实验名称:前置微小信号放大器在光声技术的血管识别研究中的应用
研究方向:生物识别技术
测试目的:
利用MATLAB对光声血管进行识别:1、对光声血管图库的图像进行预处理包括归一化、二值化、平滑、细化和毛刺修剪得到细化图像;2、利用七个不变矩提取细化血管图像的特征值建立数据集;3、利用SVM对血管图片进行识别,证实基于光声的血管图像识别的可行性。
测试设备:ATA-5620微弱信号放大器、固体激光器、超声换能器、机械位移平台、示波器、滤波器、微弱信号放大器和计算机、数据采集卡
实验过程:
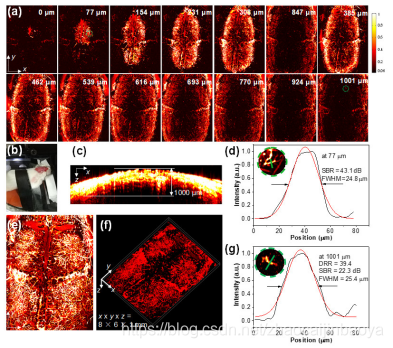
通过测试设备搭建固体激光器的OR-PAM系统,采用光学参量振荡器(OPO)(OPOletteTM532,OpotekLLC)作为光源:波长、脉冲频率和脉冲持续时间分别为532nm、20Hz和7ns,激光的输出功率是由计算机控制的。OPO激光器输出光束经空间衰减和整形后,由定制的光纤耦合器耦合在光纤上。光纤的输出组件连接到光学透镜筒。光学透镜筒内包括一个焦距为30mm的光纤准直器和一个焦距为5mm的聚焦透镜。光斑直径约为20um,适用于较大直径的主血管成像,而较小直径的旁侧血管在后续图像预处理中被过滤除。随后,光学透镜通过固定装置安装在三维机械位移平台上进行扫描。信号由中心频率为2.5MHz的非聚焦超声接收器获取。使用微弱信号放大器ATA-5620对声信号进行增益,信号可被放大~60dB。使用多功能数据采集卡对模拟型号进行转换并采集,而后由个人计算机进行数字化处理。样品平台由位移平台和超声换能器组成。
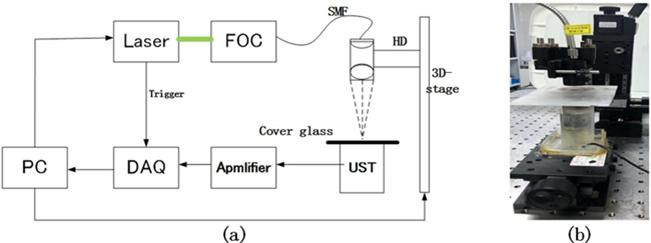
图:(a)光声血管采集系统结构示意;(b)光声成像系统
实验的时候先准备40个假血管作为样品,对血管样品进行光声检测,从光声信号的幅值、速度和信号的最大值到达时间的差值进行防伪,区分出伪造的血管。而后对符合光声特征的样品(即判定为真血管的样品)进行光声成像,并建立图库。接着对经过图像预处理的光声血管进行细化、特征匹配。最后将特征向量集作为数据集输入SVM进行分类识别。
实验结果:
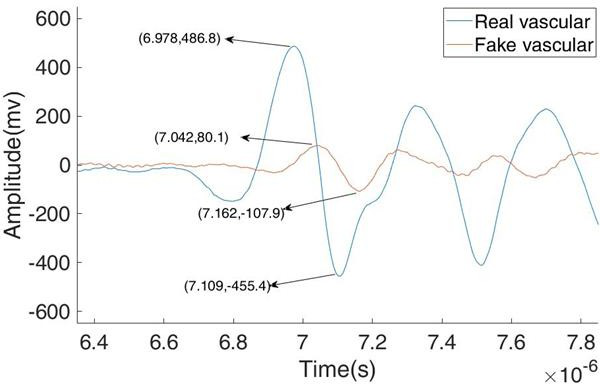
图:真假血管图像的光声信号
1、振幅
将光声信号作为检测参数的峰峰值进行比较,图上显示出在相同能量下的假血管和真实脉管系统的光声信号,其中假血管幅度远小于真实血管。
2、深度
检测目标的深度:深度=最大到达时间×超声速度之间的差。在实验过程中,激光源、样品和超声换能器的相对位置不变。
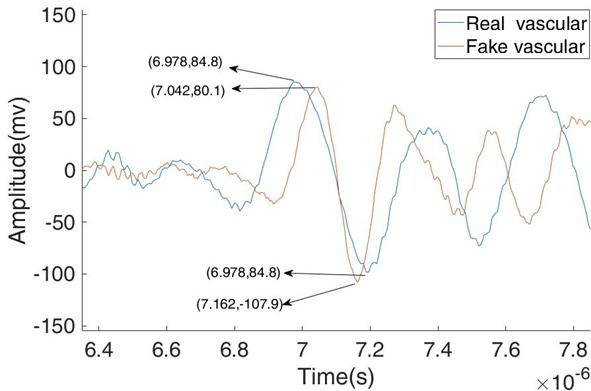
图:使用折射率板后脉管系统的光声信号
通过折射率板改变了激光束的最终能量之后,真实血管信号发生改变。真实和虚假血管信号的峰峰值分别为182.9mV和188mV。假血管图像和真实血管图像的峰峰值之间的误差仅为(188-182.9)/182.9≈2.79%,从物理角度上看可以忽略不计。假血管信号的最大到达时间为7.042µs。
3、光声血管识别
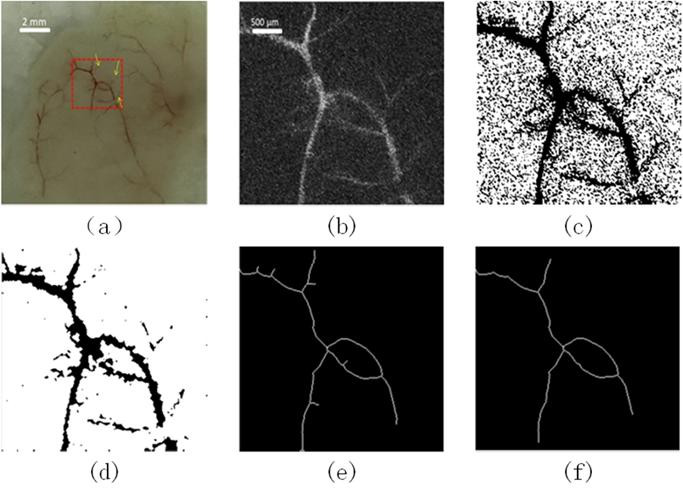
图:真实的血管图像
图(a–f)分别显示了真实的血管图像,归一化(按大小和灰度)、二值化、平滑、细化和毛刺修剪的血管图像。提取每个血管图像的特征形成数据集。
该数据集包含10只大鼠的160张血管图像,其中80张图片用作训练集,其余图片用作测试集,血管识别的结果示于表3。其使用SVM的方法,识别率达到97.5%。因此,本系统的实际识别率为97.5%。与直接使用SVM获得的结果相比,它可以将真假血管的识别率提高2.63%((97、5%-95%)/95%),血管识别系统的识别率大大提高。
安泰ATA-5620功率放大器的指标参数:

图:前置信号放大器ATA-5620参数