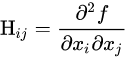supervised pca很简单粗暴,计算 X X X的每一个纬度和 Y Y Y的相关性,取一个阈值,丢掉一些纬度,然后用普通的pca降维。
如何计算两个随机变量的相关性/相似性?
两个随机变量 X , Y X,Y X,Y,有一个函数 ϕ \phi ϕ,可以把一维随机变量映射到高维空间,映射后两个向量均值的距离可以表示两个随机变量的相关性。
∣ ∑ i = 1 n ϕ ( x i ) − ∑ j = 1 m ϕ ( y i ) ∣ 2 = ( 1 n ∑ i ϕ ( x i ) − 1 m ∑ j ϕ ( y j ) ) T ( 1 n ∑ i ϕ ( x i ) − 1 m ∑ j ϕ ( y j ) ) = 1 n 2 ∑ i , j K ( x i , x j ) + 1 m 2 ∑ i j K ( y i , y j ) − 2 m n ∑ i , j K ( x i , x j ) \begin{aligned} &|\sum_{i=1}^n \phi(x_i)-\sum_{j=1}^m \phi(y_i)|^2 \\ =&(\frac{1}{n}\sum_i \phi(x_i)-\frac{1}{m}\sum_j \phi(y_j))^T(\frac{1}{n}\sum_i \phi(x_i)-\frac{1}{m}\sum_j \phi(y_j)) \\ =&\frac{1}{n^2}\sum_{i,j}K(x_i,x_j)+\frac{1}{m^2}\sum_{ij}K(y_i,y_j)-\frac{2}{mn}\sum_{i,j}K(x_i,x_j) \end{aligned} ==∣i=1∑nϕ(xi)−j=1∑mϕ(yi)∣2(n1i∑ϕ(xi)−m1j∑ϕ(yj))T(n1i∑ϕ(xi)−m1j∑ϕ(yj))n21i,j∑K(xi,xj)+m21ij∑K(yi,yj)−mn2i,j∑K(xi,xj)
K K K可以取RBF, K ( x i , x j ) = e − ∣ x i − x j ∣ 2 r K(x_i,x_j)=e^{-\frac{|x_i-x_j|^2}{r}} K(xi,xj)=e−r∣xi−xj∣2
这就是MMD,Maximun Mean distance.
判断两个随机变量的相关性 ∣ P ( x , y ) − P ( x ) P ( y ) ∣ 2 |P(x,y)-P(x)P(y)|^2 ∣P(x,y)−P(x)P(y)∣2,这个叫做HSIC


dataset X d ∗ n , Y q ∗ n X_{d*n},Y_{q*n} Xd∗n,Yq∗n, { ( x i , y i ) } i = 1 n \{(x_i,y_i)\}_{i=1}^n {(xi,yi)}i=1n, x i ∈ R d , y i ∈ R q x_i\in R^d,y_i \in R^q xi∈Rd,yi∈Rq.
K K K is an n by n matrix as the result of applying a kernel K on data set X.
B B B is an n by n matrix as the result of apply a kernel function B on data set Y.
T r ( K H B H ) Tr(KHBH) Tr(KHBH) is a measure of dependence.
- Goal: find a linear transformation U, such that U T X U^TX UTX has maximum dependence to Y.
- make a linear kernel on U T X U^TX UTX
- max U 1 ( n − 1 ) 2 T r ( X T U U T X H B H ) \max_U \frac{1}{(n-1)^2}Tr(X^TUU^TXHBH) maxU(n−1)21Tr(XTUUTXHBH)
- max U T r ( U T X H B H X T U ) \max_U Tr(U^TXHBHX^TU) maxUTr(UTXHBHXTU) add a constraint U T U = I U^TU=I UTU=I
- U will be the top p eignenvectors of X H B H X T XHBHX^T XHBHXT
X H XH XH~ ( X − X ˉ ) (X-\bar{X}) (X−Xˉ)


kernel supervised pca
待续,不是很理解