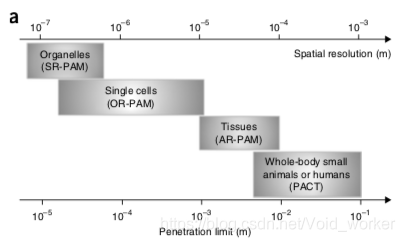
在相关论文中,提到一种使用光声前向模型来求取输入信号,根据公式![]() ,其中A为论文《Acceleration of Optoacoustic Model-Based Reconstruction Using Angular Image Discretization》提出的模型矩阵。P为从ROI中像素位置所吸收的能量计算一组瞬时和一组换能器位置的理论压力。A作为模型矩阵取决于光声装置的几何形状和介质中的声速。 H为以矢量形式表示的重建图像。
,其中A为论文《Acceleration of Optoacoustic Model-Based Reconstruction Using Angular Image Discretization》提出的模型矩阵。P为从ROI中像素位置所吸收的能量计算一组瞬时和一组换能器位置的理论压力。A作为模型矩阵取决于光声装置的几何形状和介质中的声速。 H为以矢量形式表示的重建图像。
将测量的声信号与由特定的光声正演模型所预测的理论信号之间的误差数值最小化。在此类基于模型的方案中,需要兼顾精度和计算时间的权衡。近年来,一种快速、准确的基于半解析模型的光声重建方案——插值模型矩阵反演(IMMI)被引入到光声重建。它是基于一组位置和时间瞬时测量的压力值与理论预测的压力分布之间的均方差最小化,压力分布是从重建图像中的吸收能量分布计算出来的。因此,理论压力表示为模型矩阵和对应于图像像素位置吸收能量的列向量乘积。
模型矩阵的计算涉及到给的那个类型插值的解析解的广泛计算。基于模型的光声重建方法包括两个步骤,即首先计算模型矩阵,然后进行反演。开发一种快速计算模型矩阵的方法以实现快速重建具有重要的意义。
该论文介绍了一种加速光声重建的新方法,基于前向模型解的角度图像离散化(Angular image discretization)。和上述论述相关的,基于公式![]() ,通过最小化理论压力与实测压力
,通过最小化理论压力与实测压力![]() 的均方差进行光声重建。相关表达式为
的均方差进行光声重建。相关表达式为![]() 。利用模型矩阵的稀疏性和LSQR算法实现快速重建。原则上,在投影角度足够的情况下,可以利用上式进行全视图采集。
。利用模型矩阵的稀疏性和LSQR算法实现快速重建。原则上,在投影角度足够的情况下,可以利用上式进行全视图采集。
在光声成像中,光源通常是一个短纳秒的激光脉冲,满足热约束条件,即热导可以忽略。这样,局部热膨胀不受邻近区域的影响。在这种情况下,光源的时间剖面可以近似为狄拉克![]() ,在均匀声介质中产生的超声波引起的压力由:
,在均匀声介质中产生的超声波引起的压力由:
![]()
其中, ![]() 是介质中的声速,
是介质中的声速, ![]() 是无量纲的格卢尼森系数,
是无量纲的格卢尼森系数, ![]() 是组织中单位体积吸收的能量,其中
是组织中单位体积吸收的能量,其中 ![]() 是光吸收系数,
是光吸收系数,![]() 是光通量。上式可以转化为带初值的齐次方程问题:
是光通量。上式可以转化为带初值的齐次方程问题:
![]()
初始条件为:
![]()
(2)和(3)中初值问题的解析解由泊松型积分给出:
![]()
其中,![]() 是一个与时间相关的球面
是一个与时间相关的球面![]() 。如果只是需要压力单位的时间剖面图,则可以忽略(4)中导数之外的常数项。此外,如果声源位于平面内,(4)可以简化为二维几何体,在圆周上积分
。如果只是需要压力单位的时间剖面图,则可以忽略(4)中导数之外的常数项。此外,如果声源位于平面内,(4)可以简化为二维几何体,在圆周上积分![]() ,
,![]() 。在上述情况下,以任意单位表示的压力如下:
。在上述情况下,以任意单位表示的压力如下:

上述近似值需要澄清。一般来说,光声源并不局限于一个平面内。在实际应用中,声源的位置取决于用于采集光声信号的传感器的光通量分布和灵敏度场。因此,在许多实际情况下,可以有效地将检测几何体缩减为二维。例如,当用一片光照射非散射物体或用圆柱形聚焦超声换能器检测响应来感应光声信号时。
另一方面,音速恒定的假设可能变得不准确。特别是,声音在生物组织中的传播速度与水中的声音传播速度相比可以相差10%,如果在重建算法中不考虑这种影响,可能会导致图像失真。对于10%左右的音速变化,主要失真是光声信号的时间偏移,这可以通过计算飞行时间来描述。
![]()
![]() 对应于沿直线的点的位置。考虑信号的编译,公式(5)可以描述为:
对应于沿直线的点的位置。考虑信号的编译,公式(5)可以描述为:

![]() 是一条曲线,验证其任何点与(6)中定义的传感器位置之间的飞行时间等于
是一条曲线,验证其任何点与(6)中定义的传感器位置之间的飞行时间等于![]() ,假设声波传播时,声波波前没有弯曲,超声波的传播可以建模为直线声射线。然后在声速均匀的情况下修改积分曲线。
,假设声波传播时,声波波前没有弯曲,超声波的传播可以建模为直线声射线。然后在声速均匀的情况下修改积分曲线。
IMMI重建算法基于一组位置和时间点测量的压力与理论计算压力之间的均方差最小化来完成图像重建。理论计算压力基于公式(5)的模型估计在ROI区域中像素的位置相对应的点网格处吸收的能量函数。特别地,通过将重建平面平铺成直角三角形并在每个三角形内执行线性插值,可以估计任意点的吸收能量。因此,得到的连续函数是分段平面的,因此可以考虑此插值函数计算(5)的解析解。虽然也可以获得使用不同类型插值获得的连续函数(5)的解析解,但该模型可能会变得相当繁琐,并且其计算实现具有挑战性。
在这项工作中,基于(5)的方便离散化,提出了一种不同的方法。在第一步中,使用了时间导数的数值近似,因此(5)通过:
![]()
其中,![]() 表示为:
表示为:
 公式(9)的离散化是通过一组点逼近曲线来实现的,其位置由穿过传感器位置且具有相等间隔角度的直线来确定。这组直线涵盖了一个从传感器位置开始的角度,因此离散曲线的段集
公式(9)的离散化是通过一组点逼近曲线来实现的,其位置由穿过传感器位置且具有相等间隔角度的直线来确定。这组直线涵盖了一个从传感器位置开始的角度,因此离散曲线的段集![]() 覆盖整个插值后
覆盖整个插值后![]() 的二维空间(图中空心圆内部的区域,其中实心圆指示ROI中像素的位置)。因此,对于圆形扫描几何体,其中从传感器到ROI中心的距离是相同的,与传感器的角度位置无关,因此,对于传感器的任何瞬间和位置,上述条件都得到验证。
的二维空间(图中空心圆内部的区域,其中实心圆指示ROI中像素的位置)。因此,对于圆形扫描几何体,其中从传感器到ROI中心的距离是相同的,与传感器的角度位置无关,因此,对于传感器的任何瞬间和位置,上述条件都得到验证。
计算如下:
![]()
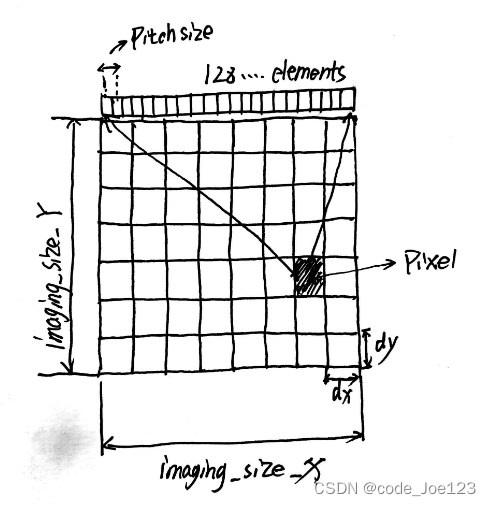
其中![]() 为ROI水平和垂直方向的像素数,
为ROI水平和垂直方向的像素数,![]() 是像素尺寸。与计算传感器每个时刻和位置的曲线与ROI的交点相比,通过考虑
是像素尺寸。与计算传感器每个时刻和位置的曲线与ROI的交点相比,通过考虑![]() 为常数,算法的实现变得更容易。
为常数,算法的实现变得更容易。

然后从曲线的![]() 个离散点(图1中的三角形)计算积分,如下所示:
个离散点(图1中的三角形)计算积分,如下所示:
 或者等价为:
或者等价为:

在上式中,![]() 。通过插值的方法从ROI中像素位置的
。通过插值的方法从ROI中像素位置的![]() 来估算
来估算![]() 的值。之后,
的值。之后,
![]()
![]() 是ROI中的总像素数。系数
是ROI中的总像素数。系数![]() 的值取决于采用的插值方式。该文建议的方法的一个重要优点是,它可以通过不同类型的插值轻松实现。这项工作中,其考虑了两种不同的类型,即[8]中描述的直角三角形内的线性插值和双线性插值。在这两种情况下,给定点
的值取决于采用的插值方式。该文建议的方法的一个重要优点是,它可以通过不同类型的插值轻松实现。这项工作中,其考虑了两种不同的类型,即[8]中描述的直角三角形内的线性插值和双线性插值。在这两种情况下,给定点![]() 处的
处的![]() 的值由四个相邻像素处的
的值由四个相邻像素处的![]() 值给出,如图2所示
值给出,如图2所示

然后,考虑直角三角形内的线性插值时,![]() 由下式计算:
由下式计算:

其中,![]() 。使用双线性插值时,
。使用双线性插值时, ![]() 由下式计算:
由下式计算:

这项工作中引入的离散化的另一个重要优点是,通过计算修改曲线![]() 的一组点,它可以很容易地适用于优先了解介质中声速分布的情况。为此,考虑了同一组直线,同时为音速变化区域内的每条直线定义了一组由
的一组点,它可以很容易地适用于优先了解介质中声速分布的情况。为此,考虑了同一组直线,同时为音速变化区域内的每条直线定义了一组由![]() 距离分隔的等距点。对于圆形扫描几何体,我们假设该区域被限制在覆盖该区域的圆内,该区域
距离分隔的等距点。对于圆形扫描几何体,我们假设该区域被限制在覆盖该区域的圆内,该区域![]() ,如图3所示。然后定义一组等间距点,覆盖该区域(空心圆图3)。这些点的飞行时间通过应用(6)中积分的梯形近似来估计,如下所示:
,如图3所示。然后定义一组等间距点,覆盖该区域(空心圆图3)。这些点的飞行时间通过应用(6)中积分的梯形近似来估计,如下所示:
![]()
![]() 为沿波传播路径的点的位置。随后,通过使用(16)计算的飞行时间值进行线性插值,获得给定飞行时间和给定直线的曲线点位置。一旦曲线的一组点,(12)中定义的积分,被获得,获得系数
为沿波传播路径的点的位置。随后,通过使用(16)计算的飞行时间值进行线性插值,获得给定飞行时间和给定直线的曲线点位置。一旦曲线的一组点,(12)中定义的积分,被获得,获得系数![]() 的步骤与上述相同。
的步骤与上述相同。

然后可以计算(13)中定义的传感器位置和瞬时的理论压力,这样就可以建立一个线性方程组,用矩阵形式表示为:
![]() 根据上述思路,根据图像的像素值进行插值求和,可以还原出对应的光声信号,其中一个换能器的各信号点所涉及的位置由该换能器所处的位置、飞行时间的影响。
根据上述思路,根据图像的像素值进行插值求和,可以还原出对应的光声信号,其中一个换能器的各信号点所涉及的位置由该换能器所处的位置、飞行时间的影响。