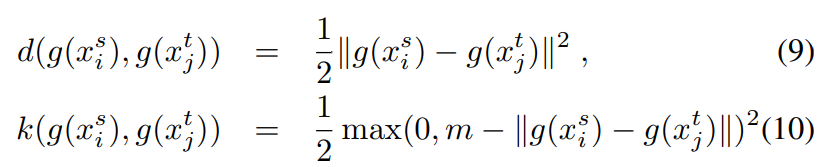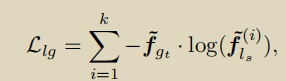Self-Supervised Difference Detection for Weakly-Supervised Semantic Segmentation
- 摘要
- 1. Introduction
- 2. Related Works
- 3. Method
- 3.1. Difference detection network
- 3.2. Self-supervised difference detection module
论文地址
这篇论文原文的定义实在是太混乱了,也可能是我自己理解能力不够,我自己写完连自己都搞晕了,所以更到一半后面的就没有继续记录,这篇文章讲的比较清楚。
摘要
本文通过移除噪音来提升mapping function的准确性。本文提出self-supervised difference detection模块,通过预测mapping前后的分割掩码来减少noise。
1. Introduction
语义分割要求复杂精细的标注,而弱监督的标注很容易获得。WSSS任务通常使用可视化的方法,比如CAM去解决。这样一来,从可视化结果到语义分割结果的映射就显得很重要,映射的其中一种方法就是CRF,CRF应用在映射函数,优化概率的分布,是一种利用颜色和位置信息作为特征来优化拟合到区域边缘的概率分布的方法。许多映射方法虽然有效,但是映射结果包含噪音。本文的映射函数将结果视为可以接受其包含噪音的结果,然后提出了一种暴力的解决噪音的方法。
在本文中,用作映射函数的输入的信息称为knowledge,包含噪音的监督信息称为advice,允许一对一映射的完全监督学习的监督称为teacher。knowledge和advice不同的部分称为difference。
推理knowledge和来自于knowledge的advice导致要提前预测advisor的advice,有些advice很好预测,因为在训练过程中有大量相似的例子,这些advice我们认为是有用的信息。基于此,我们提出一种方法,可以通过 difference detection中预测advice中有用的信息。见Fig. 1。
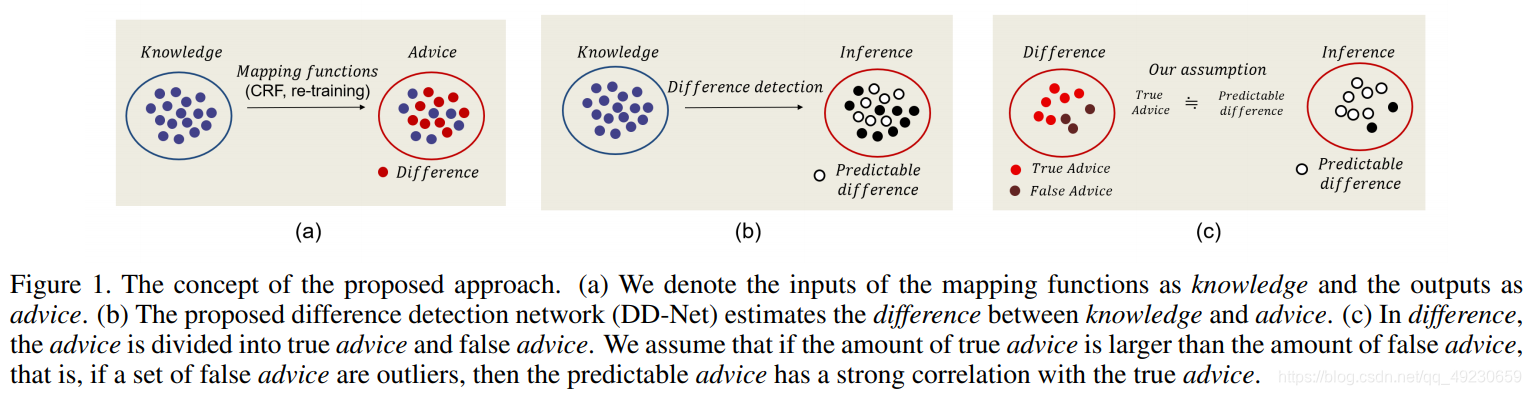
本文提出的Self-Supervised Difference Detection (SSDD)模块既可以应用在伪掩码生成的阶段,也可以应用在全监督训练阶段(这里说的全监督应该就是用伪掩码监督分割模型的阶段)。在生成seed(伪掩码)的阶段,我们用SSDD模块提炼了pixel-level semantic affinity (PSA)的CRF结果。在训练阶段,我们介绍了两个SSDD在全监督分割网络中循环的应用,并在实验中展现了良好的结果。
本文的contributions如下:
- 提出SSDD模块,减少了映射函数的噪音并选择有用的信息。
- 展示了SSDD模块在生成伪掩码和训练的阶段都有有效性。
- 实验。
2. Related Works
3. Method

原文详细讲了advice,knowledge和difference的关系,以及本文的任务。
3.1. Difference detection network
我们定义knowledge的mask为 m K m^K mK,advice的mask为 m A m^A mA,他们的difference记为 M K , A ∈ R H × W M^{K,A}\in\mathbb R^{H×W} MK,A∈RH×W。
M u K , A = { 1 i f ( m u K = m u A ) 0 i f ( m u K ≠ m u A ) M_u^{K,A}= \left\{\begin{array}{rcl} 1 & if & (m_u^K=m_u^A) \\ 0 & if & (m_u^K\neq m_u^A) \end{array}\right. MuK,A={10ifif(muK=muA)(muK=muA)
其中 u ∈ { 1 , 2 , ⋯ , n } u\in\{1,2,\cdots,n\} u∈{1,2,⋯,n}表示像素点的位置,n是像素点的数量。然后,我们定义一个difference detection网络来推断difference。我们用从训练过的CNN中提取的特征图来协助推断。具体来讲,我们用了高级特征 e h ( x ; θ e ) e^h(x;\theta_e) eh(x;θe)和低级特征 e l ( x ; θ e ) e^l(x;\theta_e) el(x;θe),其中x是输入图像,e是由 θ e \theta_e θe参数化的embedding function。在Fig. 3中,输入掩码的confidence map d d d由difference detection network (DDNet)生成。
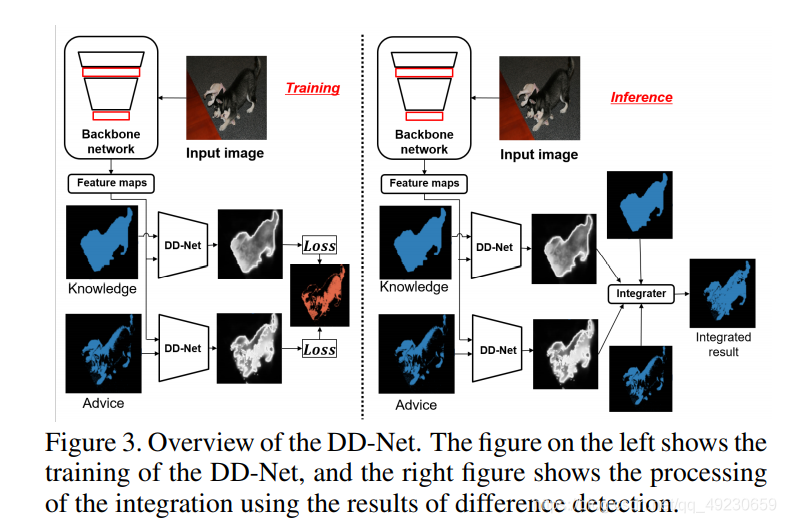
图中左边输入的两个mask即knowledge和advice分别是mapping function的输入和输出。
我们接着谈DDNet, D D n e t ( e h ( x ; θ e ) , e l ( x ; θ e ) , m ^ ; θ d ) , d ∈ R H × W DDnet(e^h(x;\theta_e),e^l(x;\theta_e),\hat{m};\theta_d),d\in\mathbb R^{H×W} DDnet(eh(x;θe),el(x;θe),m^;θd),d∈RH×W, m ^ \hat m m^是one-hot vector mask,数量和类别数相同, θ d \theta_d θd是DD-Net的参数, e ( x ) = ( e l ( x ) , e h ( x ) ) e(x)=(e^l(x),e^h(x)) e(x)=(el(x),eh(x))。DD-Net的结构如Fig. 2所示。其由3个卷积层和有3个输入1个输出的Residual block组成。

DD-Net的输入是原始mask或经过处理的mask,输出是difference mask。这个网络的loss可以由下面式子来求:
L d i f f = 1 ∣ S ∣ ∑ u ∈ S ( J ( M K , A , d K , u ; θ d ) + J ( M K , A , d A , u ; θ d ) ) \mathcal L_{diff}=\frac{1}{|S|}\sum_{u\in S}(J(M^{K,A},d^K,u;\theta_d)+J(M^{K,A},d^A,u;\theta_d)) Ldiff=∣S∣1u∈S∑(J(MK,A,dK,u;θd)+J(MK,A,dA,u;θd))
其中S是输入空间像素的集合,J()函数输出交叉熵损失。注意这里的d是DD-Net预测输出的confidence map。
J ( M , d , u ) = M u l o g d u + ( 1 − M u ) l o g ( 1 − d u ) J(M,d,u)=M_ulogd_u+(1-M_u)log(1-d_u) J(M,d,u)=Mulogdu+(1−Mu)log(1−du)
需要注意,embedding function θ e \theta_e θe的参数和 θ d \theta_d θd的优化无关。
3.2. Self-supervised difference detection module
本节详述Fig. 3的SSDD模块。advice中在difference里为TRUE的部分记为 S A , T S^{A,T} SA,T,FALSE的部分记为 S A , F S^{A,F} SA,F。这个方法的目标就是尽可能多地从 S A S^A SA中提取 S A , T S^{A,T} SA,T。 d K d^K dK是根据knowledge得到的advice的推断结果。
。。。。这篇论文原文的定义实在是太混乱了,我自己写完连自己都搞晕了,这篇文章讲的比较清楚。