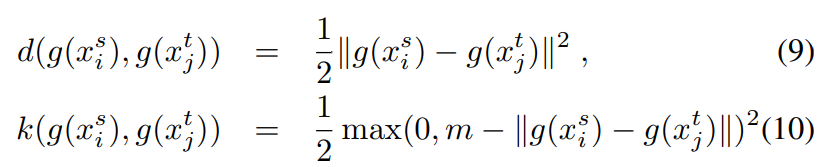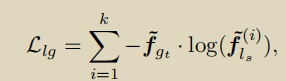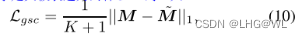Supervised Discrete Hashing
2015 CVPR
-
问题:
处理施加在追踪的哈希码上的离散约束,使哈希优化具有挑战性(通常是NP- hard)。 -
解决:
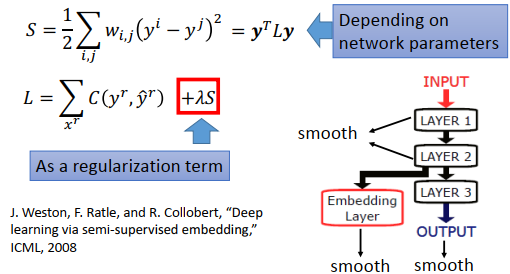
提出了一个新的监督哈希框架,其中的学习目标是生成最优的二进制哈希码用于线性分类。
通过引入一个辅助变量,我们对目标进行了重新模拟,使得它可以通过使用正则化算法来有效地求解,该算法的关键步骤之一是解决与NP-hard二值优化相关的正则化子问题。
通过循环坐标下降,证明了该子问题具有解析解。
因此,高质量的离散解最终可以以一种有效的计算方式获得,从而处理大规模数据集。 -
应用:
在四个大型图像数据集上评估SDH -
传统的算法:
- 数据无关的哈希:
LSH是最流行的数据无关方法之一,通过随机投影生成哈希函数,可度量多种距离(欧式、马氏等),缺点是需要较长的位来实现高准确率和召回率,导致存储较大。 - 数据相关的哈希:
紧凑的二进制码能有效高效地索引和组织大规模数据
典型算法:
线性哈希:unsupervised PCA Hashing、Iterative Quantiza-tion (ITQ) 、Isotropic Hashing、Supervised Minimal Loss Hashing (MLH)、Semi-Supervised Hashing (SSH)、LDA Hashing、Ranking-Based Supervised Hashing、 FastHash
非线性哈希:BRE、RMMH、KSH、ITQ、SH、AGH、IMH
- 数据无关的哈希:
为了简化二进制码学习过程中所涉及的优化问题,大多数上述方法选择首先通过丢弃离散约束来解决松弛问题,然后对已解的连续解进行阈值(或量化),以获得近似的二进制解。但是可能由于累积的量化错误而使所得到的哈希函数效率较低。ITO通过正交旋转来减少量化误差,但是它由于使用预先计算的映射来学习正交旋转导致了它不是最优的。
SDH的提出:直接优化二进制哈希码的监督哈希框架
-
为了利用有监督的标签信息,作者根据线性分类来构建哈希框架,其中学习的二进制码被期望是最适合分类的。更具体地说,学习的二进制码可以看作是原始数据的非线性生成的特征向量。利用标签信息,使这些二值特征向量易于分类。类似于高阶离散增强学习,我们将原始数据非线性地转换为一个二进制空间,然后在该空间中对原始数据进行分类。
-
为了实现这一思想,作者提出了一个联合优化过程,该过程联合学习二进制嵌入和线性分类器。在这个公式中,一组哈希函数同时被优化以适应学习到的二进制位。为了更好地捕获底层输入数据的非线性结构,这些哈希函数是在内核空间中学习的。然后整个联合优化的过程以迭代的方式执行(和三个相关子问题)
-
为了解决最关键的子问题——二进制码优化,在监督哈希框架中提出了一个离散循环坐标下降(DCC)算法来逐位生成哈希码。通过为线性分类器仔细选择损失函数,DCC算法以封闭形式产生最优散列位,这使得整个优化过程非常高效,可以自然地扩展到大量的数据集。这种使用了DCC的监督哈希方法称为监督离散哈希SDH。
-
作者提出了一种新的监督哈希方法,基于好的哈希码对于线性分类是最优的假设。关键技术是不带松弛直接求解相应的离散优化问题。首先,通过引入一个辅助变量,我们重新构建优化目标,使其可以使用正则化方案有效地求解。其次,SDH方法的关键步骤是求解NP-hard二元优化子问题。SDH通过离散循环坐标下降DCC,在每一步求解相关的二进制优化并得到解析解,从而使整个优化非常有效。没有松弛地直接优化离散位对获得高质量哈希码起着关键作用。
SDH的具体分析
目标函数:
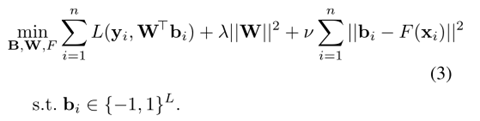
L2 loss形式:

Hinge loss形式:
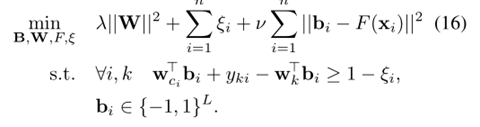
测评
-
数据集:
CIFAR-102,
M-NIST3
NUS-WIDE
ImageNet -
特征:
所有的数据样本都被归一化为单位长度
对比算法:
监督哈希:BRE , MLH, SSH, CCA-ITQ , KSH, FastHash
无监督哈希:PCA-ITQ , AGH, IMH with t-SNE -
评测指标:
计算效率和检索性能
CIFAR和M-NIST:哈希查找Precision(汉明半径的精度)、汉明排名MAP(平均精度的平均值) -
实验内容:
1.首先比较了L2 loss和hinge loss,发现在precision和MAP上二者一致,所以在后续实验中都用L2 loss
2.比较了针对目标公式,使用离散约束和不使用离散约束的Precision 和MAP,带离散约束的明显好
3.不同数量锚点在检索性能的比较,发现锚点越多检索性能越好,锚点越多计算成本越高
4.在CIFAR数据集应用不同算法,SDH的precision和MAP高于同状态的其它算法,且训练费时更少
5.在MNIST数据集(手写数字)上SDH有更高的precision和recall
6.在NUS-WIDE数据集(多标签)上当哈希吗长度大于32时SDH取得最高的precision,MAP一直都是SDH最高
7.在imagenet数据集(高维特征)上SDH的precision取得了最高
8.在CIFAR数据集上SDH取得了最高的分类精度