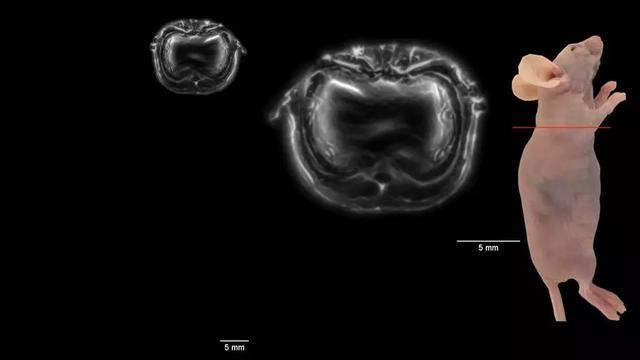
近红外硅量子点波长500nm左右
硅量子点由于具有优异的发光特性,能够应用于光电器件和生物成像等领域。本征硅量子点的性质显著依赖于其尺寸大小和表面状况。同时,作为半导体材料,掺杂是调控硅量子点性质的另一个维度。通过掺杂研究人员可以对硅量子点的光学、电学、磁学等性能进行准确
调控,极大地拓展硅量子点的应用领域。
本章首先概述硅量子点的基本性质,包括光学、电学和热学性质;其次介绍其制备方法和应用领域;后介绍国际上相关研究小组对硅量子点掺杂的研究进展,包括镶嵌在二氧化硅中的硅量子点和独立存在的硅量子点。
硅量子点的性质
对于半导体材料,当其尺寸小于激子波尔半径时会呈现出与体材料不同的性质。激子波尔半径(aB)的计算公式为:

式中ℏ为普朗克常量,ε为真空介电常数,e为电子电量,me为电子有效质量,mh为空穴有效质量。对硅来说,其激子波尔半径约为4.9nm。当晶体硅的尺寸小于约4.9nm时它会出现量子限域效应、表面效应和多激子效应等。由于量子限域效应,硅量子点中的载流子(如电子和空穴)的运动会受到限制。随着硅量子点尺寸的减小,其能带发生展宽,并且从体硅的连续能级变为准连续的分裂能级,同时在禁带中多出1至3个激子能级。
硅量子点的禁带宽度随其尺寸的变化如图1.1所示。Buuren等人[8]发现硅量子点的禁带宽度增大是由价带向下、导带向上移动造成的,并且价带移动的能量是导带移动能量的两倍(即ΔEVB=2ΔECB)。量子限域效应使硅量子点的吸收和光致发光能量随尺寸减小而蓝移,同时由于电子动量的不确定性增加,电子-空穴复合几率显著增加,使硅量子点成为一种极其重要的发光材料。

硅量子点的应用
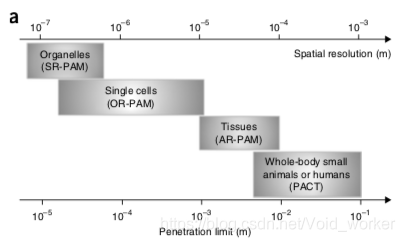
硅量子点是当前纳米材料领域的一个研究热点,由于其优异的光电特性、无性以及和现有硅基集成工艺良好的兼容性,能够应用于诸多领域如记忆存储、生物成像、锂离子电池、太阳能光伏、发光器件、探测器等。其中太阳电池、发光二极管(LED)和光电探测器是实现硅量子点优异光电特性的主要器件,下面简要介绍硅量子点在这三种器件中的应用。
锗量子点GeQDs.光热效果性能优异,可用于光热成像治疗光声成像,载药的介绍
应用光热效果性能优异,可用于光热成像治疗光声成像,载药
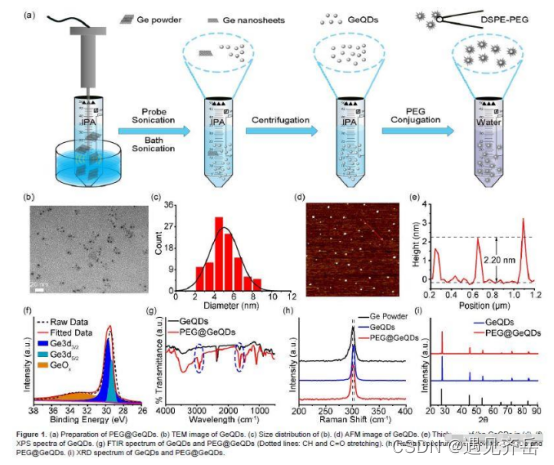
我们通过将锗粉末放在异丙醇中进行超声合成了GeQDs ,并进行了一系列修饰和表征( Figure1 )。TEM和AFM表征结果显示GeQDs的大小为4.5 nm、厚度为2.2 nm。由于这种GeQDs很容易在高盐溶液中沉淀,因此作者采用DSPE-PEG对其进行修饰得到了PEG修饰的PEG@GeQDs。PEG@GeQDs在PBS和培养基中孵育24 h后无明显沉淀,FTIR分析显示PEG修饰成功,拉晏光谱和XRD分析确定了GeQDs和PEG@GeQDs的晶体结构。进一步的吸收光谱分析显示PEG@GeQDs的吸收谱带与其他二维材料相似,其在808 nm处的近红外光谱消光系数为5.333Lg-1 cm-1 ,显著高于其他PTAs。
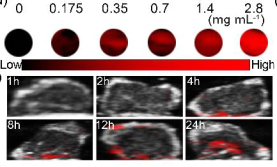
我们通过使用808 nm的激光照射不同浓度的PEG@GeQDs ,对其光热性能进行了分析( Figure2) ,结果发现PEG@GeQDs表现出了依赖于浓度和激光强度的光热效果,其光热转化效率( 45.9% )远這于其他PTAs。而和一些光热转化效率更高的材料相比, PEG@GeQDs的合成方法更简单、成本更低。
其它产品:
NiPS3量子点修饰氮掺杂介孔碳
PbS量子点修饰TiO2纳米棒阵列
CdS量子点修饰TiO2纳米棒阵列
氧化锌量子点修饰磁性石墨烯
WO3量子点修饰TiO2纳米管阵列(WO3/TiO2-NTAs)
CdSe量子点修饰DSPE-PAA
Bi量子点修饰C掺杂二维BiOCl纳米片
石墨烯量子点修饰BiOI/PAN柔性纤维|碘氧化铋(BiOI)
GQDs修饰BiOI/PAN纤维复合材料(GQD-BiOI/PAN)
碳量子点修饰g-C3N4/SnO2复合材料
以上资料来自齐岳生物小编axc,2022.04.06