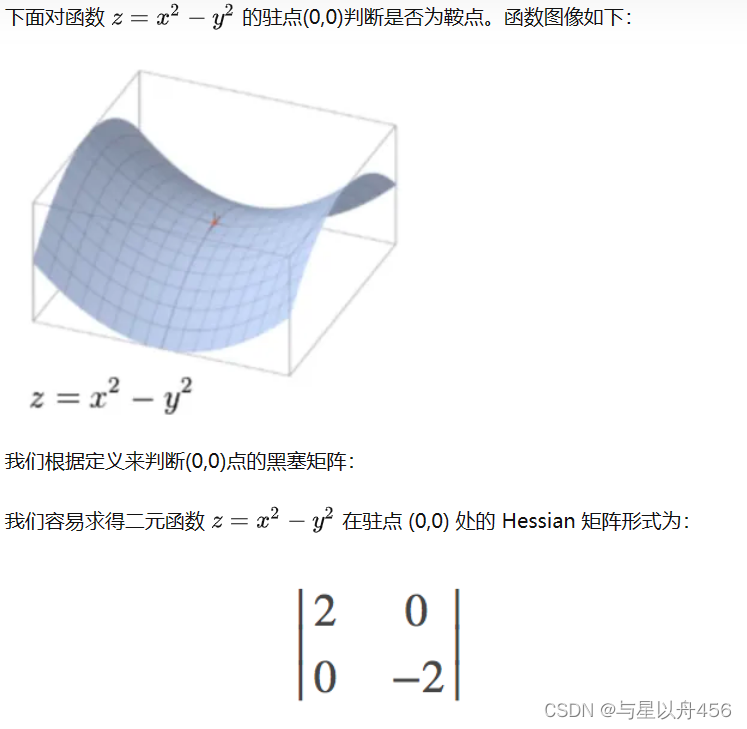
摘要:基于图像级标签的弱监督语义分割(WSSS)由于标注成本低而备受关注。现有的方法通常依赖于类激活映射(CAM)来度量图像像素和分类器权重之间的相关性。然而,分类器只关注识别区域,而忽略每张图像中的其他有用信息,导致定位图不完整。为了解决这个问题,我们提出了一种自监督图像特定原型探索(SIPE),它由图像特定原型探索(IPE)和通用特定一致性(GSC)损失组成。具体来说,IPE为每一张图像量身定制原型,以捕获完整的区域,形成我们的图像特定的CAM (is -CAM),它由两个连续步骤实现。此外,我们还提出了GSC来构建通用CAM和我们的特定is -CAM的一致性,进一步优化了特征表示,增强了原型探索的自校正能力。在PASCAL VOC 2012和MS COCO 2014分割基准上进行了大量的实验,结果表明我们的SIPE仅使用图像级标签就实现了最新的性能。
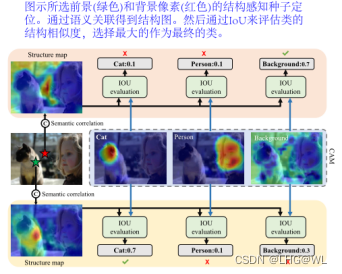
引言:现有方法大多利用类激活映射(CAM)[53]技术提供目标对象的定位线索。具体来说,这些方法训练一个分类器,并将其学习到的权重作为每个类的一般表示,即类中心。然后,利用这个类中心与图像像素进行关联,得到如图1所示的定位图。
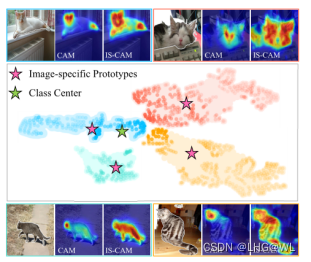
然而,CAM倾向于专注于几个主要区域(猫的头),而忽略了其他有用的线索(猫的身体)。为了解释这一问题,我们将从训练过的分类网络中提取的前景像素级特征可视化。这些特征用四种不同的颜色表示,其透明度表示CAM的激活。我们发现,类中心总是给予较近的像素(对应于某些主区域)较高的激活,而忽略了较远的像素。激活不平衡导致定位图不完整,如图1所示。此外,通过特征的质心(粉色星形)激活每个图像上的特征,有助于探索更完整的区域(见图1所示的image-specific CAM (IS-CAM))。因此,本文旨在定制图像特定原型,自适应地描述图像本身。
为此,我们提出了一种新的弱监督语义分割框架,称为自监督图像特定原型探索(SIPE)。所提出的SIPE由图像特定的原型探索(IPE)和一般特定一致性(GSC)损失组成,如图2所示。具体来说,IPE被实现为两个顺序的步骤来描述原型,允许捕获更完整的本地化映射。在第一步中,我们利用像素间语义探索空间结构线索,定位每个类的鲁棒种子区域。给定种子区域,我们提取图像特定的原型,然后通过原型相关生成我们的IS-CAM。在此基础上,提出了一种GSC方法,以构建通用凸轮与特定is -CAM的一致性。这种自监督信号进一步优化了特征表示,增强了原型探索的自我修正能力。
贡献:1.我们提出了自监督图像特定原型探索(SIPE)来学习图像特定知识,用于弱监督语义分割。
2.我们提出了图像原型探索(IPE),该方法通过结构感知的种子定位和背景感知的原型建模来为每个图像定制特定的原型。它使模型能够捕获更完整的本地化地图。
3.我们提出了一种通用-特定一致性(GSC)损失来有效地正则化原始CAM和ISCAM,增强特征表示能力。
相关工作:
Erasure and accumulation.
擦除方法通过有意地从图像]或特征图中去除鉴别区域来探索更多的目标区域。然而,擦除大部分鉴别区域可能会使分类器混淆,导致假阳性。为了避免这一问题,一些作品通过对扩展卷积率、图像尺度、空间位置和训练过程应用精心设计的采样来累积多个激活。
Cross-image mining.
考虑到图像之间的共享语义,一些作品设计了跨图像关系挖掘模块,如跨图像亲和力、最大二部匹配和共注意分类器,挖掘弱标签的语义上下文。在此基础上,利用图卷积网络和自注意机制,探索多图像协同信息捕获潜在知识。
Background Modeling.
许多方法通过使用辅助显著图来获得精确的背景,这是一种费力的方法。在没有辅助地图的情况下,Fan等人提出了一个intra-class discriminator来区分每个类的前景和背景。然而,由于图像的对象和场景的多样性,学习每个类的通用类内鉴别器是相当棘手的。
Self-supervised Learning.
最近,自监督方法挖掘潜在信息并构建监督信号,被证明是缩小完全监督和弱监督语义分割之间监督差距的有前途的解决方案。Wang等将各种变换图像的一致性正则化应用到CAM上,实现自我监督学习。Chang等人引入了一个发现子类别的自我监督任务,它提供了额外的监督以增强特征表示。
与现有的方法相比,我们充分考虑了图像的特殊性,引入图像特定的原型来发现完整的区域,并构建了一种自监督的方式来赋能特征表示。

Approach
Class Activation Mapping
给定一个输入图像和一个预先训练的分类网络,类激活映射Mf K前景类可以表示为:
![]()
其中Fs是来自网络最后一层的语义特征,θk表示第k个分类器权重,因此Mk是第k个类特异性激活映射。在前作的基础上,CAM在空间轴上取最大值,进一步归一化为[0,1],可视为每一类的概率。
考虑到背景在分割任务中的重要性,我们根据Mf估计背景激活映射Mb。由于CAM倾向于部分覆盖目标区域,因此估计的背景在前景区域往往含有较高的响应,这将带来相当大的噪声。为了减少这种混淆,我们通过引入衰减系数α = 0.5来减弱背景概率:
![]()
我们将处理后的背景激活映射与前景激活映射结合为一个整体,即M = Mf∪Mb,以帮助建模背景知识。
Image-specific Prototype Exploration
提出了图像特定的原型来表示每个类的特征分布,允许捕获更完整的区域。与少镜头分割中的原型表示不同,WSSS中没有地面真值像素级掩码。为了探索用于描述特征分布的图像特定原型,我们设计了一个高效的两步管道。第一步提供健壮的类明智的种子区域,第二步将这些种子聚合在一个综合特征空间上,以实现精确的图像特定表示。
Structure-aware Seed Locating.一种直接获取种子的方法是经验地为CAM选择阈值,但由于对象和场景的多样性,很难对不同的图像使用固定的阈值。虽然CAM更关注识别区域,但对其余区域也产生较弱的激活。这意味着CAM具有提供语义对象的空间结构的潜力。此外,像素的空间结构可以由聚类高相关性像素构成。对于一幅图像,我们可以通过与cam的空间结构比较来确定每个像素的类别。基于上述分析,我们提出了一种结构感知种子定位方法,通过探索像素间语义获取空间结构,并使用cam作为模板匹配最优类别。
图3显示了所选的前景和背景示例所提出的方法。首先,对任意像素i,取其语义特征向量f i作为查询,计算与该特征图中所有像素的语义相关性;由于相关性分数高的像素更可能属于同一类,这些高相关性像素可以突出空间结构。因此,我们通过像素间的语义关联来定义像素的空间结构:
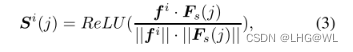
其中·为点积,j为特征图和结构图上的空间索引。Si(j)表示像素i和j之间的语义相关性,Si为像素i的结构图。我们通过ReLU函数抑制负相关性,消除不相关像素的影响。
其次,我们将像素 i 的结构图和 CAM 之间的分类 IoU 评估为结构相似度:
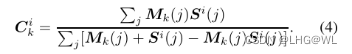
这里Cik表示像素i相对于第k类的结构相似度。J是激活映射和结构映射的空间索引。从图3可以看出,前景像素(绿色星号)与猫的身体相关,与猫类CAM的IoU最高。另外,背景像素(红星)与前景像素没有关联,所以它更有可能属于背景类。
最后,将像素i分配给相似度最大的类别:
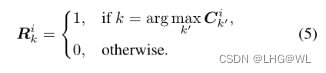
通过对图像的所有像素并行重复此过程,前景和背景类别的种子区域 R 的位置如图 2 所示。
Background-aware Prototype Modeling. 在本节中,我们同时对前景和背景原型进行建模。 考虑到背景没有特定的语义,很难在语义特征空间上探索具有代表性的背景原型。 相反,来自浅层的特征包含丰富的低级视觉信息(例如颜色、纹理),更适合建模与背景相关的信息。 因此,我们修改了骨干网的架构以捕获分层特征以进行有效的原型表示
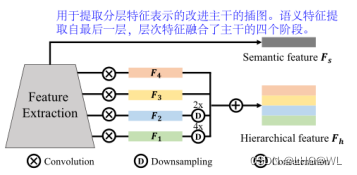
如图4所示为修改后的主干体系结构。具体来说,我们增加了四个卷积层来提取多尺度输出。然后将多尺度输出调整到相同的大小,并将其串联起来,形成层次化的特征跳频。因此,前景和背景的图像特定原型Pk可以表述为层次特征空间中种子区域的质心:

其中i索引空间位置,如果参数为真,1(·)输出1,否则输出0。这个过程在种子像素上执行类的压缩,实现K个前景原型和一个背景原型。
有了这些特定于图像的原型,特定于图像的CAM (is -CAM)的计算如下:
![]()
其中, ̄Mk(j)为j像素处的第k个is - cam。相关在[−1,1]中有界,然后是ReLU以去除负相关。
与以分类器权重为类中心计算每个像素相关性的原始CAM相比,提出的IS-CAM利用针对每幅图像量身定制的原型,实现更完整的目标区域。此外,背景原型建模提供了高质量的背景定位线索,进而帮助确定准确的前景区域。
Self-supervised Learning with GSC
为了进一步利用图像特定知识,我们引入了一种自我监督学习范式。 总体训练损失包括多标签分类损失和一般特定一致性(GSC)损失,
![]()
分类损失由图像级类别标签y和预测-y之间的多标签软边距损失计算,该软边距损失由CAM生成的前景图平均得到。
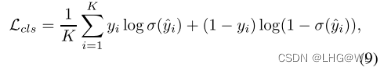
其中σ为sigmoid激活函数。
使用GSC最小化由分类器权重激活的原始CAM与由图像特定原型激活的ISCAM之间的差异。这种一致性正则化的数学定义被表述为两种CAM的L1归一化:
![]()
其中M,~M分别表示原始CAM和IS-CAM。 损失是在 K 个前景类和一个背景类上平均的。
在这种一致性下,将图像特定的知识注入到特征表示中,协同优化在训练周期中完成。
IS-CAM迫使原始CAM关注缺失的对象区域,隐式地缩小了鉴别像素和缺失像素之间的特征距离。此外,增强的语义和层次特征有利于捕获更全面、更准确的图像特定原型,提高定位地图的质量。