这个红色的怪物叫做ELMo 、最早的self-supervised learning model
作业四的模型也是个transformer,只有0.1个million

最早的是ELMo
Cookie Monster等你来凑😼

T5是Google做的,跟车子也没什么关系,

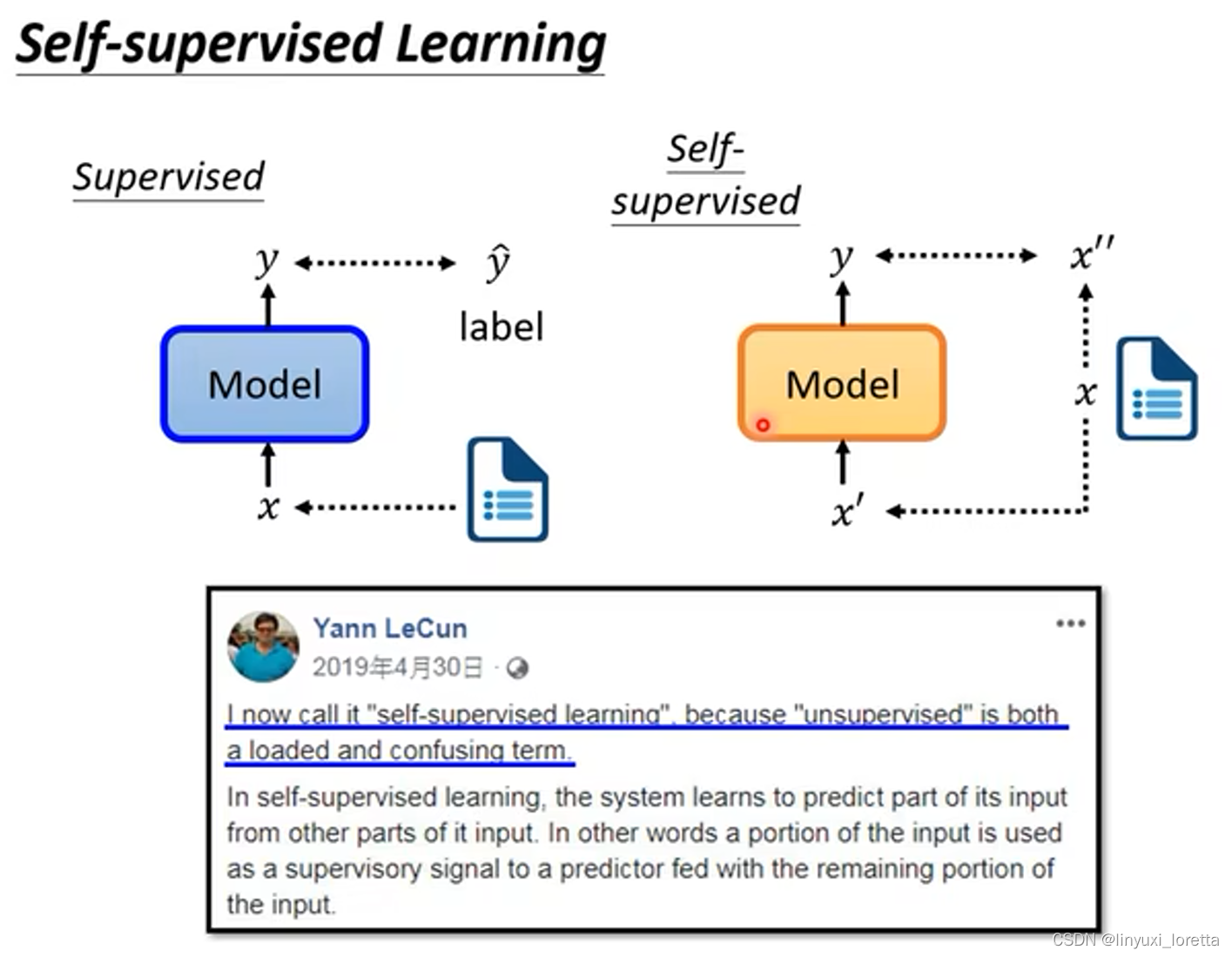
在没有label情况下,自己想办法做supervised;将没有标注的资料分成两部分,一部分作为输入,一部分作为标注,进行训练;自监督学习是unsupervised learning中的一种方法;
1、BERT模型
BERT network的架构和 transformer encoder一模一样,有self-attention、residual、normalization等等;输入一排向量,输出一排向量,输入和输出一样长;BERT最早是用在文字上,当然BERT也可以用于语音、图像等处理中,本质上都是一排向量;
token就是你在处理一段文字时的单位,token的大小是你自己决定的,
-BERT任务之一:
首先把输入文字的一些部分随机盖掉,具体而言,盖住的做法有两种,
- 把那些token换成 special token,
- 随机把那些token换成另外别的token,
两种方法都可以用,也是随机使用的;
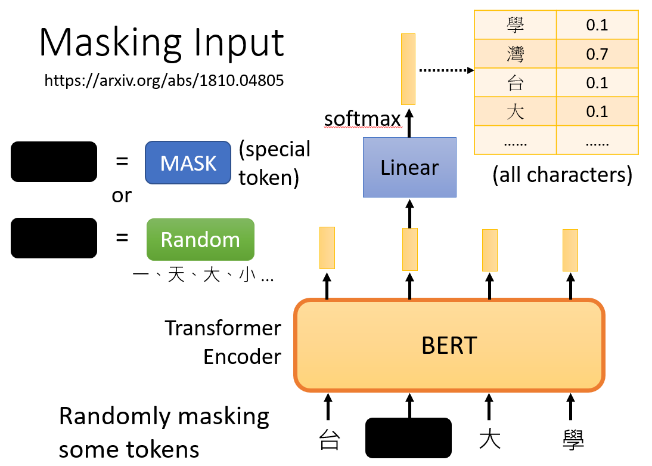
如上图,把盖住部分所对应的输出做一个线性变换(乘以一个矩阵),然后做softmax得到一个输出分布(一个非常长的向量,包含了所有的文字);

我们其实是知道被盖住的文字是哪一个字,只是bert本身不知道,将被盖住的字,即“湾”,作为ground truth,bert学习的目标就是使输出与ground truth越接近越好,minimize cross entropy;讲的更简单其实就相当于做一个分类问题,只是类别数目很多;
bert和linear model两者一起训练;
-BERT任务之二:预测句子是否为上下句
从数据集中拿出两个句子,在两个句子中加入两个特殊符号(cls代表开头,sep代表分隔)将句子拼成一个sequence,一股脑丢到bert里面,会输出另一个序列,我们只取cls对应的输出,做一个线性变换(即乘上一个矩阵),输出yes/no,yes/no是指两个句子是不是相接的;

但是Next Sentence Prediction对bert接下来想要做的事情帮助不大;Robustly optimized BERT approach (RoBERTa)(https://arxiv.org/abs/1907.11692)这篇paper中指出该方法没有什么特别的帮助。可能是因为Next Sentence Prediction这个任务太简单了,bert没有借此学到太多东西。
有另一种方法是sentence order prediction(SOP)(https://arxiv.org/abs/1909.11942),ALBERT(Bert一个进阶的版本)中使用了该方法,SOP该方法让bert判断两个句子的先后次序:
由此,bert学会了做填空题,神奇的是 他可以被用于各式各样的下游任务中,这些任务跟填空题甚至根本没什么关系,
下游任务downstream task训练时需要有标注的资料;对bert进行fine-tune(微调),就可以分化成各式各样的任务;而产生bert的过程,是自监督学习,该过程也称为pre-train(预训练);

2、bert性能测试
今天要测试self supervised learning the model的能力,常会测试在多个任务上(任务集),一个知名的任务集 标杆是GLUE (https://gluebenchmark.com/),当你想知道你训练的像bert这样的模型好不好,就可以分别微调,在GLUE的9个任务上测试;

各种预训练模型在GLUE上的性能测试如下图,有了Bert后,GLUE的分数确实逐年攀升,其中黑线表示人类在该任务上的准确率:
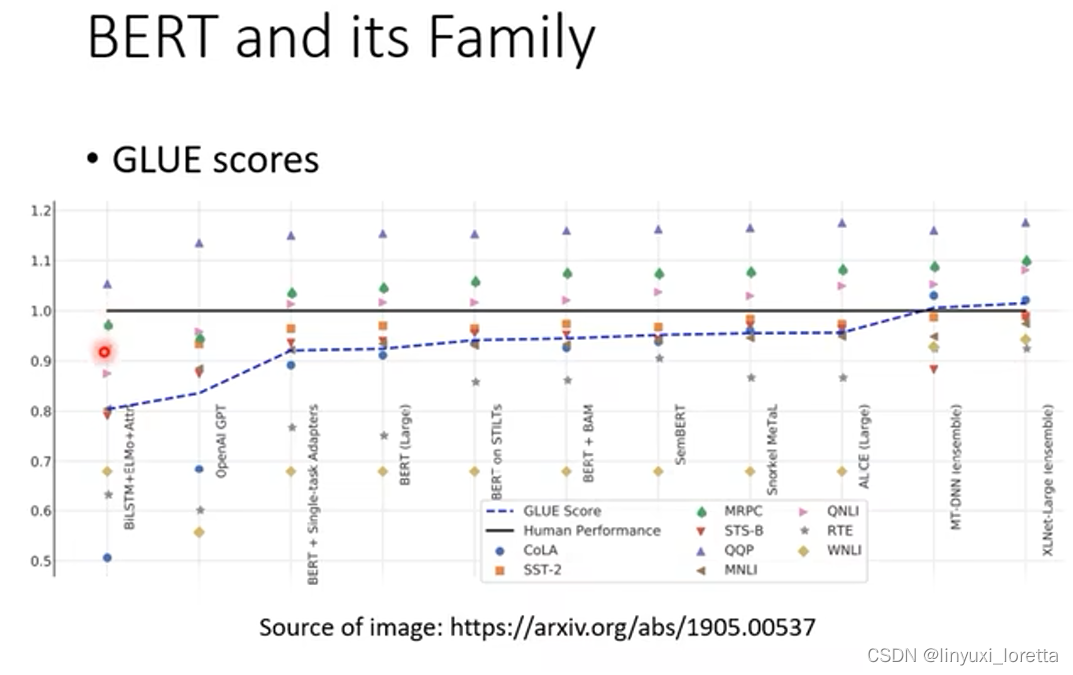
随着时间的推移,GLUE可能被玩坏了,不够难,于是又有了更难的任务,如Super GLUE;
3、微调bert用于下游任务
bert如何使用?如何进行微调?下面举例说明:
例子1:
分类任务,输入是序列,输出是类别,如情绪分析任务;
在句子前放cls,输入到bert中,只取cls对应的输出,做线性变换,softmax,输出类别;需要给bert一些有标注的资料;使用梯度下降来训练bert和linear模型,linear模型的参数是随机初始化的,而bert初始化的参数来自预训练;
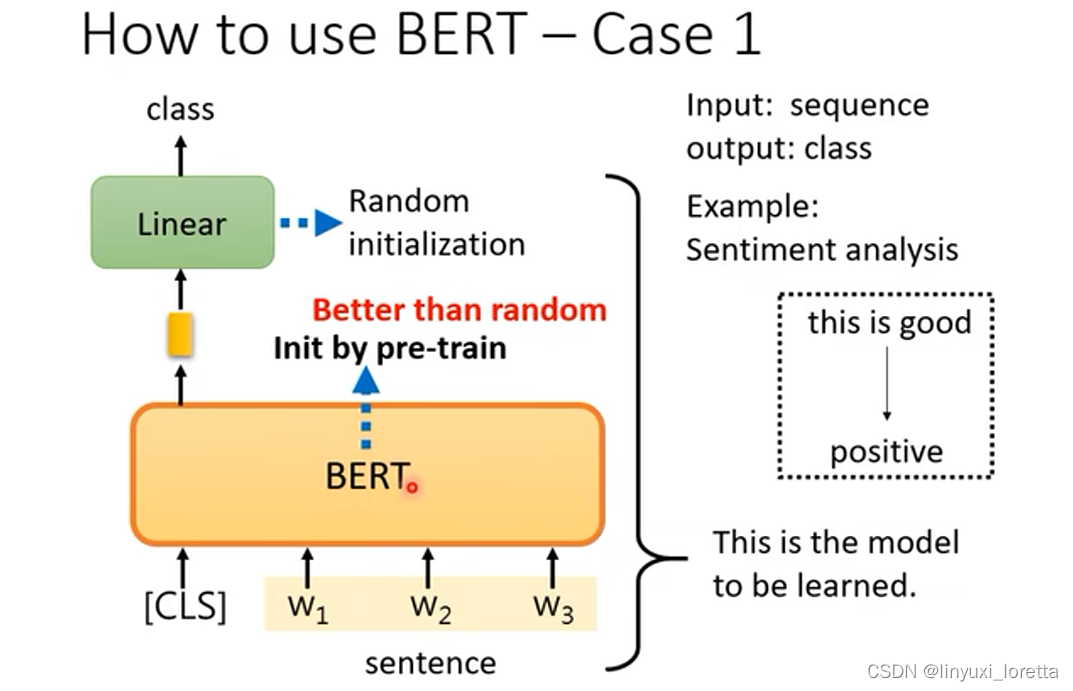
下图是使用预训练参数的bert和随机初始化参数的bert的对比,可以看出,使用了预训练参数的bert收敛速度快了很多,而且最终loss更小;使用预训练参数的bert可以理解成只需要进行微调就能够完成训练: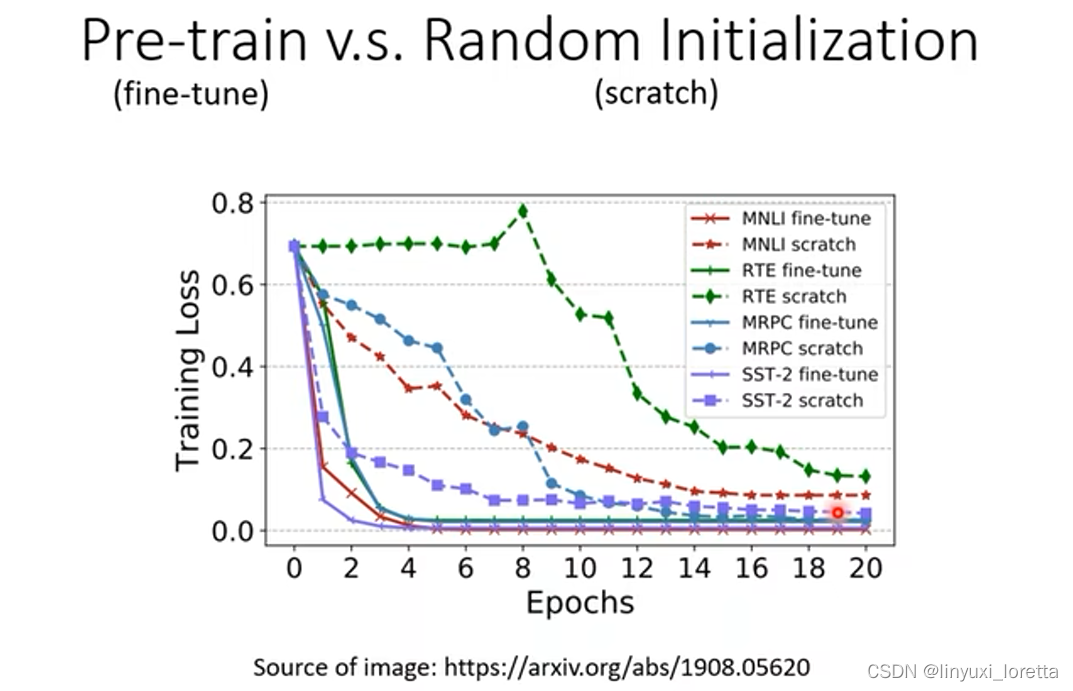
预训练是无监督学习,用了大量无标注的资料,而下游任务中,使用了少量有标注的资料,所以pre-train + fine-tune合起来,是semi-supervised learning,即半监督学习;
例子2:
输入和输出是长度一样的sequence,如词性标注任务;如下图所示,将每一个输入token对应的输出向量,每个向量分别做linear transform,过softmax,输出类别,

例子3:
输入两个句子,输出一个class;如自然语言推理(NLI)任务,输入一个“前提”、一个“假设”,判断二者关系,输出 矛盾/蕴含/中性;应用在如“立场分析”任务,判断留言是赞成文章还是反对文章,输入是文章和留言;

bert如何解上图中的任务?

例子4:
问答系统,给机器读一篇文章,问它一个问题,机器给你一个答案(我们假设答案一定在文章里面),输入两个sequence,文章和问题,输出两个正整数(s, e),代表文章里第s~e个字是答案;
这个听起来非常狂,但其实是今天非常标注的做法,5、6年前第一次听到实在不可置信。

做法如下图,这整个任务里,唯一需要从头开始训练,即random initialized的东西只有两个向量,这两个向量的长度跟bert的输出是一模一样的,
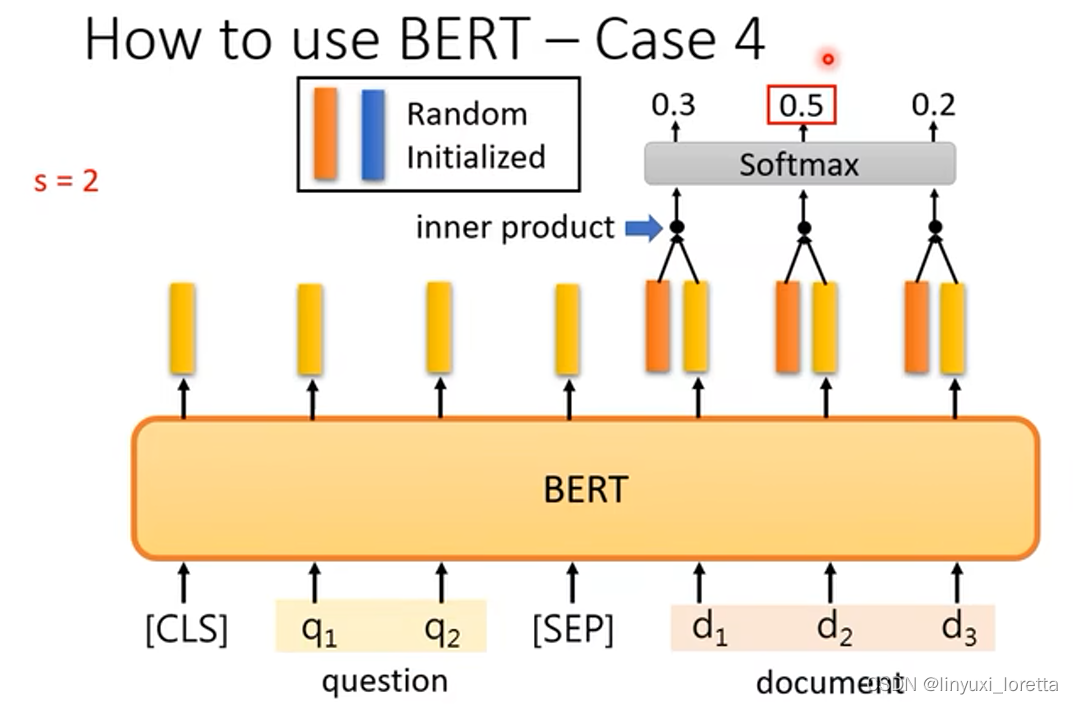

bert输入的长度有没有限制?理论上没有、但实际上有限制,因为self-attention的运算量非常很大,所以实作上bert输入的长度可能512就差不多了 ;训练时把文章截成一小段,
5、预训练seq2seq model
训练bert不是一般人能够训练的起来的,训练量太大了,需要的算力和资源太大,下图中用TPU v3训练100万次跑了8天:

如果我们自己训练一个bert,会有什么意义?有google现成的bert,而且这些预训练模型都是公开的。自己训练可以观察到bert在什么时候学会填什么样的词汇,填空能力到底是怎么增进的。具体可参考文献:https://arxiv.org/abs/2010.02480;
如何预训练一个seq2seq model?bert只有pre-train encoder,如何pre-train decoder呢?如下图,给encoder输入的句子做一些扰动(corrupted),然后希望decoder输出的句子 还原 弄坏前。

如何损坏输入的序列?有多种方法,见下图:

哪种“弄坏”的方法比较好?一篇Google的paper T5 已经讨论了这个问题:
你可以想的到的组合都做过了,长达67页
这篇文章试过了各式各样pre-train的方法

T5训练在C4 data set上,C4是个公开资料集 原始档案有7t
6、为什么bert有用
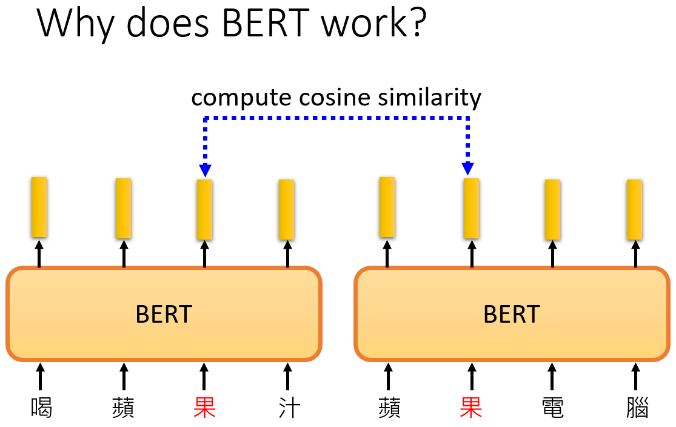
常见的解释是:输入一段文字,每一个文字都对应一个输出的向量,这些向量称为embedding,这些向量代表输入的字的意思,即:假设把这些字对应的向量画出来,算距离,你会发现意思越接近的字,他们对应的向量距离越近;字有一字多义,bert有考虑上下文,所以同一个字上下文不同,向量(embedding)是不一样的:

假设现在考虑“果”这个字,计算embedding之间的余弦相似度:
得到的计算结果如下图,十个“果”,两两计算相似度,得到10*10的矩阵,越偏黄表示值越大,bert知道前五个和后五个“果”意思不一样。

我们也许可以说,bert在训练做填空题的过程中,他学会了每个中文字的意思,所以可能能够在接下来的任务中做的更好,

bert为什么有这样神奇的能力?1960年代的语言学家:一个词汇的意思取决于他的上下文,bert在做填空题的过程中,也许他在学的就是从上下文抽取资讯,来预测被盖住的字,
这样的想法在bert之前就有了,过去有个技术word embedding中的CBOW技术(只用了两个linear transform)做的事情就是填空题,16年时候训练非常大的模型还是有困难的,
-BERT可以认为是deep版CBOW。bert能够考虑到上下文,所以抽出来的embedding也被叫做contextualized word embedding。
另一种解释是:把训练在文字上的bert用于蛋白质、DNA、音乐的分类,以DNA为例:

把bert用于DNA分类上,将ATCG分别对应到一个英文词汇(词汇随意选取),丢到bert里面,如下:
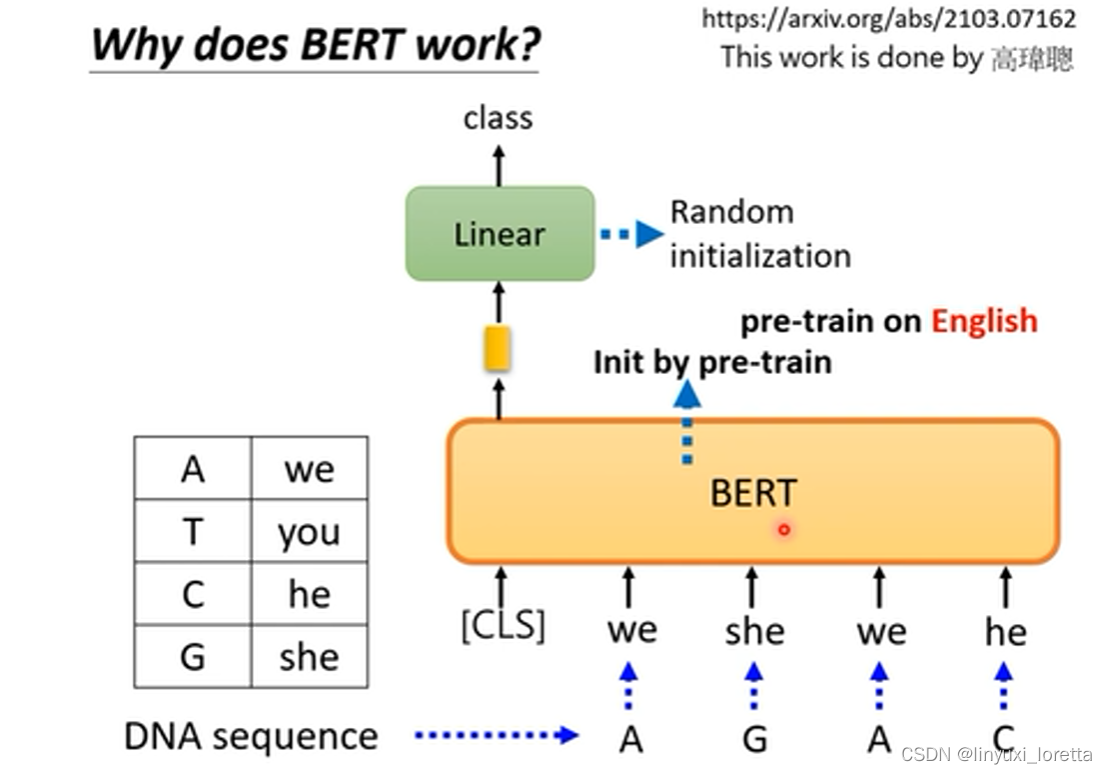
测试结果如下图,用bert是有一定效果的:
这个神奇的实验,bert为什么在该任务上能够运作起来,目前没有特别好的解释
bert为什么会好,还有很大研究的空间。
我们可以非常明显的从embedding里观察到他确实知道每个词汇的意思,但给他乱七八糟的句子,居然还可以分类的比较好,所以 他的能力也许不完全来自于看的懂文章,而是可能有其他的理由
也许bert本质上就是一个比较好的初始化参数、不见得跟语义有关,这组初始化参数就是特别适合拿来做大型模型的训练,

To learn more...
BERT(part1) https://youtu.be/1_gRK9EIQpc
BERT(part2) https://youtu.be/Bywo7m6ySlk
7、Multi-lingual BERT(多语言BERT)
用多语言训练的得到的bert模型,google用104种语言训练了一个Multi-BERT模型,神奇的地方是,用英文的QA资料做训练,它自动就会学做中文的QA任务:

一个真实的实验如下图:

如何解释这种现象?一个比较简单的解释是,对multi-BERT而言,不同语言间没有什么差异,只要embedding意思一样,就很接近,如兔子和rabbit的embedding很近,也许他在看过大量语言的过程中自动学会了这件事。

下面实验验证:
MRR越高表示两个不同语言的embedding他们aligned越好,aligned好是指 同样意思不同语言的字他们的向量越接近。
蓝色是Google做的结果,代表是不同语言对他来说没有什么不一样,他只看意思。
李老师的团队自己也跑了一个multi-bert,每种语言有200k个资料,资料算很少。但是alignment比较差;于是他们想试试是不是资料量不够引起的,于是资料量增加了五倍,八张v100跑了两天,当快要放弃时,loss才掉下去,bert的性能才进一步变好了,而alignment的结果也变好了,如下图:
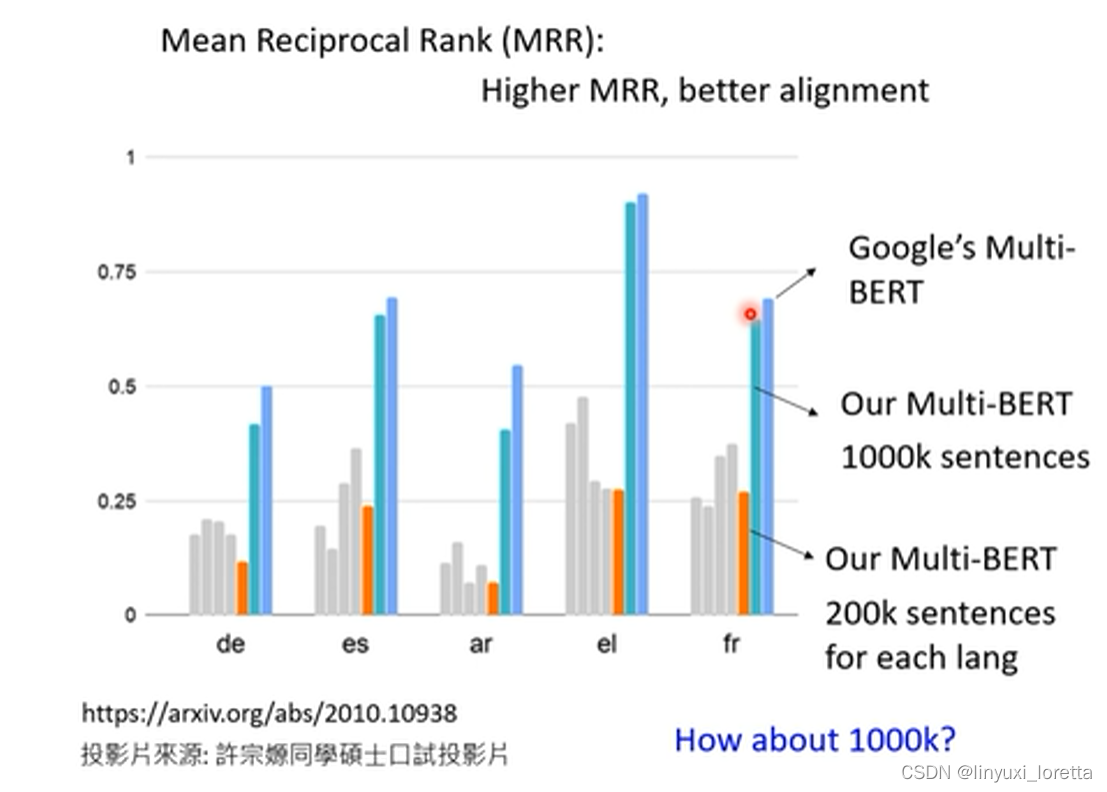

所以资料量是能把不同语言align在一起的非常关键的因素!很多现象要在足够资料量时才会显现出来。过去都没人说过 “英文QA数据训练,完成中文QA任务”,可能是资料量不够多、大量的运算资料、硬做下去,这种现象才会被观察到。
最后,再介绍一个神奇的实验:你不觉得整件事还是怪怪的吗,你说bert 可以把不同语言同样意思的符号让他们的向量接近,可是训练时,明明是给英文做英文填空,不会混在一起,如果对他来说不同语言没有差别,为什么他不在英文填空里填中文,bert应该是知道中英文之间的差异的,他知道语言的资讯,所以 语言的资讯到底在哪里?
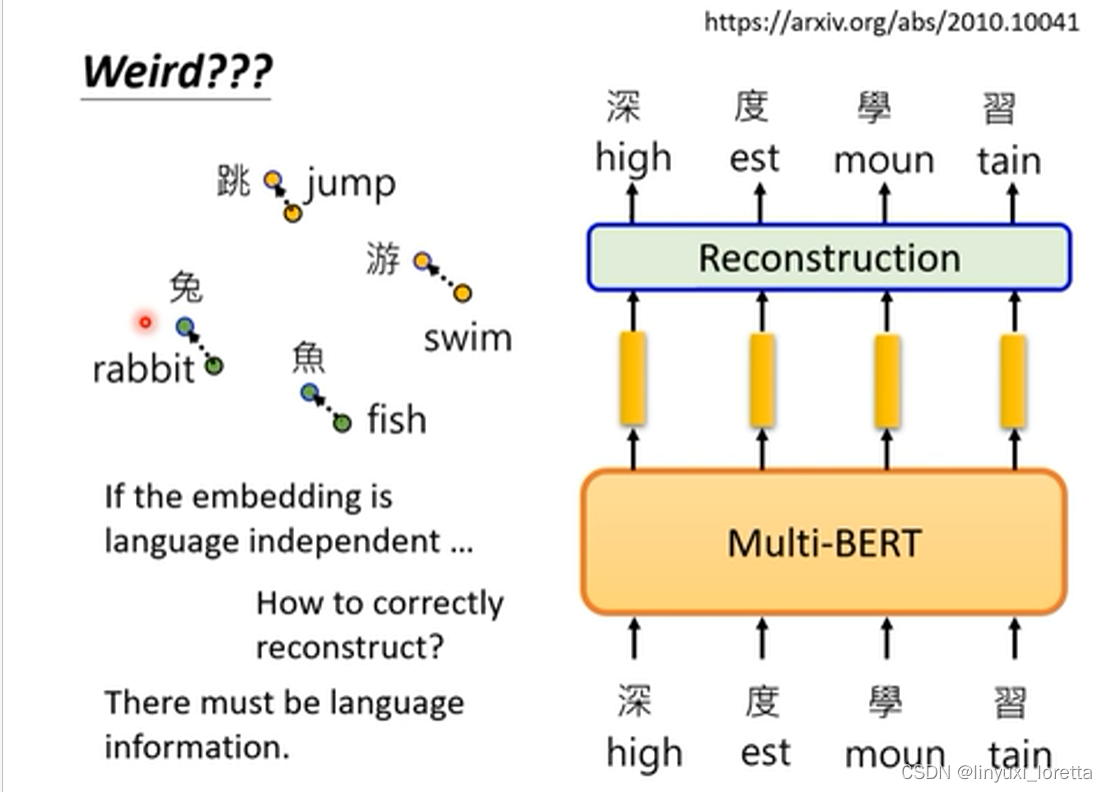

于是李宏毅团队做了如下图的实验:计算中文embedding的平均值,英文embedding的平均值,蓝色向量表示两个平均值之间的距离,加到bert的输出embedding上,Bert就会觉得它读到的是中文的句子,让它做填空题,把embedding变回句子以后,是英文所对应的正确的中文形式,非常神奇:

四、GPT 系列
open AI发表的

GPT的任务是:预测下一个token,所以它有生成的能力
BOS begin of sentence
- GPT架构像是transformer的decoder,不过要拿掉cross attention部分。也就是说你会做mask attention


最大的GPT模型不是public available的、
有人把一个比较小的GPT模型放在线上。 可以输入一个句子,补完接下去的内容

-GPT也可以和BERT一样,把输出接上一个简单的linear部分然后做下游任务,但GPT论文不是这么做的
-有可能的原因是GPT实在是太大了,连fine-tun都不好做
Bert也是要train的model的一部分,参数也是要调的。

-GPT更倾向于进行Few-shot Learning、One-shot Learning甚至Zero-shot Learning
-“In-context” Learning代表不是一般的learning,梯度下降都没做,不对GPT的参数进行更新
GPT系列到底有没有达成这个目标?见仁见智。相较于可以微调模型,正确率有点低

加减法 学会了,跟逻辑推理有关的任务 怎么都学不会
to learn more... https://youtu.be/DOG1L9lvsDY
(选修)To Learn More - 來自獵人暗黑大陸的模型 GPT-3_哔哩哔哩_bilibili
GPT-3 的神奇之处
接下来就讲 GPT-3 的几个神奇之处。
首先,它可以做 Closed Book QA。在 question answering 中,有一个 knowledge source,有一个 question,然后要找出 answer。如果机器在回答问题的时候可以看 knowledge source,就是 open book QA,而 Closed Book QA 则是没有 knowledge source,直接问一个问题看看能不能得到答案。比如直接问你,喜马拉雅山有多高,看机器的参数里面会不会有喜马拉雅山高度的资讯,会不会不需要读任何文章,它就知道喜马拉雅山的高度是 8848 公尺。
而 GPT-3 的表现如图。神奇的事情是, Few-shot Learning 居然超过了在 TriviaQA 上 fine-tune 最好的 SOTA model。
所以,在这里,巨大的 model 展现了奇迹。如果是只有 13 个 billion,没有办法超越 SOTA,但约 10 倍大,达到 175 个 billion,可以超越 SOTA。
左图是 SuperGLUE 的部分,随着的参数量越来越多,performance 当然越来越好。如果看最大的 model 的话,它可以超越 Fine-tuned BERT Large model。
右图显示,在做 Few-shot Learning 时,training example 对 performance 所造成的影响。
如果没有给任何 example,也就是 Zero-shot Learning,当然有点差。但随着 example 越来越多,如果只给 1-4 个,那与 Fine-tuned BERT 的 performance 差不多;如果给到 32 个,就可以超越 Fine-tuned BERT。
GPT-3 是一个 language model,所以它可以生成文本。在 GPT-3 论文中,作者群也用 GPT-3 来产生文章。他们给 GPT-3 新闻的标题,然后希望 GPT-3 自己把新闻写出来。
有一个神奇的小发现是:如果不给 GPT-3 任何 example,只给它一则新闻的标题,它会以为这则新闻的标题是推特的一句话,然后接下来它就会自己去回应。
所以在做generation的时候,GPT-3 不会是 Zero-shot 的,你需要给它几个 example,告诉它有一个标题,下面会接一篇新闻,然后接下来再给他一个标题,希望它可以根据这个标题阐述。
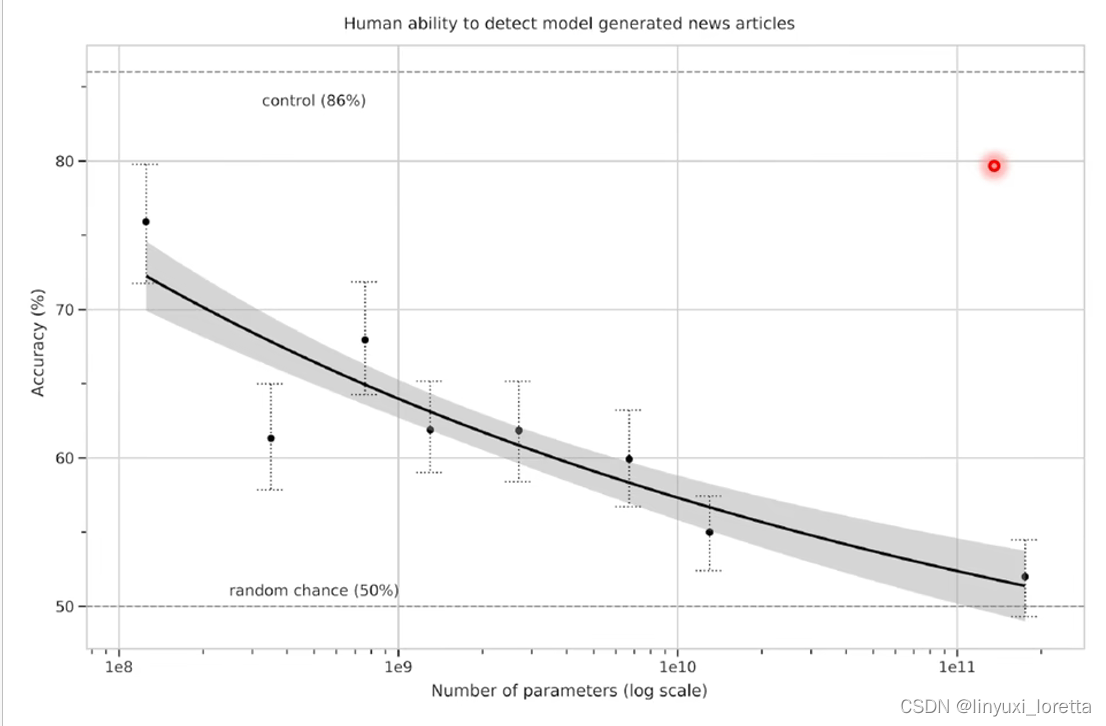
在上图,纵轴代表的是,给人看 GPT-3 产生的新闻与真正的新闻,人能不能够判断这篇新闻的真假。如果人的正确率只有 50%,就代表 GPT-3 产生出来的新闻太过真实,真实到人类没法判断。最大的 GPT-3 几乎可以骗过人类,
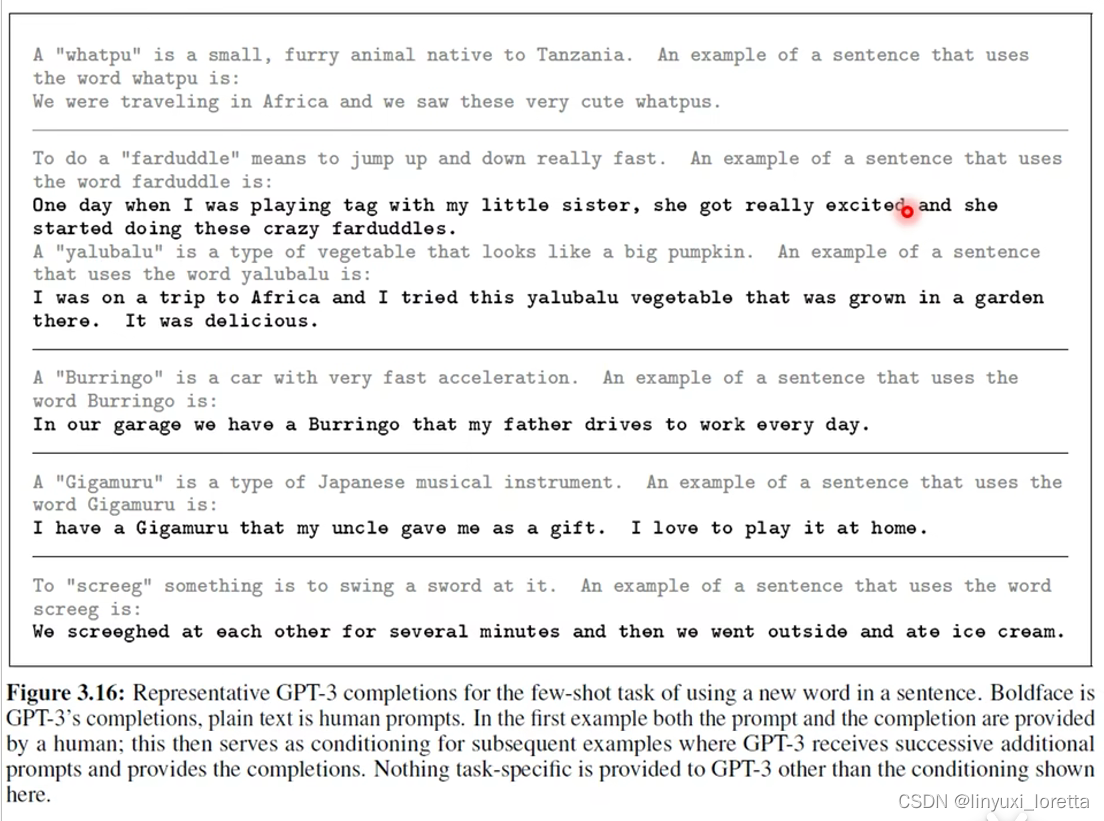
GPT-3 还学会了造句。上图中,浅灰色的文字是人的输入,黑色的文字是 GPT-3 的输出。
你先告诉 GPT-3 要怎么造句,造句是怎么一回事,先给一个词汇的定义。比如,有一个东西叫做 “whatpu”,“whatpu” 是什么,“whatpu” 是一个小的毛茸茸的动物。接下来,以 “whatpu” 为词汇造一个句子,。
再给一个胡乱创造的词汇,这个词汇叫做 “Burringo”,是一种跑得很快的车。要 GPT-3 用 “Burringo” 造一个句子,它知道 Burringo 是一个可以开的东西。
再比如,有一个东西叫做 “Gigamuru”,它是日本的乐器。GPT-3 知道 Gigamuru 是一个可以弹的东西。
或者有一个动词 “screeg”,它是挥剑的意思。此时,GPT-3 造出来的句子有些奇怪了,它说我们对彼此挥剑(它知道要加 ed),然后我们就去吃 ice cream,乍一看有点前言不对后语,彼此挥剑感觉应该是敌人,怎么接下来就是吃 ice cream?如果你把 screeg 想成是一种小孩的游戏,小朋友对彼此挥剑之后,接下来去吃冰淇淋,听起来也是合理的。
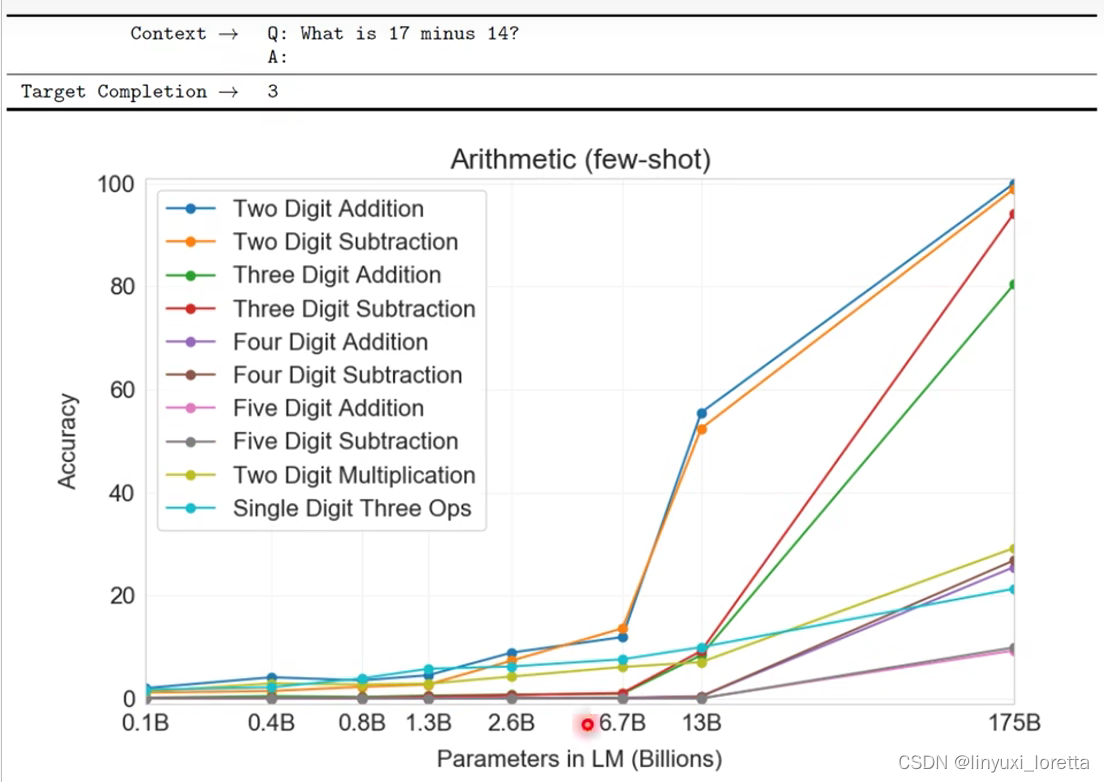
再来看 GPT-3 学会做数学问题。如何让它做数学问题呢?你就问 “What is 17 minus 14?”,然后给它 “A:”,它自动回答 “3”。它居然会算数学。
GPT-3 的数学水平可以做到什么程度?如果看这些参数量最多的模型,你会发现,基本上在两位数的加法跟两位数的减法上,可以得到不错的几乎 100% 的正确率。三位数的减法也做得不错,也不知道为什么三位数的加法就稍微差一点。
其他更困难的问题 ——4 位数、5 位数的加法,对它来说就比较困难,但至少它学会了二位数跟三位数的加减法(三位数不算完全学会)。
GPT-3 的 “不神奇” 之处
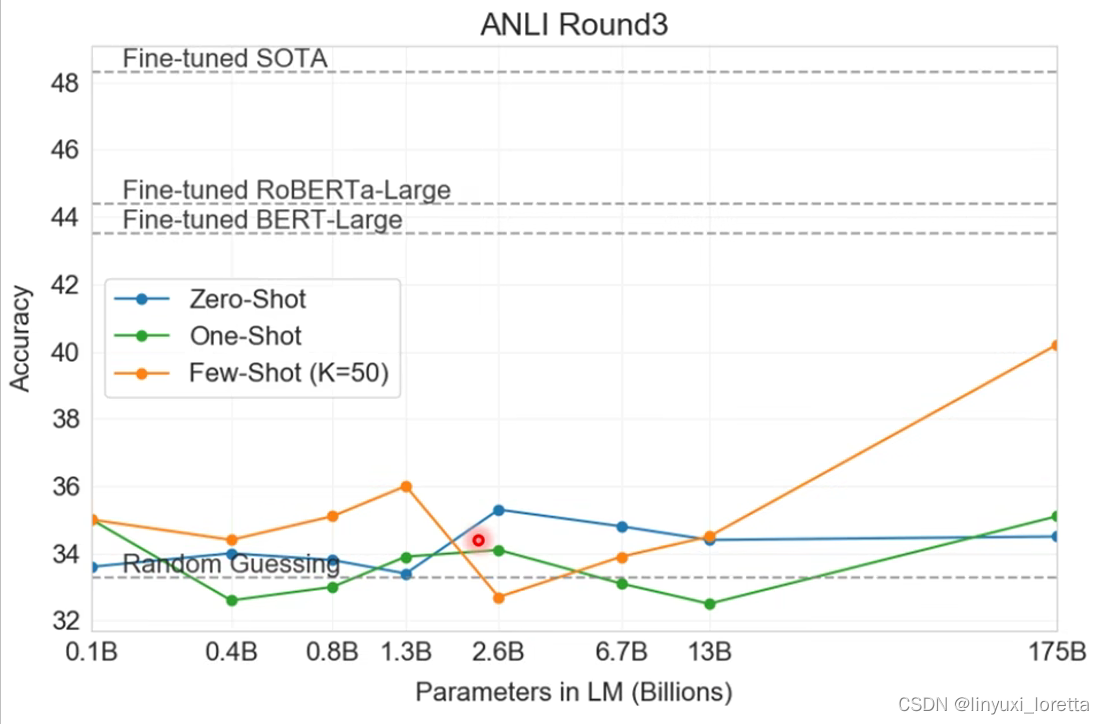
从文章里面看,GPT-3 在做 NLI 问题的时候不太行。
所谓 NLI 的问题,即给机器两个句子,要求机器判断这两个句子是矛盾的,还是互相包含,还是中立的关系。
就算是最大的模型,在 Zero-Shot 跟 One-Shot 上,基本都是惨的。只有 Few-Shot Learning,给模型 50 个 example 的时候,看起来是有一些希望,
所以, NLI 问题对 GPT-3 来说还是有些困难。
不过,GPT-3 是一个巨大的 language model,它在学习的过程中从来没有看过什么 NLI 问题,只知道 predict 下一个词汇而已。
也许因为在做 NLI 任务的时候,我们放在一起的两个句子很多时候是奇怪和矛盾的句子,两个矛盾的句子放在一起,这种情况本身在人类文字中出现的次数是很少,所以,GPT 系列看到这种接在一起但是矛盾的句子,它会觉得有些困惑。
接下来发生了一件有趣的事情。今天我们在训练这种巨大的 model 时,资料往往来自于网络,而网络上爬下来的资料,有可能就包含了我们现在的 testing data。
本来 OpenAI 在做这个实验的时候,他们就想要尽量避免训练数据中杂了 downstream task 的数据。但是他们在写的时候有一个 bug,所以没有成功实现这一点。但是 GPT-3 太大了,虽然有一个 bug,但没办法重新训练,只能够就这样了。
虽然没有办法重新训练,那我们就改一下 testing data。所以他们把 downstream task data 分成 clean data 和 dirty data。
clean data,即 GPT-3 在训练的时候,没有接触到的 data。dirty data,即 GPT-3 在训练的时候接触过的 data。如果这些点在这一个水平线之下的话,就代表有看到 dirty data 的 performance 比较好,在水平线之上,就代表给 GPT-3 只看 clean data 的 performance 比较好,也就是说,有一些混杂的资料对它来说也没占到什么便宜。如图我们发现,多数任务都集中在这条水平线上,即训练数据有没有被污染,有没有混杂到 downstream task 的数据,对 GPT-3 来说也许影响并没有那么大,所以有一个 bug 就算了。
超大规模的 model,语言水平究竟如何?
有一个比赛叫做 Turing Advice Challenge。它跟 GPT-3 没有什么直接关系了,只是想知道 这么多巨大的 model,好像都理解人类的语言,那它们可以像人类一样知道怎么使用这些语言吗?而 这个比赛,就是要机器去 reddit 上给人类意见。reddit 上会有很多 po文,举例来说,有人会抛一些感情上的问题。这个 po文 是放在 Turing Advice Challenge paper 里面的例子。
对机器而言,要给出像样的建议不太容易。
那么,机器怎么学会给建议呢?你训练一个 model,这个 model “吃” 下 reddit 上的一个 po文,然后它会想办法去模仿 po文 下面的回复。
这个比赛提供了 600k 训练数据,也就是 600k 个 reddit 上的 po文 及 回应,
这里以 T5 当作例子,那个时候还没有 GPT-3。T5 答案 不知所云,看起来是合理的句子,看起来像在讲些什么,但实际上没有什么作用。今天,这些巨大的 language model,它往往能得到的表现就是样子。
上图是一些真正的实验结果。在 Turing Advice Challenge 中,拿了包括 Grover、T5 等各式各样的模型。拿reddit上大家公认最好的建议和这些model产生的建议做比较,
结果是,就算是 T5,人们也只有在 9% 的情况下,才觉得 T5 提出来的建议比人提出来的建议有效。
如果现在比较 reddit 上评分第一高的建议与第二高的建议,其实评分第二高的建议还有 40% 的人是觉得有用的,但 T5 只有 9% 的人是觉得有用。
这说明了,用这种巨大的 language model 来让机器使用语言,来产生文字,和人类对语言使用的能力仍相差甚远。
GPT用在影像上
raster order 一行一行的把影像产生出来,
直接用GPT,都没调network架构,直接把pixel当作文字硬train下去就结束了








self-supervised learning技术 全景图

-BERT、GPT系列只是self-supervised learning三个类型中的prediction,
SimCLR 非常有名

BYOL很奇怪,根本不知道他为什么work,这个想法感觉有巨大的瑕疵,而且还曾经一度得到state of the art的结果


语言版的Bert、GPT都已经有很多研究成果了
不过语言上相较于文字处理上 还是有一些很缺乏的东西,缺乏 如 GLUE 这样 基准的资料库

语言技术 其实有非常多不同的面向,语音转文字、语音包含非常多的资讯,内容、语者、语气、这句话背后的语义,...
我们有个toolkit 包含各式各样self-supervised模型,还有这些模型可以做的各式各样的语音下游任务