data_oneDim)data[i] = src_datai = i + 1Cap_dict = { 'data': data , 'labels':label }print(Cap_dict['data'].shape)with open(pklPath,'wb') as f:cPickle.dump(Cap_dict,f)if __name__ == "__main__":main()3.源码地址
https://github.com/mcuwangzaiacm/VGG16_tensorflow2.0