👨🎓个人主页:研学社的博客
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码及文章讲解

💥1 概述
文献来源:

定量光声断层扫描的目标是确定光学和 从初始压力图获得的声学材料属性,用于 例如,来自光声成像。最相关的参数是 吸收、扩散和格鲁尼森系数,所有这些都可以是 异质。Bal和Ren最近的研究表明,总的来说,独特的 所有三个参数的重建是不可能的,即使多个 初始压力的测量(对应于不同的激光 提供单波长的激发方向。
在这里,我们提出了对分段常数材料参数的限制。我们 表明在光传递的扩散近似中,分段常数 吸收、扩散和格吕奈森系数可以独特地回收 来自单个波长的光声测量。此外,我们 以数字方式实现了我们的想法,并在模拟上对其进行了测试 三维数据。
原文摘要:
The goal of quantitative photoacoustic tomography is to determine optical and acoustical material properties from initial pressure maps as obtained, for instance, from photoacoustic imaging. The most relevant parameters are absorption, diffusion and Grueneisen coefficients, all of which can be heterogeneous. Recent work by Bal and Ren shows that in general, unique reconstruction of all three parameters is impossible, even if multiple measurements of the initial pressure (corresponding to different laser excitation directions at a single wavelength) are available.
Here, we propose a restriction to piecewise constant material parameters. We show that in the diffusion approximation of light transfer, piecewise constant absorption, diffusion and Grüneisen coefficients can be recovered uniquely from photoacoustic measurements at a single wavelength. In addition, we implemented our ideas numerically and tested them on simulated three-dimensional data.
Canny边缘检测器包括三个步骤:
1)使用高斯卷积滤波器对数据进行去噪。
2) 通过计算图像梯度幅度的最大值来获取边缘集的候选者。这是通过查找某个函数的零级集(包含数据的二阶导数)来实现的。
3)执行滞后阈值。首先,删除梯度幅度(边缘强度)低于下限阈值的边缘集的所有部分。然后,删除梯度幅度永远不会超过上限阈值的边缘集的所有连接分量。
光声层析成像(PAT)是一种利用激光激发与超声测量耦合的混合成像技术。由短单色激光脉冲照射的组织产生超声信号(由于热膨胀),该信号可由介质外的超声换能器测量。从这些测量中,超声波的初始压力(其空间变化取决于组织的材料特性)可以通过求解波动方程的反问题来唯一地重建。有关此逆问题的进一步信息,请参见Kuchment和Kunyansky[23]。
获得的超声初始压力定性地类似于组织的结构(即,其不均匀性是可见的)。然而,需要对材料参数进行成像(其值可以作为诊断信息)。这就是定量光声断层扫描(qPAT)的目标。
从数学上讲,这个问题可以这样提出。在生物组织中,光子散射是与吸收相比的主要效应,光传递可以用辐射传递方程的扩散近似来描述。
📚2 运行结果
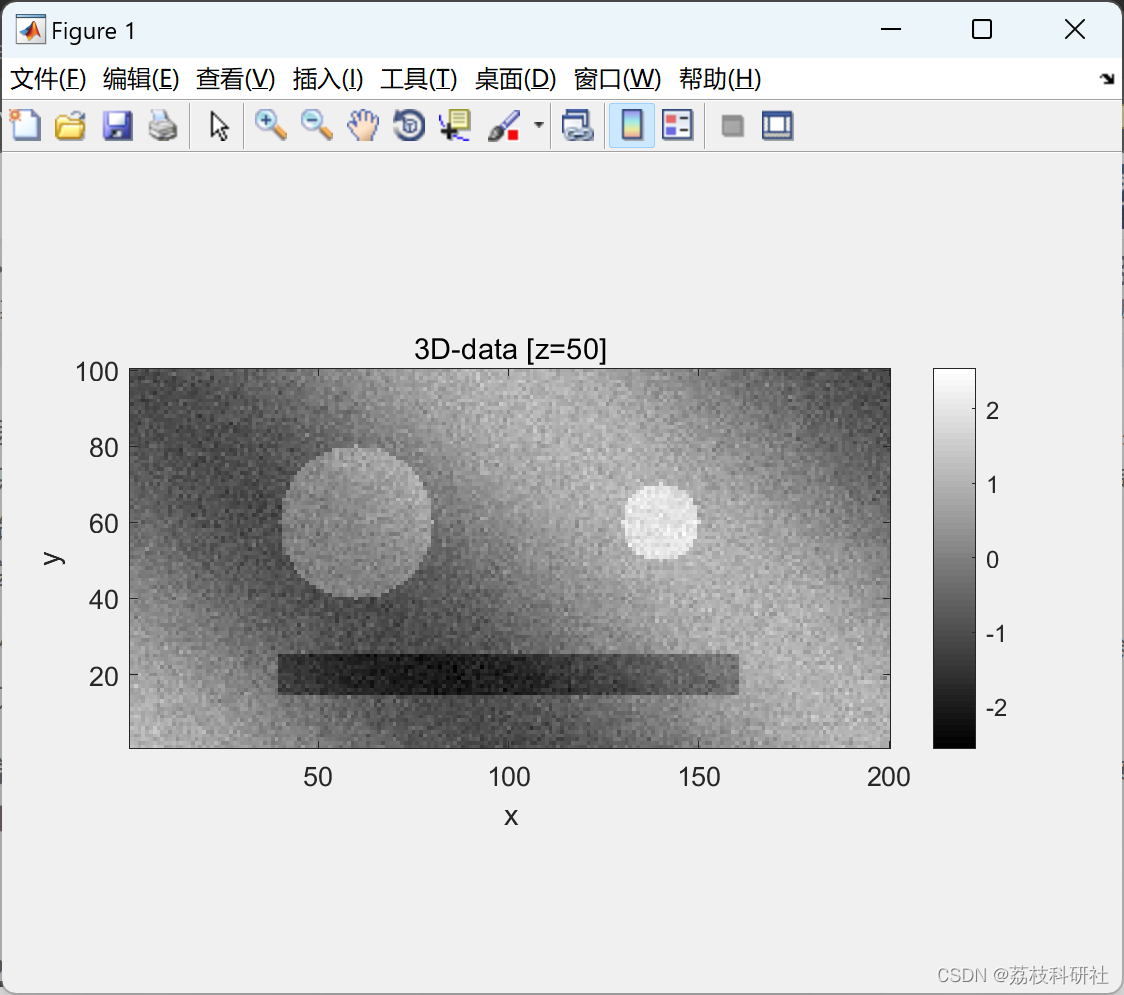
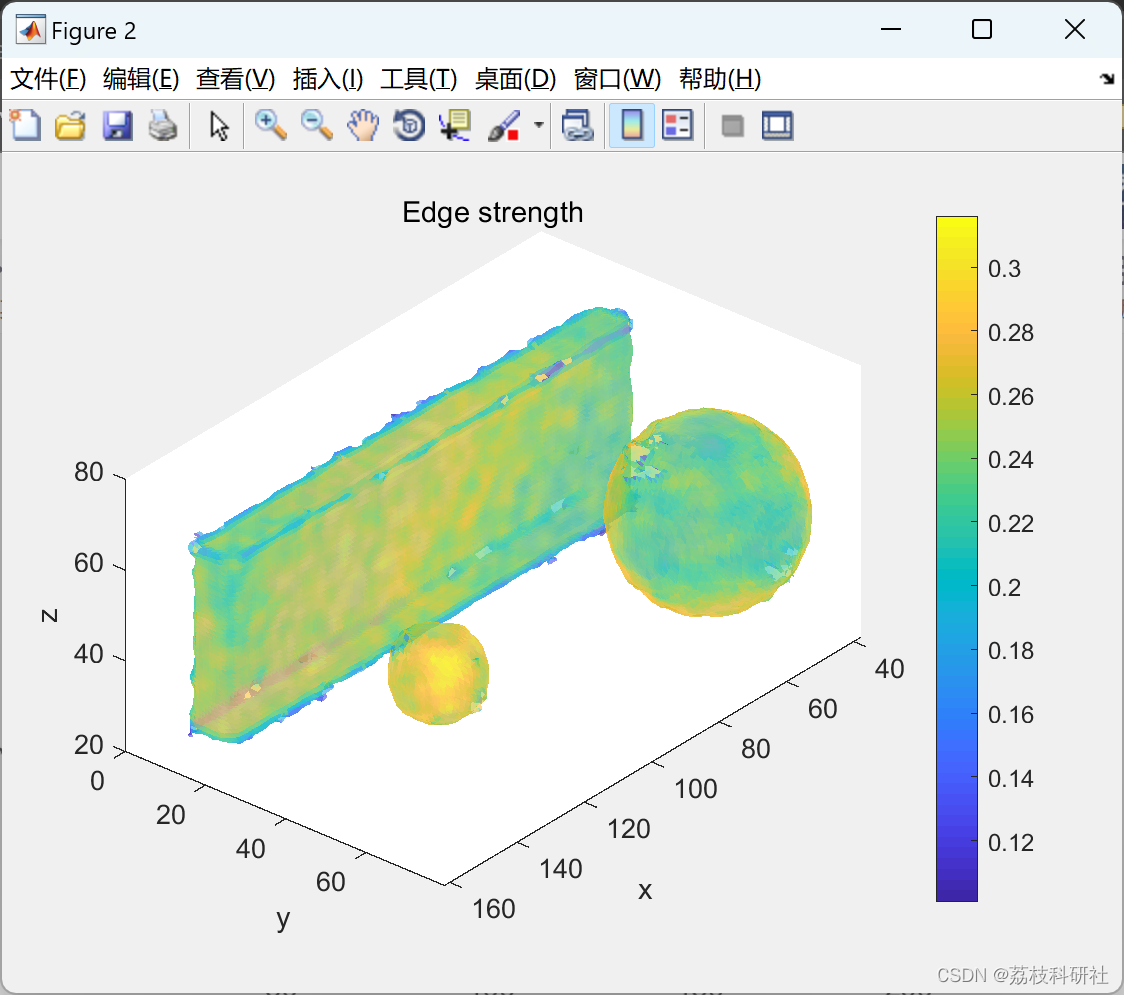
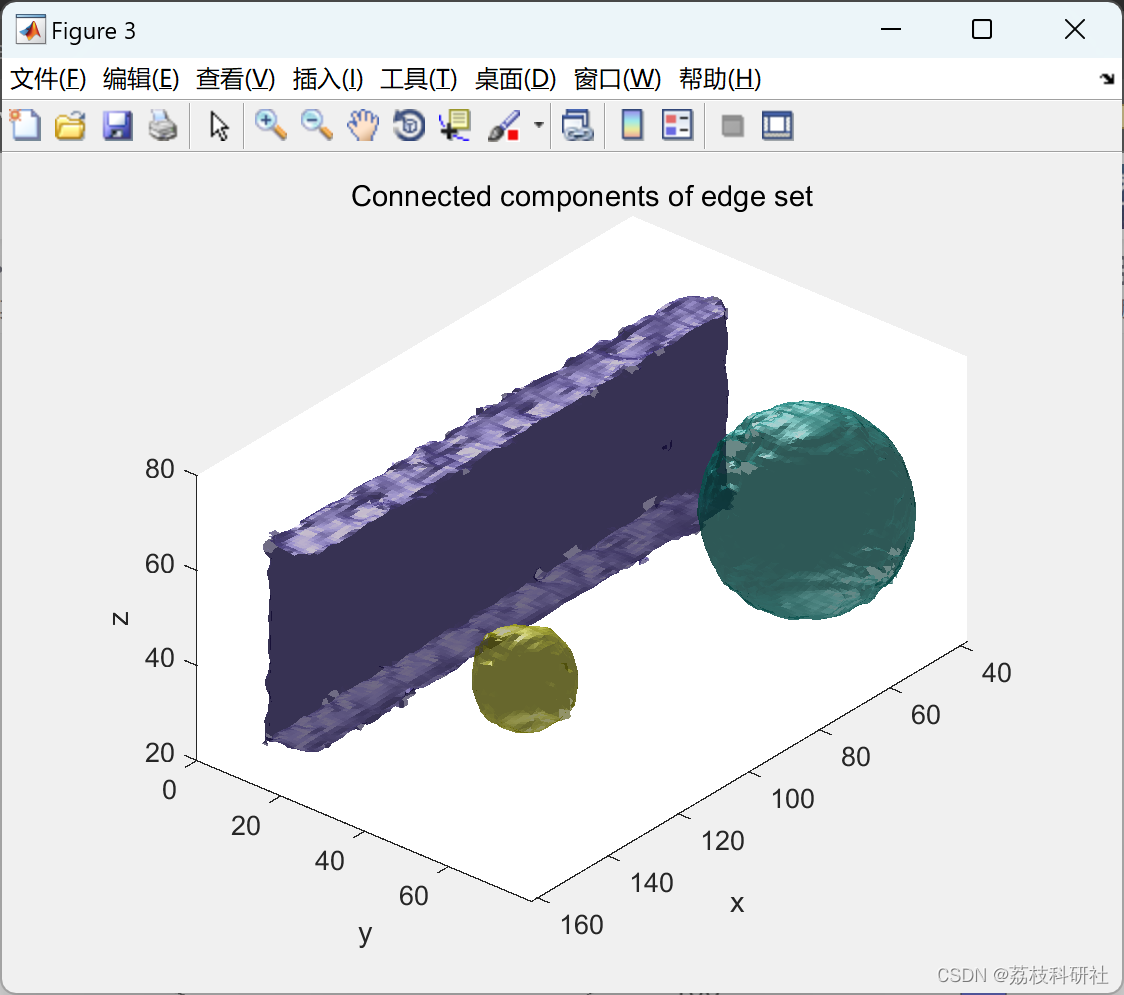
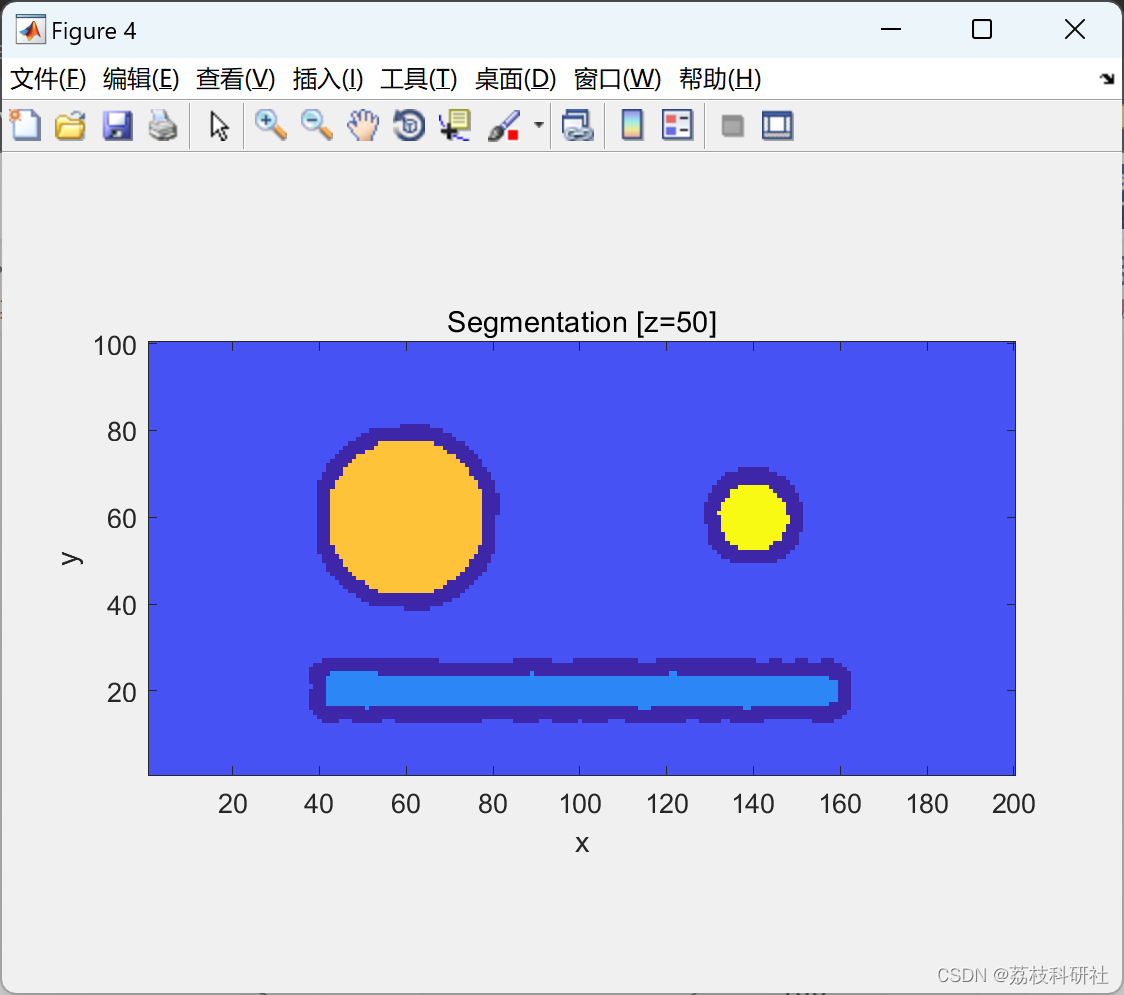
部分代码:
function plotsurface(surf,coloring,alpha)
% function plotsurface(surf,coloring,alpha)
% Plot surface (face & vertex list) with given coloring
% default: uniform coloring
if ~exist('coloring','var')
coloring=ones(length(surf.vertices),1);
end
% default: facealpha = 0.5
if ~exist('alpha','var');
alpha=0.5;
end
patch('Faces',surf.faces,'Vertices',surf.vertices,'FaceVertexCData',coloring,'FaceColor','interp','edgecolor', 'interp','FaceAlpha',alpha);
xlabel('x'); ylabel('y'); zlabel('z'); view(3); daspect([1 1 1]);
shading flat;
end
🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。